More in
Berita AI di Tempat Kerja
OpenAI Membuka Pengiklanan ChatGPT kepada Perniagaan Kecil pada Sebarang Bajet
Jun 6, 2026
AI Ada Di Mana-mana di Tempat Kerja. Hanya 1 daripada 10 yang Menyatakan Ia Mengubah Pekerjaan
Jun 6, 2026
Detik $10.5B Vibe Coding: AI Kini Memulakan Kebanyakan Pembangunan Perisian Baharu
Jun 6, 2026
Ejen AI Kini Mempunyai Lebih Banyak Akses Sistem daripada Pekerja Anda. Sedikit yang Dilindungi
Jun 5, 2026
Patut Bina atau Beli AI Anda? Perhatikan Apa yang Dibeli oleh Gergasi.
Jun 5, 2026
Uber Menetapkan Had Perbelanjaan AI Pekerja pada $1,500 Setiap Tempat Duduk Selepas Anggaran Terlampau
Jun 5, 2026
Perintah Eksekutif AI Trump Bersifat Penyahregulan. Risiko Pematuhan Anda Tidak Bergerak
Jun 4, 2026
AI Menolak 220 Unicorn di Bawah $1B. Syarikat Pra-ChatGPT Berdepan Pertanggungjawaban
Jun 4, 2026
Harga Token Jatuh 67% Tahun Ini. Bil AI Anda Tetap Naik
Jun 3, 2026
Perniagaan Kecil yang Menggunakan AI Melaporkan Hasil Lebih Tinggi dan Hari Kerja Lebih Pendek
Jun 3, 2026
Claude Opus 4.8 Ditambah Pusingan $965B Mengubah Model Perusahaan Lalai. Ini Adalah Ujian Penilikan Semula CTO
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dua perkara berlaku pada 28 Mei 2026 yang kebanyakan pemimpin teknologi perusahaan anggap sebagai berita berasingan. Sebenarnya tidak.
Pengumuman Anthropic mengeluarkan Claude Opus 4.8 -- 41 hari selepas Opus 4.7 -- sambil serentak menutup Series H bernilai $65B yang menolak penilaian pasca-wang syarikat ke $965B. Itu bukan sekadar pelancaran model dan pusingan pembiayaan. Itu adalah isyarat kestabilan vendor dan lonjakan kemampuan yang mendarat pada hari yang sama. Bagi ketua pegawai teknologi (CTO) yang membuat keputusan model perusahaan enam bulan lalu, kedua-dua berita itu penting -- dan soalan yang tepat bukan "model mana yang menang?" Ia adalah "adakah kita perlu menilai semula hubungan vendor AI lalai kita sekarang?"
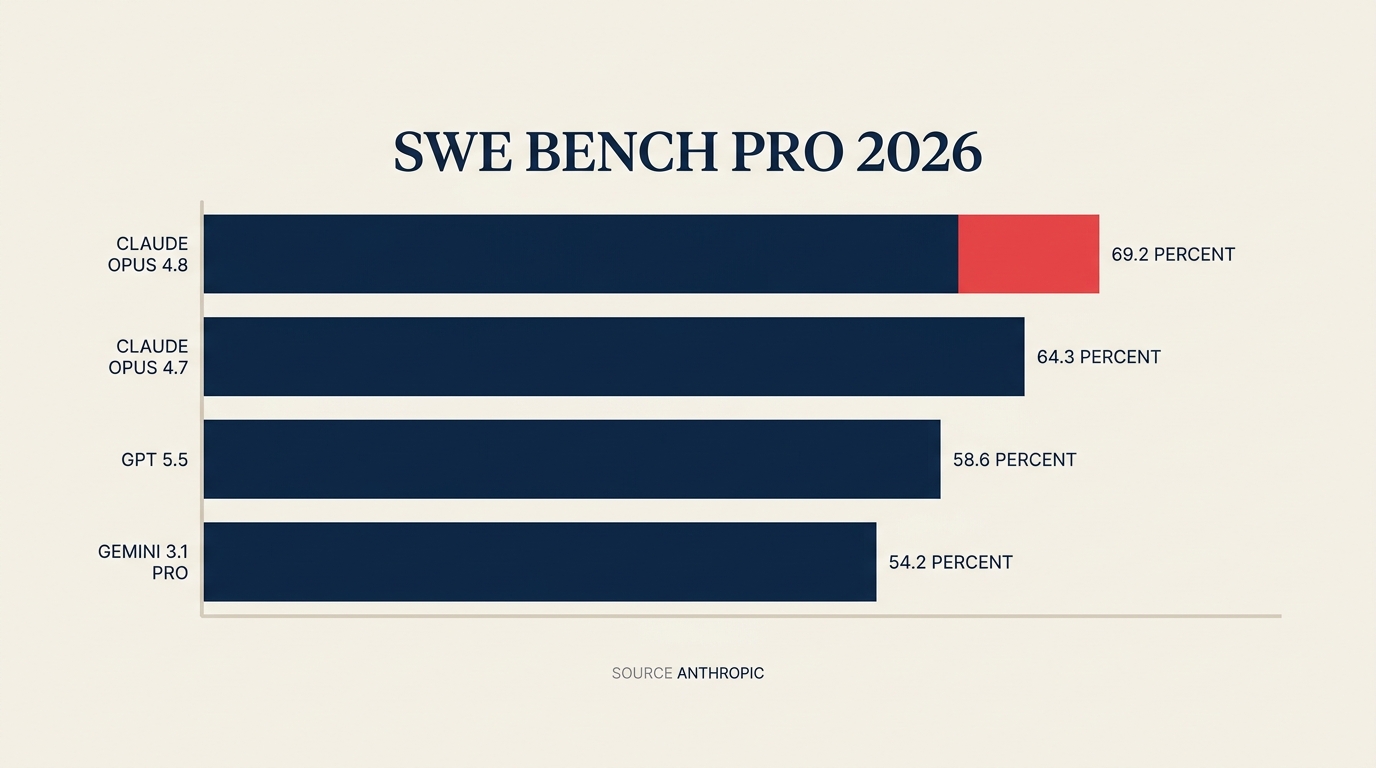
Menurut kenyataan Anthropic, Claude Opus 4.8 kini mendapat markah 69.2% pada SWE-Bench Pro, proksi industri yang paling hampir dengan kerja kejuruteraan perisian persekitaran produksi. GPT-5.5 mendapat markah 58.6% pada penanda aras yang sama. Gemini 3.1 Pro berada di 54.2%. Itu bukan jurang kecil. Dan Anthropic mengekalkan harga yang sama seperti Opus 4.7: $5 bagi setiap juta token input, $25 bagi setiap juta token output.
Apa yang Baru Berubah, dan Mengapa Ia Memaksa Keputusan
Sebelum beralih ke rangka kerja, ada baiknya kita tepat tentang apa yang "berubah." Tiga perkara berubah secara serentak: siling kemampuan, kedudukan kewangan vendor, dan luas kawasan pelaksanaan.
Fakta Utama Claude Opus 4.8 mendapat markah 69.2% pada SWE-Bench Pro (penanda aras kejuruteraan perisian) berbanding GPT-5.5 pada 58.6% dan Gemini 3.1 Pro pada 54.2%. (Sumber: Anthropic) Penilaian pasca-wang Anthropic meningkat tiga kali ganda daripada $380B pada Februari 2026 kepada $965B pada 28 Mei. (Sumber: TechCrunch) Hasil run-rate melepasi $47B lebih awal pada Mei 2026 sebelum pusingan ditutup. (Sumber: Anthropic)
Dari segi kemampuan: Opus 4.8 juga mendapat markah 88.6% pada SWE-bench Verified, 74.6% pada Terminal-Bench 2.1, dan 83.4% pada OSWorld-Verified untuk penggunaan komputer. Angka terakhir itu relevan bagi mana-mana CTO yang membina aliran kerja automatik yang melibatkan antara muka desktop atau pelayar web.
Dari segi kedudukan kewangan: Series H bernilai $65B itu merangkumi $15B yang sebelumnya telah dikomitmen daripada hyperscaler -- $5B daripada Amazon sahaja -- ditambah pelaburan infrastruktur strategik daripada Micron, Samsung, dan SK hynix. Ini bukan pusingan perisian dengan komitmen infrastruktur token. Ia adalah pertaruhan bahawa Anthropic akan mengawal bahagian penting tindanan komputnya sendiri.
Dari segi kawasan pelaksanaan: Opus 4.8 sudah aktif hari ini di Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry selain daripada API langsung. Jika perusahaan anda telah menstandarkan pada satu awan tunggal dan menggunakan itu sebagai alasan untuk kekal dengan model bersaing, alasan itu kini lebih lemah.
Tiada satu pun daripada ini bermakna anda harus bertukar secara automatik. Tetapi ia bermakna kes untuk tidak menyemak semula keputusan anda lebih sukar untuk dibuat.
Ujian Penilikan Semula Model

Kebanyakan keputusan model perusahaan dibuat sekali dan kemudian semakin usang secara senyap. Pelaksanaan baru bermula, pasukan kejuruteraan membina tabiat sekitar antara muka pengaturcaraan aplikasi (API) tertentu, dan kos penukaran bertambah dari masa ke masa. Dinamik itu baik -- sehingga satu pelancaran memaksa anda menyemak sama ada keputusan asal masih terpakai.
Berikut adalah rangka kerja lima soalan untuk pemeriksaan itu:
1. Adakah model ini memimpin pada kerja sebenar anda? Penanda aras yang diterbitkan adalah proksi. SWE-Bench Pro adalah proksi yang baik jika pasukan anda membuat kerja kejuruteraan perisian -- ia menguji isu GitHub sebenar, bukan teka-teki sintetik. Tetapi jika kes penggunaan utama anda adalah semakan kontrak, ringkasan sokongan pelanggan, atau analisis dokumen kewangan, jalankan penilaian anda sendiri menggunakan sampel tugas persekitaran produksi anda. Jurang penanda aras 10 mata tidak secara automatik bermakna 10 mata pada beban kerja anda.
2. Adakah vendor mempunyai landasan kewangan untuk menyokong kontrak berbilang tahun? Penilaian $965B dengan hasil run-rate $47B dan infusi tunai $65B bukan profil risiko syarikat permulaan. Namun landasan lebih penting daripada ketelusan pembakaran. Pelabur bersama hyperscaler Anthropic mempunyai insentif untuk mengekalkan syarikat itu beroperasi -- itu adalah penjajaran yang bermakna. Soalannya adalah sama ada pasukan undang-undang dan perolehan anda boleh merundingkan syarat yang mencerminkan peringkat baru ini.
3. Adakah model tersedia merentas jejak awan anda? Claude Opus 4.8 sudah aktif di Bedrock, Vertex AI, dan Foundry hari ini. Jika beban kerja anda merentas dua atau tiga hyperscaler dan pilihan model semasa anda memerlukan penghalaan semua melalui satu titik akhir awan tunggal, anda mempunyai hutang seni bina yang pelancaran ini boleh bantu selesaikan.
4. Adakah orkestrasi ejen vendor sepadan dengan peta jalan anda? Dynamic Workflows -- pratonton penyelidikan yang dihantar bersama Opus 4.8 dalam Claude Code -- menjalankan puluhan hingga ratusan ejen kecil selari daripada satu skrip orkestrasi dengan keadaan yang boleh disambung semula. Itu adalah kemampuan yang berbeza asasnya daripada saluran paip prompt-response. Jika peta jalan 12 bulan anda merangkumi ejen autonomi yang melakukan kerja berbilang langkah merentas pangkalan kod atau set data yang besar, lapisan orkestrasi penting sama seperti kualiti model asas. Kami membincangkan keputusan seni bina dan sempadan secara berasingan dalam artikel kami mengenai sandbok self-hosted dan terowong MCP Anthropic -- soalan ini khusus tentang sama ada model orkestrasi sesuai dengan beban kerja agentic anda.
5. Apakah kos dan risiko bertukar kembali jika anda berpindah? Ini adalah soalan yang paling banyak pasukan tinggalkan. Jika anda berhijrah daripada model semasa ke Opus 4.8, bagaimana rupa rollback dalam tempoh 12 bulan jika pelancaran bersaing mengubah gambaran penanda aras semula? Kos penukaran large language model (LLM) termasuk kejuruteraan semula prompt, pembinaan semula fine-tune, ujian integrasi, dan latihan semula bagi pasukan yang menggunakan alat tersebut. Ini bukan tidak dapat diatasi -- tetapi ia perlu dimasukkan dalam pengiraan.
Jika jawapan jujur anda ialah: "ya, ia memimpin pada kerja kami; ya, vendor itu stabil; ya, ia merangkumi awan kami; ya, lapisan ejen sesuai dengan peta jalan kami; dan kos penukaran boleh diterima" -- maka soalannya menjadi bila untuk berhijrah, bukan sama ada.
Isyarat Mythos
Anthropic juga menyebut -- tanpa tarikh pasti -- bahawa model kelas "Mythos" akan tersedia kepada semua pelanggan dalam beberapa minggu akan datang. Ini patut diambil perhatian untuk perancangan CTO, tetapi ia tidak seharusnya menangguhkan keputusan mengenai Opus 4.8.
Jika Mythos dihantar dalam empat hingga enam minggu dan ujian penilikan semula di atas sudah menunjuk ke arah Anthropic, urutannya mudah: pindahkan beban kerja ke Opus 4.8 sekarang, anggap Mythos sebagai peningkatan potensi selanjutnya, dan jangan biarkan "sesuatu yang lebih baik sedang datang" menjadi alasan untuk kekal pada model yang lebih lemah selama suku lagi. Logik itu hampir tidak pernah berakhir dengan cara yang betul.
Konteks Persaingan
Isyarat penjajaran semula Gartner yang kami bincangkan dalam peralihan pasaran ejen pengekodan AI relevan di sini: firma analisis sudah menyesuaikan peringkat vendor AI perusahaan mereka berdasarkan halaju kemampuan, bukan hanya kedudukan penanda aras semasa. Kadar pelancaran 41 hari Anthropic antara Opus 4.7 dan 4.8 adalah sebahagian daripada isyarat halaju itu.
Kedudukan Google juga patut dipantau. Platform ejen perusahaan Gemini adalah pesaing serius untuk beban kerja multimodal di mana kemampuan asli Gemini 3.1 Pro masih memimpin. Jurang SWE-Bench Pro tidak bermakna Gemini kalah dalam setiap kategori beban kerja -- ia bermakna Anthropic mempunyai keunggulan paling jelas pada tugas berkaitan kod buat masa ini.
Dan bagi pasukan yang masih menjalankan keputusan seni bina OpenAI sebagai pilihan perusahaan lalai: jurang penanda aras adalah nyata dan cukup besar untuk memerlukan penjelasan kepada kepimpinan kejuruteraan anda jika anda tidak sekurang-kurangnya menjalankan penilaian perbandingan.
Soalan Lazim
Haruskah kami bertukar daripada GPT-5.5 kepada Claude Opus 4.8? Kes penanda aras kukuh -- jurang 10.6 mata pada SWE-Bench Pro bukan sekadar bunyi. Tetapi jawapan yang tepat bergantung pada beban kerja anda. Jalankan Ujian Penilikan Semula Model di atas, khususnya soalan 1 (adakah keunggulan itu kekal pada tugas sebenar anda?) dan soalan 5 (berapa kos penukaran anda?). Jika kedua-dua jawapan menggalakkan, penghijrahan terkawal satu beban kerja persekitaran produksi adalah langkah seterusnya yang tepat -- bukan pertukaran platform menyeluruh.
Apa yang sebenarnya bermakna penilaian $965B untuk risiko perusahaan? Ia mengubah profil risiko vendor dalam dua cara. Pertama, Anthropic tidak lagi dalam kategori "syarikat permulaan yang dibiayai dengan baik yang mungkin diambil alih." Pelabur bersama hyperscaler (Amazon, dengan $5B) mempunyai insentif struktur untuk mengekalkannya bebas dan beroperasi. Kedua, pada penilaian ini, infrastruktur undang-undang dan perolehan Anthropic akan mula kelihatan lebih seperti vendor perisian perusahaan -- bermakna perjanjian tahap perkhidmatan (SLA), perjanjian pemprosesan data (DPA), dan pensijilan pematuhan yang lebih baik. Tetapi sahkan ini dengan pasukan undang-undang anda sendiri sebelum bergantung padanya.
Apakah Mythos? Anthropic telah merujuk "Mythos" sebagai kelas model generasi seterusnya melampaui Opus 4.8, dengan ketersediaan lebih luas yang akan datang dalam beberapa minggu. Tiada data penanda aras yang diterbitkan lagi. Anggap ia sebagai isyarat peta jalan, bukan komitmen perancangan.
Apa yang Perlu Dilakukan Minggu Ini
- Jalankan penilaian penanda aras Opus 4.8 berbanding dua tugas persekitaran produksi paling wakil anda. Jangan bergantung hanya pada penanda aras yang diterbitkan.
- Gunakan Ujian Penilikan Semula Model lima soalan dalam sesi 30 minit CTO atau Ketua AI. Dokumenkan jawapan anda -- ia akan berguna apabila Mythos dihantar dan anda perlu membuat keputusan semula.
- Semak jejak awan semasa anda berbanding ketersediaan Bedrock / Vertex AI / Foundry. Jika anda telah menggunakan ketersediaan awan sebagai alasan untuk kekal pada model bersaing, kekangan itu mungkin tidak lagi terpakai.
Ketahui Lebih Lanjut
- Sandbok Self-Hosted dan Terowong MCP Anthropic: Keputusan Seni Bina -- bahagian sempadan dan infrastruktur; artikel ini memberi tumpuan kepada keputusan pemilihan model
- Penjajaran Semula Pasaran Ejen Pengekodan AI Gartner
- Google Antigravity 2 dan Platform Ejen Perusahaan Gemini
- Keputusan Seni Bina CTO GPT-5.4 OpenAI
