More in
AI at Work ニュース
OpenAIがChatGPT広告を中小企業に予算制限なく開放した
6月 6, 2026
AIは職場のあらゆる場所に浸透した:しかし「仕事を根本から変えた」と言える人は10人に1人だけ
6月 6, 2026
Vibe Codingの105億ドルの瞬間:AIが新規ソフトウェア開発の大半を担うようになった
6月 6, 2026
AIエージェントは今や従業員よりも多くのシステムアクセス権を持っている:しかしセキュリティ対策はほとんど追いついていない
6月 5, 2026
AIは自社開発すべきか、購入すべきか。巨大企業が何を買収したかを見れば答えが見えてくる
6月 5, 2026
Uberは予算超過を受け、従業員1人あたりのAI利用上限を1,500ドルに設定した
6月 5, 2026
TrumpのAI大統領令は規制緩和を志向:しかし御社のコンプライアンスリスクは変わっていない
6月 4, 2026
AIが220社のユニコーン企業を時価総額10億ドル未満に押し下げた:ChatGPT以前のスタートアップは転換点を迎えている
6月 4, 2026
トークン価格は今年67%下落した:それでもAI費用は増え続けている
6月 3, 2026
AIを活用する中小企業は売上増加と勤務時間短縮を同時に実現している
6月 3, 2026
Claude Opus 4.8と9,650億ドルの評価額がデフォルトの企業向けモデルを変える。CTOのための再審査テスト
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
2026年5月28日に2つのことが起きました。ほとんどのエンタープライズ技術リーダーは別々のニュースとして扱っていますが、そうではありません。
Anthropicの発表は、Opus 4.7からわずか41日でClaude Opus 4.8をリリースするとともに、同社の時価総額を9,650億ドルに押し上げた650億ドルのシリーズHの調達完了を同時に宣言しました。これはモデルリリースと資金調達ラウンドの組み合わせではありません。ベンダーの安定性シグナルと能力の跳躍が同じ日に届いたのです。6か月前に企業向けモデルの判断を下したCTO(最高技術責任者)にとって、両方のニュースが重要であり、適切な問いは「どのモデルが勝つか」ではありません。「今すぐデフォルトのAIベンダー関係を再審査する必要があるか」です。
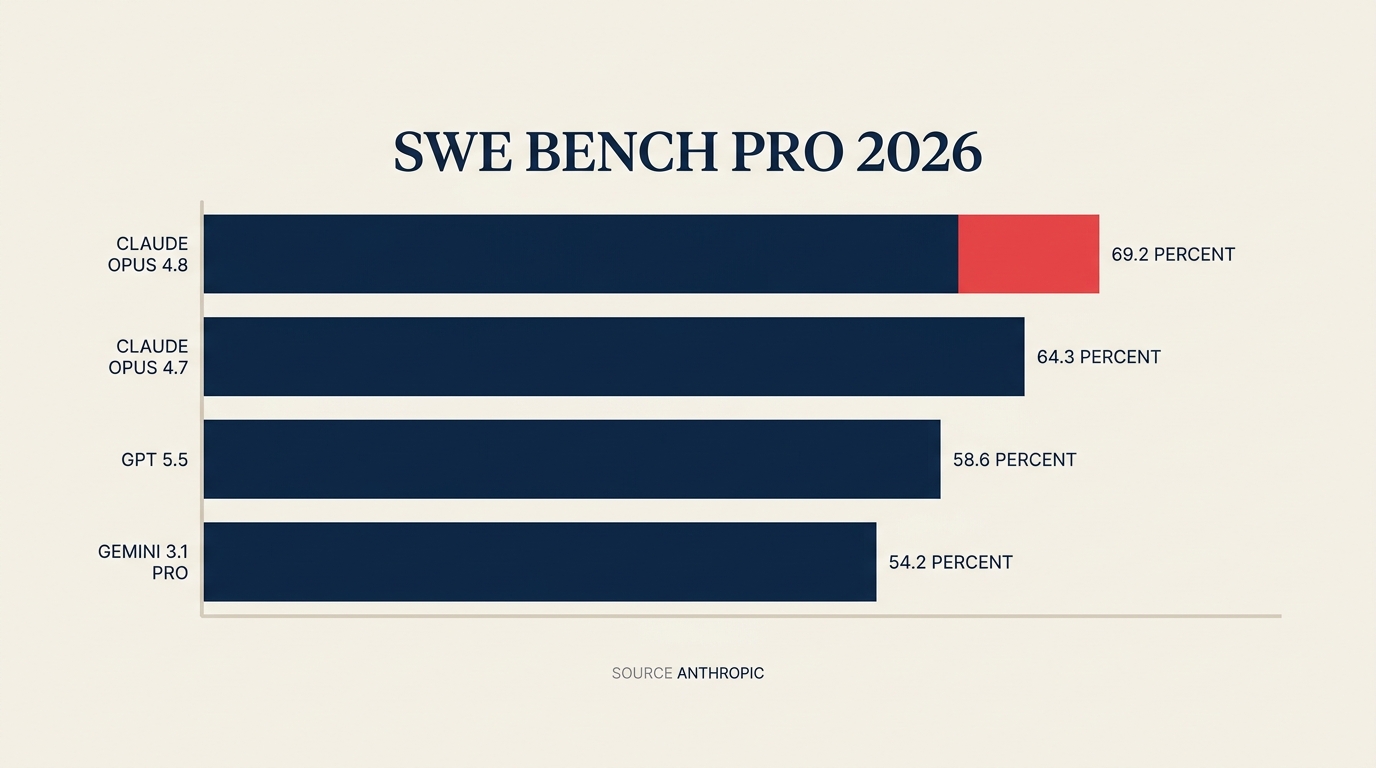
Anthropicの発表によると、Claude Opus 4.8はSWE-Bench Pro(業界で本番ソフトウェアエンジニアリング業務に最も近いプロキシ)で69.2%を達成しました。GPT-5.5は同じベンチマークで58.6%、Gemini 3.1 Proは54.2%です。わずかな差ではありません。そしてAnthropicは料金をOpus 4.7と同一に維持しています。入力トークン100万件あたり5ドル、出力トークン100万件あたり25ドルです。
何が変わったのか、そしてなぜ判断を迫られるのか
フレームワークに入る前に、「何が変わったか」を正確に把握する価値があります。3つのことが同時に変化しました。能力の上限、ベンダーの財務状況、そしてデプロイの展開範囲です。
主要な事実 Claude Opus 4.8はSWE-Bench Pro(ソフトウェアエンジニアリングベンチマーク)で69.2%を達成。GPT-5.5は58.6%、Gemini 3.1 Proは54.2%です。(出典: Anthropic) Anthropicの時価総額は2026年2月の3,800億ドルから5月28日に9,650億ドルへと3倍になりました。(出典: TechCrunch) 2026年5月のラウンド完了前に、ランレートの収益が470億ドルを超えていました。(出典: Anthropic)
能力面: Opus 4.8はSWE-bench Verifiedで88.6%、Terminal-Bench 2.1で74.6%、OSWorld-Verifiedのコンピューター操作で83.4%を達成しています。最後の数字は、デスクトップやブラウザのインターフェースに触れる自動化ワークフローを構築しているすべてのCTOに関係します。
財務面: 650億ドルのシリーズHには、以前にコミットされたハイパースケーラーからの150億ドルが含まれています(Amazon単独で50億ドル)。さらに、Micron、Samsung、SKハイニックスからの戦略的なインフラ投資も含まれます。ソフトウェアラウンドとトークン的なインフラコミットメントではありません。Anthropicが独自のコンピュートスタックの重要な部分を管理するための賭けです。
デプロイ展開面: Opus 4.8はAmazon Bedrock、Google Cloud Vertex AI、Microsoft Foundryで直接APIと並行して本日から利用可能です。単一クラウドで標準化し、それを理由に競合モデルに留まっていた場合、その理由は今や弱くなっています。
これらのいずれも、自動的に切り替えるべきだということを意味しません。しかし、判断を見直さない理由を主張することがより困難になったことは確かです。
モデル再審査テスト

ほとんどの企業向けモデルの判断は一度行われ、その後静かに時を経ます。新しいデプロイが始まり、エンジニアリングチームは特定のAPI(アプリケーションプログラミングインターフェース)に対する作業の習慣を積み上げ、時間とともに切り替えコストが増大します。このダイナミクスは問題ありません。新しいリリースが元の判断が依然として有効かどうかを確認する必要を生じさせるまでは。
その確認のための5つの質問フレームワークを紹介します。
1. このモデルは自社の実際の業務でリードしているか。 公開されたベンチマークはプロキシです。SWE-Bench Proはチームがソフトウェアエンジニアリングを行うなら良いプロキシです。実際のGitHubの問題をテストしており、合成的なパズルではありません。しかし、主要なユースケースが契約審査、カスタマーサポートの要約、または財務書類の分析であれば、本番タスクのサンプルで独自の評価を実施してください。10ポイントのベンチマーク差が自社のワークロードで自動的に10ポイントの差をもたらすとは限りません。
2. ベンダーは複数年契約をサポートする財務的なランウェイを持っているか。 9,650億ドルの評価額と470億ドルのランレート収益、650億ドルの資金注入はスタートアップのリスクプロファイルではありません。ただし、ランウェイよりも燃焼の透明性が重要です。Anthropicのハイパースケーラーの共同投資家は同社を独立して運営し続けることにインセンティブがあり、これは意味のある一致です。問題は、法務・調達チームがこの新しい層を反映した条件を交渉できるかどうかです。
3. モデルは自社のクラウドフットプリント全体で利用可能か。 Claude Opus 4.8はBedrock、Vertex AI、Foundryで本日から利用可能です。ワークロードが2つか3つのハイパースケーラーにまたがり、現在のモデル選択が単一のクラウドエンドポイント経由でのルーティングを必要とする場合、このリリースで解消できるアーキテクチャ上の負債があります。
4. ベンダーのエージェントオーケストレーション層は自社のロードマップに合致しているか。 Dynamic Workflows(Claude CodeのOpus 4.8とともにリサーチプレビューとして提供)は、単一のオーケストレーションスクリプトから数十から数百の並列サブエージェントを再開可能な状態で実行します。これは、プロンプトと応答のパイプラインとは根本的に異なる能力です。12か月のロードマップに大規模なコードベースやデータセットにまたがる複数ステップの業務を行う自律エージェントが含まれている場合、オーケストレーション層は基盤モデルの品質と同様に重要です。アーキテクチャと境界の判断についてはAnthropicのセルフホスト型サンドボックスとMCPトンネルに関する記事で別途扱っています。この質問は、オーケストレーションモデルがエージェント型ワークロードに適合しているかどうかに特化しています。
5. 移行した場合に切り替え戻すコストとリスクはどれくらいか。 ほとんどのチームが飛ばす質問です。現在のモデルからOpus 4.8に移行した場合、12か月後に競合のリリースがベンチマーク状況を再び変えたときのロールバックはどのようなものになりますか。LLM(大規模言語モデル)の切り替えコストには、プロンプトの再設計、ファインチューニングの再構築、統合テスト、そしてツールを使用するチームの再教育が含まれます。克服できないわけではありませんが、計算に含める必要があります。
正直な回答が「はい、自社の業務でリードしている。はい、ベンダーは安定している。はい、自社のクラウドをカバーしている。はい、エージェント層が自社のロードマップに適合している。そして切り替えコストは許容範囲内だ」であれば、問いは切り替えるかどうかではなく、いつ移行するかになります。
Mythosシグナル
Anthropicはまた、具体的な日程を示さずに「Mythosクラス」のモデルが数週間以内にすべての顧客に提供されると言及しました。これはCTOの計画において注目に値しますが、Opus 4.8に関する判断を遅らせるべきではありません。
MythosがAnthropic方向への移行を既に示唆している再審査テストの結果を受けて4から6週間後にリリースされた場合、順序は単純です。ワークロードを今すぐOpus 4.8に移行し、Mythosをさらなるアップグレードの可能性として扱い、「もっと良いものが来る」を理由に別の四半期間弱いモデルに留まることを避けてください。その論理はほとんど正しい方向に解決しません。
競合状況
AIコーディングエージェント市場の転換に関する記事で取り上げたGartnerの再整理シグナルはここでも関連します。アナリスト会社は現在のベンチマーク位置だけでなく、能力の速度に基づいてエンタープライズAIベンダー層を調整しています。AnthropicのOpus 4.7から4.8への41日間のリリースサイクルはその速度シグナルの一部です。
Googleの動向も注目に値します。Gemini Enterpriseのエージェントプラットフォームは、Gemini 3.1 Proのネイティブ機能がリードしているマルチモーダルワークロードで有力な競合です。SWE-Bench Proの差はGeminiがすべてのワークロードカテゴリで負けることを意味しません。今Anthropicがコード関連タスクで最も明確なリードを持っているということです。
そして、OpenAIのアーキテクチャ判断をデフォルトの企業向け選択肢として依然として採用しているチームについて: ベンチマークの差は現実であり、比較評価を少なくとも実施しないことについてエンジニアリングリーダーシップに説明できるほど十分に大きいです。
よくある質問
GPT-5.5からClaude Opus 4.8に切り替えるべきですか。 ベンチマークの根拠は強いです。SWE-Bench Proで10.6ポイントの差はノイズではありません。しかし適切な回答はワークロードによります。上記のモデル再審査テスト、特に質問1(自社の実際のタスクでそのリードが続くか)と質問5(切り替えコストはどれくらいか)を実施してください。両方の回答が良好であれば、プラットフォーム全体を一括して切り替えるのではなく、1つの本番ワークロードの制御された移行が適切な次のステップです。
9,650億ドルの評価額はエンタープライズリスクにとって何を意味しますか。 ベンダーのリスクプロファイルを2つの点で変えます。第一に、Anthropicは「十分な資金を持つスタートアップが買収される可能性がある」カテゴリーから外れました。ハイパースケーラーの共同投資家(Amazonが50億ドル)は、同社を独立して運営し続けることに構造的にインセンティブがあります。第二に、この評価額では、Anthropicのリーガルおよびプロキュアメントのインフラがエンタープライズソフトウェアベンダーに近い形になります。つまり、より充実したSLA(サービスレベル契約)、DPA(データ処理契約)、コンプライアンス認証が期待できます。ただし、これは自社の法務チームが確認してから信頼するものであり、前提とするものではありません。
Mythosとは何ですか。 AnthropicはOpus 4.8を超える次世代のモデルクラスとして「Mythos」に言及しており、数週間以内により広い利用可能性が来るとしています。まだ公開されたベンチマークデータはありません。ロードマップシグナルとして扱い、計画上のコミットメントとしてではありません。
今週すべきこと
- 最も代表的な本番タスク2つについて、Opus 4.8のベンチマーク評価を実施してください。公開されたベンチマークのみに依存しないでください。
- 5つの質問によるモデル再審査テストを30分のCTOまたはAI責任者セッションで実施してください。回答を文書化してください。Mythosがリリースされたときに再度判断する際に役立ちます。
- Bedrock / Vertex AI / Foundryの利用可能性に照らして現在のクラウドフットプリントを確認してください。クラウドの利用可能性を競合モデルに留まる理由として使用してきた場合、その制約はもはや適用されないかもしれません。
参考情報
- AnthropicのセルフホストサンドボックスとMCPトンネル: アーキテクチャの判断 - 境界とインフラの観点。この記事はモデル選択の判断に焦点を当てています
- GartnerのAIコーディングエージェント市場の再整理
- Google Antigravity 2とGemini Enterpriseエージェントプラットフォーム
- OpenAI GPT-5.4 CTOアーキテクチャ判断

Co-Founder, Rework.com