Health Scoring dengan AI untuk Pelanggan SaaS

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hampir setiap perusahaan SaaS di Series B ke atas memiliki customer health score. Tanyakan kepada CSM (customer success manager) apakah mereka mempercayainya, dan sebagian besar akan mengatakan mereka memeriksanya ketika perlu membenarkan sesuatu kepada manajer mereka, kemudian kembali ke insting mereka.
Itulah mode kegagalan dari health scoring berbasis aturan. Bukan karena konsepnya salah. Melainkan karena aturan yang diterapkan secara seragam ke semua akun, dengan bobot yang ditetapkan oleh komite daripada diturunkan dari hasil churn aktual, menghasilkan skor yang secara teknis terisi tapi secara praktis tidak berguna.
AI health scoring berbeda. Bukan karena AI itu ajaib, tapi karena modelnya dilatih pada apa yang sebenarnya terjadi pada akun seperti ini, bukan pada perkiraan product manager tentang apa yang akan penting.
Health Scoring Berbasis Aturan vs. AI
Health score berbasis aturan biasanya terlihat seperti ini: jika NPS (net promoter score) di atas 8 dan frekuensi login di atas empat kali per minggu dan akun telah merespons tiga email CSM terakhir, nilai hijau. Jika tidak, kuning. Jika mereka mengajukan permintaan pembatalan, merah.
Pendekatan ini memiliki dua masalah.
Key Facts: AI Health Scoring untuk SaaS
- Perusahaan yang mengimplementasikan model CS berbasis pengecualian (di mana AI menandai akun berisiko dan CSM hanya menangani akun yang ditandai) melaporkan tingkat retensi 25-40% lebih tinggi dan ROI 3-5x pada headcount customer success vs. pemantauan manual (Benchmarkit 2025 SaaS Performance Metrics)
- Model churn AI yang dilatih pada 80+ sinyal perilaku mencapai akurasi prediksi 75-82%; peningkatan akurasi terbesar 2025-2026 berasal dari penambahan embedding sentimen berbasis LLM yang mendeteksi frasa seperti "kami sedang mengevaluasi opsi" sebagai 4-6x lebih mungkin untuk churn dalam 90 hari (Arete SaaS Research, 2025)
- 70% perusahaan SaaS percaya AI sangat penting untuk strategi retensi mereka, dan pasar telah melampaui fase pilot menuju implementasi CS AI skala penuh, menjadikan AI health scoring sebagai baseline operasional dalam 18 bulan (riset customer churn EverAfter, 2025)
Pertama, bobotnya arbitrer. Seseorang memutuskan bahwa NPS bernilai 30 poin dan frekuensi login bernilai 20 poin. Bobot-bobot tersebut tidak diturunkan dari riwayat churn apa pun. Mereka mencerminkan keyakinan tim tentang apa yang penting, yang mungkin atau mungkin tidak sesuai dengan kenyataan.
Kedua, aturan memperlakukan semua akun sama. Akun enterprise dengan 500 pengguna yang login dua kali seminggu mungkin sangat tertanam dalam produk Anda sebagai tools workflow harian. Startup dengan 10 pengguna yang login setiap hari mungkin sedang mengevaluasi produk Anda dibandingkan kompetitor. Sinyal mentah terlihat berlawanan dengan risiko yang sebenarnya.
AI health scoring dilatih pada riwayat churn aktual Anda. Model belajar sinyal mana, dalam kombinasi mana, pada akun mana, mendahului hasil churn. Bobotnya diturunkan dari data, bukan dari pendapat internal tentang apa yang seharusnya penting. Riset tentang pemodelan perilaku untuk prediksi churn mengonfirmasi bahwa sinyal pola penggunaan yang dilatih pada hasil aktual mengungguli threshold berbasis aturan, dengan akurasi model meningkat secara signifikan seiring bertumbuhnya set pelatihan.
Hasilnya adalah skor yang dapat benar-benar diinterogasi CSM: bukan hanya flag hijau atau merah, tapi kode alasan yang mengatakan "sentimen tiket support akun ini telah memburuk selama 45 hari terakhir, dan secara historis pattern tersebut pada akun dengan ukuran serupa mendahului churn 68% dari waktu."
Mekanisme yang memungkinkan ini adalah Anomaly Agent yang berjalan terus-menerus di bawah skor.
Anomaly Agent Pattern di Baliknya
Cara yang tepat untuk memikirkan AI health scoring dalam ACE Framework adalah sebagai Anomaly Agent yang berkelanjutan. Model tidak menilai akun sekali sebulan dan memperbarui dashboard. Ia Ingest aliran sinyal yang terus-menerus, menetapkan baseline untuk perilaku normal di setiap akun, dan menandai ketika perilaku menyimpang dari baseline tersebut dengan cara yang secara historis berkorelasi dengan risiko churn.
Anomaly Agent pattern berjalan: Ingest (sinyal berkelanjutan) kemudian Analyze (penyimpangan dari baseline spesifik akun) kemudian Predict (perubahan risiko churn) kemudian Execute (memicu workflow atau alert). Ini berbeda dari alert berbasis threshold karena baseline-nya spesifik akun. Penurunan 20% dalam frekuensi login pada akun yang biasanya memiliki keterlibatan harian tinggi adalah sinyal yang lebih kuat dibanding penurunan yang sama pada akun yang selalu memiliki frekuensi rendah.
Kekhususan akun itulah yang membuat AI health scoring lebih akurat dari aturan. Dan itulah yang membuatnya lebih sulit diimplementasikan: Anda membutuhkan data historis yang cukup per jenis akun untuk menetapkan baseline yang bermakna.
Sinyal yang Anda masukkan ke dalam model tersebut menentukan seberapa akurat dan dapat ditindaklanjutinya output tersebut.
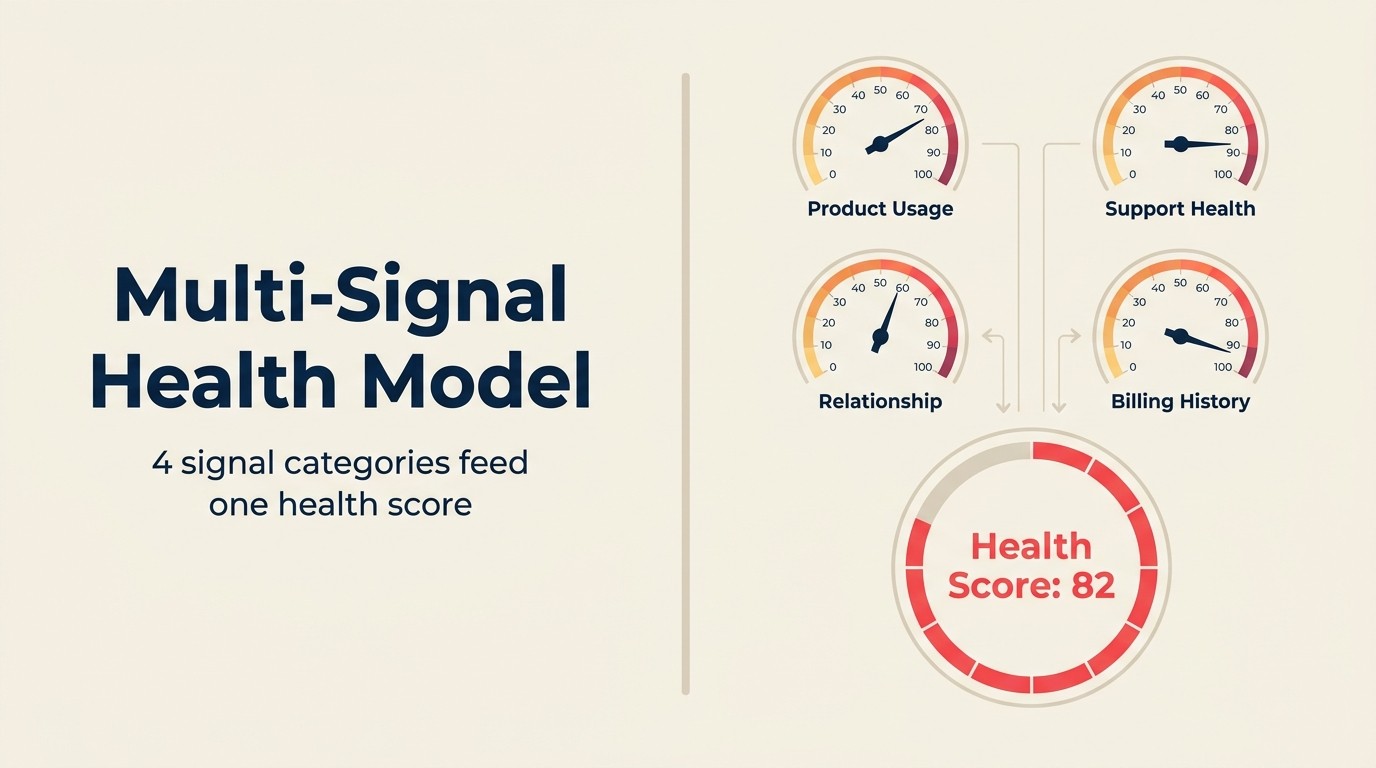
The Multi-Signal Health Model
The Multi-Signal Health Model adalah framework untuk AI health scoring yang menghasilkan skor yang benar-benar dipercaya CSM: gabungkan sinyal penggunaan (tren perilaku produk relatif terhadap baseline spesifik akun), sinyal hubungan (sentimen panggilan, tingkat respons CSM, stabilitas champion), sinyal komersial (timing faktur, utilisasi kontrak, kesesuaian tier harga), dan sinyal sentimen support (tren volume tiket, tingkat eskalasi, kepuasan) ke dalam skor komposit dengan kode alasan yang terlihat. Setiap kategori sinyal berkontribusi secara independen dan bobotnya diturunkan dari hasil churn aktual dalam riwayat akun Anda, bukan dari asumsi komite. Model berjalan sebagai Anomaly Agent yang berkelanjutan: mendeteksi penyimpangan dari baseline spesifik akun secara real time daripada mengkalkulasi ulang skor dashboard mingguan. Uji praktis dari Multi-Signal Health Model yang baik: CSM harus dapat membaca kode alasan dan langsung memahami mengapa akun berubah warna dan tindakan apa yang harus diambil.
Kategori Sinyal dan Apa yang Sebenarnya Diprediksinya
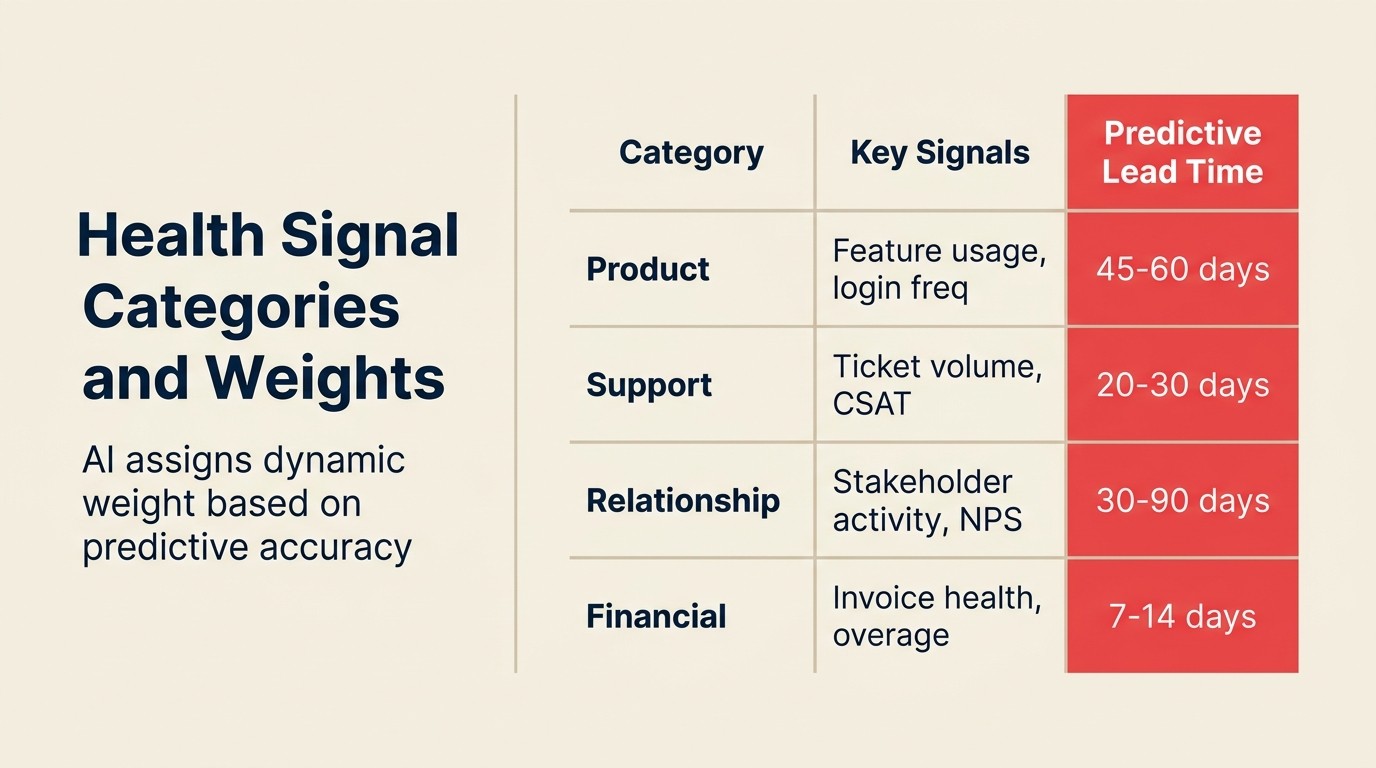
Tidak semua sinyal memiliki bobot yang sama, dan bobotnya bervariasi berdasarkan jenis produk dan segmen pelanggan. Berikut cara memikirkan empat kategori utama.
Sinyal penggunaan produk. Untuk perusahaan PLG (Product-Led Growth) dan tools di mana penggunaan aktif harian diharapkan, sinyal ini membawa bobot tertinggi. Frekuensi login, keluasan adopsi fitur, workflow aktif, tren volume panggilan API, dan indikator kolaborasi (jumlah rekan tim yang aktif) adalah input terkuat. Kuncinya adalah tren, bukan level absolut. Akun yang telah mengalami penurunan penggunaan selama 60 hari memiliki risiko lebih tinggi dari akun pada level penggunaan absolut yang sama yang datar.
Sinyal kualitas hubungan. Ini paling penting untuk akun enterprise high-touch. Frekuensi panggilan, tingkat respons CSM, penyelesaian QBR, skor NPS, dan sentimen dari transkrip panggilan. Jika champion telah diam, itu adalah sinyal. Jika panggilan CSM terus-menerus dijadwal ulang, itu adalah sinyal. Meeting Intelligence (dari ACE Framework) dapat menganalisis rekaman panggilan untuk menilai sentimen dari waktu ke waktu dan menandai ketika nada telah bergeser dari terlibat ke transaksional.
Sinyal kesehatan komersial. Timing pembayaran faktur, penggunaan relatif terhadap batas kontrak, jumlah tiket support yang mempertanyakan ketentuan harga atau kontrak, dan inisiasi percakapan renewal. Ini adalah sinyal lagging daripada indikator leading, tapi presisinya tinggi: akun yang mulai mempertanyakan item baris dalam faktur jauh lebih mungkin untuk churn daripada akun yang membayar tepat waktu.
Sinyal sentimen support. Tren volume tiket, tingkat eskalasi, nada teks tiket terbuka, penilaian kepuasan time-to-resolution, dan apakah tiket tentang masalah produk atau tentang menginginkan pengembalian uang atau pembatalan. Peningkatan cepat dalam tiket support yang dikombinasikan dengan penilaian kepuasan rendah adalah salah satu prediktor churn jangka pendek terkuat.
Tapi Anda hanya dapat menggunakan sinyal-sinyal ini jika Anda memiliki data pelatihan untuk mengkalibrasinya terhadap riwayat churn Anda sendiri.
Membangun Set Pelatihan
Di sinilah sebagian besar tim terhenti: AI health scoring membutuhkan data historis untuk dilatih, dan bukan hanya data apa pun.
Untuk melatih model prediksi churn yang bermakna, Anda biasanya membutuhkan 2 hingga 3 tahun riwayat akun dan setidaknya 100 akun yang churn dalam set pelatihan. Model perlu belajar bagaimana tampilan churn di seluruh jenis akun, ukuran, dan pola penggunaan produk. Jika basis churn Anda terlalu kecil atau terlalu homogen, model akan overfit dan tidak akan digeneralisasikan dengan baik ke akun dalam portofolio Anda saat ini. Benchmark retensi SaaS ChartMogul menyediakan baseline industri yang berguna tentang seperti apa tingkat churn pada berbagai tahap ARR (annual recurring revenue), yang dapat melengkapi data historis Anda sendiri ketika set pelatihan Anda masih berkembang.
Jika Anda belum memiliki data tersebut, langkah yang tepat bukanlah melewatkan AI health scoring. Ini adalah memulai dengan scoring berbasis aturan yang dirancang dengan baik sekarang, mencatat setiap sinyal yang Anda lacak, dan mulai membangun set data pelatihan secara sistematis. Dokumentasikan kapan akun churn dan bagaimana tampilan riwayat sinyal mereka selama 90 hari sebelumnya. Dalam 18 bulan, Anda akan memiliki data untuk membuat transisi ke scoring berbasis AI menjadi bermakna.
AI health scoring Gainsight bekerja dengan cara ini: dapat dimulai dengan data benchmark Gainsight sendiri (diturunkan dari pola churn di seluruh basis pelanggan mereka) dan kemudian secara progresif beradaptasi dengan pola historis spesifik Anda seiring data tersebut terakumulasi. Planhat mengambil pendekatan model-data di mana Anda mendefinisikan arsitektur sinyal dan model dilatih pada riwayat akun Anda sendiri. ChurnZero menggunakan scoring berbasis benchmark yang membandingkan akun Anda terhadap benchmark industri untuk tahap perusahaan yang serupa, yang berguna ketika Anda belum memiliki cukup riwayat churn sendiri.
Bahkan model yang terlatih dengan baik menciptakan masalah jika skor itu sendiri menghasilkan kepercayaan diri yang salah.
Masalah Kepercayaan Diri Palsu
Health score yang memprediksi hijau pada akun yang kemudian churn lebih buruk dari tidak ada skor sama sekali. Ini memberikan kepercayaan diri yang salah kepada CSM (dan kepemimpinan CS), yang mengarah pada under-investasi dalam akun berisiko selama jendela ketika intervensi masih bisa berhasil.
Metrik yang harus dilacak adalah presisi pada klasifikasi merah: ketika model mengatakan merah, seberapa sering itu benar? Model yang menandai 100 akun merah dan 80 di antaranya benar-benar churn (presisi 80%) jauh lebih dapat ditindaklanjuti dari model yang menandai 100 akun merah dan 40 di antaranya churn.
Ada tradeoff di sini. Presisi tinggi pada flag merah berarti Anda hanya membunyikan alarm ketika yakin, yang berarti beberapa akun yang sebenarnya berisiko tidak akan ditandai. Recall tinggi berarti menandai lebih banyak akun berisiko tapi juga menghasilkan lebih banyak false alarm yang melonjakan beban kerja CSM dan mengikis kepercayaan pada skor.
Untuk sebagian besar tim CS dengan kapasitas terbatas, presisi lebih penting dari recall. Sejumlah flag risiko tinggi yang benar-benar memprediksi churn lebih berguna dari daftar komprehensif di mana CSM tidak dapat membedakan sinyal nyata dari noise.
Uji model Anda secara teratur terhadap hasil aktual. Ambil kohort akun yang dinilai hijau enam bulan lalu. Berapa banyak yang churn? Ambil kohort yang dinilai merah. Berapa banyak yang diperbarui? Backtest ini memberi tahu Anda apakah model sebenarnya memprediksi hasil atau hanya mengukur perilaku lagging.
Akurasi model adalah prasyarat. Tapi membuat CSM bertindak berdasarkan skor adalah masalah yang lebih sulit.
Kepercayaan dan Adopsi CSM
Health score yang diabaikan CSM tidak memberikan nilai. Mendapatkan adopsi membutuhkan penyelesaian masalah kepercayaan, bukan masalah teknologi.
CSM tidak mempercayai health score karena tiga alasan spesifik. Pertama, skor mengatakan satu hal dan rasa hubungan mereka mengatakan hal lain, dan skor tidak pernah diperbarui ketika mereka mengajukan koreksi. Kedua, skor berubah tanpa penjelasan: akun beralih dari kuning ke merah semalam dan tidak ada kode alasan. Ketiga, ketika skor salah, itu membuang waktu mereka mengejar akun yang tidak membutuhkan perhatian.
Masing-masing dapat diselesaikan.
Buat kode alasan terlihat. Bukan hanya "merah karena penggunaan turun" tapi "frekuensi login akun ini turun 45% dalam 30 hari terakhir, dan akun dalam profil ini yang menunjukkan pola ini telah churn dalam 90 hari pada tingkat historis 72%." CSM yang dapat melihat bukti di balik skor akan terlibat dengannya daripada mengabaikannya diam-diam.
Bangun mekanisme override. CSM harus dapat menandai skor sebagai tidak akurat dan menambahkan kode alasan. Override tersebut menjadi data pelatihan. Jika CSM secara konsisten menandai akun penggunaan rendah sebagai hijau dan mereka secara konsisten diperbarui, model belajar bahwa penggunaan rendah pada jenis akun tersebut bukan sinyal churn.
Jalankan sesi kalibrasi kuartalan. Kumpulkan tim CS, tinjau akun di mana model benar dan di mana salah, dan diskusikan polanya. Ini membangun pemahaman bersama tentang apa yang dilakukan model dan membangun kepercayaan melalui transparansi.
Kepercayaan menghasilkan adopsi. Adopsi hanya penting jika skor mendorong tindakan.
Health Score sebagai Pemicu Workflow
Pergeseran mindset terpenting untuk health scoring adalah ini: skor bukan metrik dashboard. Ini adalah input workflow.
Transisi hijau-ke-kuning harus secara otomatis memicu task CSM: "Akun X telah beralih ke kuning. Tinjau data penggunaan dan jadwalkan check-in dalam 5 hari kerja." Transisi kuning-ke-merah harus memicu eskalasi: tinjauan CS lead, opsi outreach sponsor eksekutif, inisiasi save play.
Tanpa integrasi workflow tersebut, health score adalah angka dalam dashboard yang seseorang lihat sebelum rapat dewan. Dengan itu, setiap sinyal risiko menghasilkan tindakan.
Bangun save play terlebih dahulu, kemudian aktifkan pemicu health score. Kesalahan implementasi paling umum adalah mengaktifkan health scoring sebelum workflow respons ada, yang berarti ketika akun menjadi merah, tidak ada yang tahu apa yang harus dilakukan. Sistem mengidentifikasi risiko dengan benar dan kemudian tidak ada yang terjadi.
AI Churn Prediction dalam Model Subscription mencakup lapisan pemodelan prediktif lebih mendalam, termasuk prediksi tingkat kohort dan matematika komersial di balik timing intervensi.
Keunggulan Product Telemetry dalam AI SaaS mencakup mengapa perusahaan SaaS memiliki keunggulan data struktural untuk health scoring yang tidak dimiliki industri lain: produk itu sendiri menghasilkan sinyal paling prediktif secara real time.
Menghubungkan ke Stack CS yang Lebih Luas
Health scoring adalah fondasi. AI ekspansi (dibahas dalam artikel pendamping tentang upsell dan cross-sell) dibangun di atasnya. Anda perlu mengetahui akun itu sehat sebelum mendorong percakapan ekspansi. Akun yang kuning-ke-merah pada kesehatan tidak boleh menerima outreach ekspansi.
AI Customer Success Manager untuk B2B SaaS mencakup bagaimana health scoring terintegrasi dengan persiapan QBR, expansion play, dan otomasi workflow renewal sebagai sistem intelijen CS yang terhubung.
Seperti Apa Tampilan yang Baik
Implementasi AI health scoring yang matang di perusahaan SaaS dengan 200 akun enterprise akan terlihat seperti ini: setiap akun memiliki health score yang diperbarui setiap hari. Skor dilengkapi dengan tiga hingga lima kode alasan yang menjelaskan sinyal utama yang mendorongnya. CSM memiliki antrian transisi yang ditandai yang membutuhkan tindakan hari ini, minggu ini, dan bulan ini. Setiap interaksi save play dicatat kembali ke dalam sistem sebagai data pelatihan. Riset layanan pelanggan Gartner 2025 menunjukkan bahwa 85% pemimpin layanan pelanggan akan mempilotkan atau menerapkan AI pada 2025, menjadikan kematangan operasional dalam CS berbantuan AI sebagai baseline kompetitif, bukan diferensiator, dalam 18 bulan.
Dua kali setahun, tim CS Ops menjalankan backtest, membandingkan skor dari enam bulan sebelumnya terhadap hasil churn dan renewal aktual. Ketika presisi turun di bawah threshold yang disepakati, model dilatih ulang.
Peningkatan NRR (net revenue retention) dari sistem tersebut terukur: bukan karena skor itu ajaib, tapi karena memastikan tidak ada akun berisiko tinggi yang luput dari perhatian selama jendela 90 hari ketika outreach proaktif masih berhasil.
Bangun skor yang dipercaya CSM. Hubungkan ke workflow yang sebenarnya mereka gunakan. Kemudian ukur apakah itu memprediksi akun yang tepat. Semua yang lain adalah detail implementasi. Untuk konteks yang lebih luas tentang bagaimana AI membentuk kembali model operasi SaaS, lihat diskusi rasio CS-terhadap-ARR.
Menambahkan sinyal sentimen support ke model kesehatan, khususnya analisis berbasis LLM dari bahasa tiket support dan transkrip panggilan, secara konsisten menghasilkan peningkatan akurasi terbesar dalam deployment 2025-2026. Akun di mana pelanggan menggunakan frasa seperti "kami sedang mengevaluasi opsi" atau "kami tidak melihat ROI yang kami harapkan" 4-6x lebih mungkin untuk churn dalam 90 hari. Model penggunaan murni tidak dapat mendeteksi sinyal ini. Hanya model dengan akses data percakapan yang bisa. (Arete SaaS Research, 2025)
Rework Analysis: Kesalahan implementasi paling konsisten yang kami amati adalah membangun dashboard health scoring sebelum membangun workflow save play. Tim bersemangat tentang visualisasi kesehatan, mengaktifkan alert, dan kemudian tidak memiliki respons yang terdefinisi ketika akun berubah merah. CSM melihat alert, tidak yakin apa yang harus dilakukan, tidak melakukan apa-apa, dan akun churn. Sistem mengidentifikasi risiko dengan benar. Manusia tidak siap untuk bertindak. Urutan yang berhasil: rancang workflow save play terlebih dahulu (apa yang kita lakukan ketika kesehatan berubah merah?), uji secara manual dengan lima akun berisiko, kemudian aktifkan AI health alert untuk memicu workflow tersebut secara otomatis. Nilai sistem pada tingkat eksekusi save play, bukan pada volume alert.
| Kategori Sinyal | Bobot | Contoh | Lead Time Prediksi |
|---|---|---|---|
| Sinyal penggunaan produk | Tertinggi (untuk PLG dan tools penggunaan harian) | Tren frekuensi login, kedalaman adopsi fitur, volume panggilan API, keluasan kolaborasi | 3-8 minggu |
| Sinyal hubungan | Tertinggi untuk akun enterprise | Tren sentimen panggilan, tingkat respons CSM, penyelesaian QBR, stabilitas champion | 4-8 minggu |
| Sinyal komersial | Presisi tinggi tapi lagging | Timing pembayaran faktur, penggunaan vs. batas kontrak, inisiasi percakapan tier harga | 1-3 minggu |
| Sentimen support | Campuran (leading untuk frustrasi, lagging untuk pembatalan) | Tren volume tiket, penurunan CSAT, tingkat eskalasi, analisis bahasa tiket | 2-6 minggu |
Sumber: Gainsight, ChurnZero, Planhat, Arete SaaS Research (2024-2025)
Pertanyaan yang Sering Diajukan
Apa itu AI health scoring dan bagaimana perbedaannya dari scoring berbasis aturan?
AI health scoring dilatih pada riwayat churn aktual Anda untuk menurunkan bobot sinyal dari hasil daripada asumsi. Ia mendeteksi anomali relatif: penyimpangan dari baseline perilaku setiap akun sendiri, bukan threshold absolut yang diterapkan secara seragam. Skor berbasis aturan menandai akun mana pun dengan di bawah 5 login per minggu. AI health score menandai akun yang loginnya turun 40% dari rata-rata 90 hari mereka sendiri. Model AI juga menghasilkan kode alasan: "sentimen tiket support akun ini telah memburuk selama 45 hari, dan secara historis pola tersebut mendahului churn 68% dari waktu pada akun serupa."
Apa itu Multi-Signal Health Model?
Multi-Signal Health Model adalah framework untuk mengkomposisikan empat kategori sinyal ke dalam health score yang dapat dipercaya: sinyal penggunaan (perilaku produk relatif terhadap baseline spesifik akun), sinyal hubungan (sentimen panggilan, stabilitas champion, tingkat respons CSM), sinyal komersial (timing faktur, kesesuaian tier, utilisasi kontrak), dan sinyal sentimen support (tren volume tiket, analisis LLM dari bahasa tiket). Bobotnya diturunkan dari hasil churn aktual, bukan pendapat komite. Model berjalan sebagai Anomaly Agent berkelanjutan yang mendeteksi penyimpangan real-time.
Data pelatihan apa yang diperlukan AI health scoring?
Prediksi churn yang bermakna membutuhkan 2-3 tahun riwayat akun dan setidaknya 100 akun yang churn dalam set pelatihan. Jika data Anda tidak mencukupi, mulailah dengan scoring berbasis aturan yang dirancang dengan baik sekarang, catat semua sinyal secara sistematis, dan dokumentasikan riwayat sinyal untuk akun yang churn 90 hari sebelumnya. Dalam 18 bulan Anda akan memiliki data pelatihan yang dibutuhkan. Gainsight dapat bootstrap dari data benchmark di seluruh basis pelanggan mereka. Planhat menggunakan riwayat akun Anda sendiri. ChurnZero menggunakan benchmark industri untuk melengkapi data pelatihan yang terbatas.
Bagaimana cara membuat CSM mempercayai dan menggunakan health score?
Selesaikan tiga masalah kepercayaan spesifik. Buat kode alasan terlihat: bukan hanya "merah karena penggunaan turun" tapi pola spesifik dan tingkat historis churn pada akun serupa. Bangun mekanisme override: CSM dapat menandai skor yang tidak akurat dan menambahkan alasan, yang menjadi data pelatihan. Jalankan sesi kalibrasi kuartalan: tinjau akun di mana model benar dan salah sebagai tim. CSM yang dapat menginterogasi penalaran model akan terlibat dengannya. CSM yang hanya melihat warna yang tidak bisa mereka jelaskan akan mengabaikannya diam-diam.
Apa urutan implementasi yang benar untuk AI health scoring?
Rancang workflow save play terlebih dahulu (apa yang kita lakukan ketika kesehatan berubah merah?), uji secara manual dengan lima akun berisiko, kemudian aktifkan AI alert untuk memicu workflow tersebut secara otomatis. Ini mencegah kegagalan implementasi paling umum: tim membangun dashboard kesehatan, mengaktifkan alert, tidak memiliki respons yang terdefinisi, dan menyaksikan CSM melihat alert yang tidak mereka tindaklanjuti. Nilai sistem pada tingkat eksekusi save play, bukan volume alert.
Kategori sinyal mana yang menghasilkan peningkatan akurasi terbesar dalam model kesehatan?
Sinyal sentimen support, khususnya analisis berbasis LLM dari bahasa tiket support dan transkrip panggilan. Akun di mana pelanggan menggunakan frasa seperti "kami sedang mengevaluasi opsi" 4-6x lebih mungkin untuk churn dalam 90 hari. Model penggunaan murni tidak dapat mendeteksi ini. Perusahaan yang mengimplementasikan lapisan sinyal sentimen di atas model penggunaan melaporkan lompatan akurasi paling signifikan dalam deployment 2025-2026, karena bahasa percakapan adalah indikator leading yang mencerminkan keadaan keputusan pelanggan sebelum penurunan penggunaan apa pun terlihat.
Related:

Co-Founder, Rework.com
On this page
- Health Scoring Berbasis Aturan vs. AI
- Anomaly Agent Pattern di Baliknya
- The Multi-Signal Health Model
- Kategori Sinyal dan Apa yang Sebenarnya Diprediksinya
- Membangun Set Pelatihan
- Masalah Kepercayaan Diri Palsu
- Kepercayaan dan Adopsi CSM
- Health Score sebagai Pemicu Workflow
- Menghubungkan ke Stack CS yang Lebih Luas
- Seperti Apa Tampilan yang Baik