More in
Notícias de AI no Trabalho
A OpenAI Abriu a Publicidade no ChatGPT para Pequenas Empresas com Qualquer Orçamento
jun 6, 2026
AI Está em Todo Lugar no Trabalho. Apenas 1 em 10 Diz que Transformou o Emprego
jun 6, 2026
O Momento de US$ 10,5B do Vibe Coding: AI Agora Inicia a Maioria dos Novos Projetos de Software
jun 6, 2026
Agentes de AI Agora Têm Mais Acesso ao Sistema do que Seus Funcionários. Poucos Estão Protegidos
jun 5, 2026
Você Deve Construir Sua AI ou Comprá-la? Observe o que os Gigantes Compraram.
jun 5, 2026
A Uber Limitou os Gastos de AI por Funcionário a US$ 1.500 por Assento Após um Estouro de Orçamento
jun 5, 2026
O Decreto Executivo de AI de Trump é Desregulamentador. Seu Risco de Conformidade Não Mudou
jun 4, 2026
A AI Empurrou 220 Unicórnios Abaixo de US$ 1B. Empresas Pré-ChatGPT Enfrentam um Acerto de Contas
jun 4, 2026
Os Preços de Token Caíram 67% Este Ano. Sua Conta de AI Está Aumentando de Qualquer Forma
jun 3, 2026
Pequenas Empresas que Usam AI Relatam Maior Receita e Jornadas de Trabalho Mais Curtas
jun 3, 2026
Claude Opus 4.8 Mais uma Rodada de US$ 965 Bilhões Muda o Modelo Empresarial Padrão. Veja o Teste de Reavaliação do CTO
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Duas coisas aconteceram em 28 de maio de 2026 que a maioria dos líderes de tecnologia empresarial está tratando como notícias separadas. Elas não são.
O anúncio da Anthropic lançou o Claude Opus 4.8 -- 41 dias após o Opus 4.7 -- enquanto simultaneamente fechava uma Série H de US$ 65 bilhões que elevou a avaliação pós-investimento da empresa para US$ 965 bilhões. Isso não é um lançamento de modelo e uma rodada de financiamento. É um sinal de estabilidade do fornecedor e um salto de capacidade chegando no mesmo dia. Para chief technology officers (CTOs) que tomaram uma decisão de modelo empresarial há seis meses, ambas as notícias importam -- e a pergunta certa não é "qual modelo vence?" É: "precisamos reavaliar nosso relacionamento padrão com o fornecedor de AI agora?"
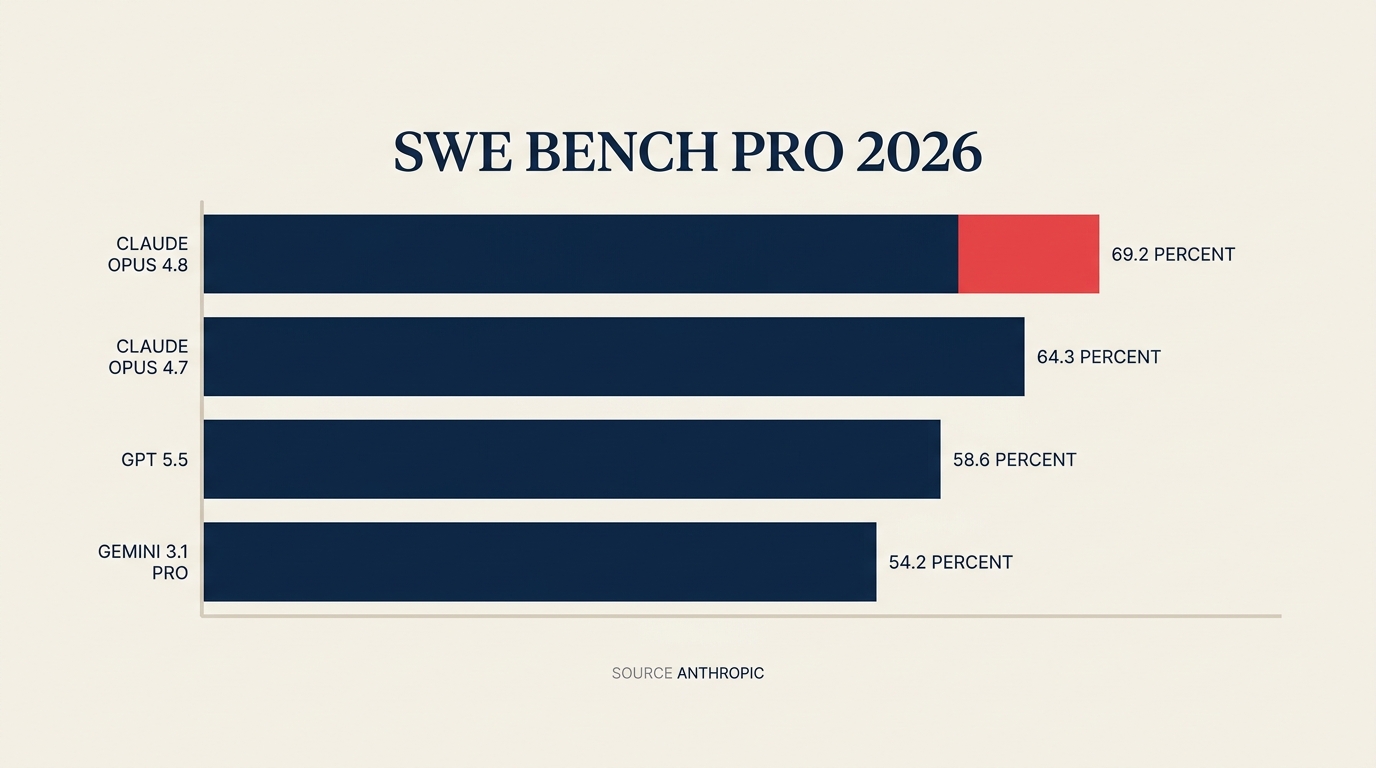
Conforme o lançamento da Anthropic, o Claude Opus 4.8 agora pontua 69,2% no SWE-Bench Pro, o proxy mais próximo da indústria para trabalho real de engenharia de software em produção. O GPT-5.5 pontua 58,6% no mesmo benchmark. O Gemini 3.1 Pro fica em 54,2%. Essa não é uma diferença marginal. E a Anthropic manteve o preço idêntico ao Opus 4.7: US$ 5 por milhão de tokens de entrada, US$ 25 por milhão de tokens de saída.
O Que Mudou e Por Que Isso Exige Uma Decisão
Antes de chegar ao framework, vale ser preciso sobre o que "mudou". Três coisas se alteraram simultaneamente: teto de capacidade, posição financeira do fornecedor e área de superfície de implantação.
Dados-chave O Claude Opus 4.8 pontua 69,2% no SWE-Bench Pro (benchmark de engenharia de software) versus GPT-5.5 com 58,6% e Gemini 3.1 Pro com 54,2%. (Fonte: Anthropic) A avaliação pós-investimento da Anthropic triplicou de US$ 380 bilhões em fevereiro de 2026 para US$ 965 bilhões em 28 de maio. (Fonte: TechCrunch) A receita recorrente cruzou US$ 47 bilhões mais cedo em maio de 2026, antes do fechamento da rodada. (Fonte: Anthropic)
Em capacidade: o Opus 4.8 também pontua 88,6% no SWE-bench Verified, 74,6% no Terminal-Bench 2.1 e 83,4% no OSWorld-Verified de uso de computador. Esse último número é relevante para qualquer CTO construindo fluxos de trabalho automatizados que envolvam interfaces desktop ou browser.
Em posição financeira: a Série H de US$ 65 bilhões inclui US$ 15 bilhões previamente comprometidos por hyperscalers -- US$ 5 bilhões só da Amazon -- mais investimentos estratégicos em infraestrutura da Micron, Samsung e SK hynix. Esta não é uma rodada de software com compromissos de infraestrutura simbólicos. É uma aposta no controle da Anthropic sobre partes significativas de sua própria pilha de computação.
Em área de implantação: o Opus 4.8 está disponível hoje no Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry, além da API direta. Se sua empresa padronizou em um único cloud e usou isso como razão para permanecer com um modelo concorrente, essa razão está mais fraca agora.
Nada disso significa automaticamente que você deve trocar. Mas significa que o caso para não revisar sua decisão está mais difícil de sustentar.
O Teste de Reavaliação do Modelo

A maioria das decisões de modelo empresarial acontece uma vez e depois envelhece silenciosamente. Uma nova implantação começa, as equipes de engenharia constroem familiaridade em torno de uma interface de programação de aplicativos (API) específica, e os custos de troca se acumulam ao longo do tempo. Essa dinâmica é aceitável -- até que um lançamento obrigue você a verificar se a decisão original ainda se sustenta.
Aqui está o framework de cinco perguntas para essa verificação:
1. Este modelo lidera no seu trabalho real? Benchmarks publicados são aproximações. O SWE-Bench Pro é um bom proxy se suas equipes fazem engenharia de software -- ele testa problemas reais do GitHub, não quebra-cabeças sintéticos. Mas se seu caso de uso principal é revisão de contratos, sumarização de suporte ao cliente ou análise de documentos financeiros, execute sua própria avaliação em uma amostra das suas tarefas de produção. Uma diferença de 10 pontos no benchmark não se traduz automaticamente em 10 pontos na sua carga de trabalho.
2. O fornecedor tem fôlego financeiro para suportar contratos de vários anos? Uma avaliação de US$ 965 bilhões com US$ 47 bilhões em receita recorrente e uma injeção de US$ 65 bilhões em caixa não é o perfil de risco de uma startup. Dito isso, o fôlego importa menos do que a transparência sobre o burn rate. Os co-investidores hyperscalers da Anthropic têm incentivo para manter a empresa operacional -- isso representa alinhamento significativo. A questão é se suas equipes jurídicas e de compras conseguem negociar termos que reflitam esse novo patamar.
3. O modelo está disponível em toda a sua infraestrutura cloud? O Claude Opus 4.8 está disponível hoje no Bedrock, Vertex AI e Foundry. Se suas cargas de trabalho se distribuem por dois ou três hyperscalers e sua escolha de modelo atual exige roteamento de tudo por um único endpoint cloud, você tem dívida arquitetural que este lançamento pode ajudar a resolver.
4. A orquestração de agentes do fornecedor corresponde ao seu roadmap? Dynamic Workflows -- a prévia de pesquisa que vem com o Opus 4.8 no Claude Code -- executa dezenas a centenas de subagentes em paralelo a partir de um único script de orquestração com estado retomável. Essa é uma capacidade fundamentalmente diferente de pipelines de prompt-resposta. Se o seu roadmap de 12 meses inclui agentes autônomos fazendo trabalho em múltiplas etapas em grandes codebases ou conjuntos de dados, a camada de orquestração importa tanto quanto a qualidade do modelo base. Cobrimos as decisões de arquitetura e perímetro separadamente em nosso artigo sobre sandboxes self-hosted e MCP tunnels da Anthropic -- esta pergunta é especificamente sobre se o modelo de orquestração se encaixa nas suas cargas de trabalho agênticas.
5. Qual é o custo e o risco de voltar atrás se você mudar? Essa é a pergunta que a maioria das equipes pula. Se você migrar do seu modelo atual para o Opus 4.8, como seria o rollback em 12 meses se um lançamento concorrente mudar novamente o quadro de benchmarks? Os custos de troca de large language model (LLM) incluem reengenharia de prompts, reconstrução de fine-tuning, testes de integração e retreinamento das equipes que usam as ferramentas. Esses custos não são insuperáveis -- mas precisam estar no cálculo.
Se suas respostas honestas forem: "sim, ele lidera no nosso trabalho; sim, o fornecedor é estável; sim, cobre nossos clouds; sim, a camada de agentes se encaixa no nosso roadmap; e o custo de troca é aceitável" -- então a questão passa a ser quando migrar, não se migrar.
O Sinal Mythos
A Anthropic também mencionou -- sem data definida -- que um modelo da "classe Mythos" estará disponível para todos os clientes nas próximas semanas. Vale notar isso para o planejamento do CTO, mas não deve atrasar uma decisão sobre o Opus 4.8.
Se o Mythos chegar em quatro a seis semanas e o teste de reavaliação acima já aponta para a Anthropic, o sequenciamento é simples: mova as cargas de trabalho para o Opus 4.8 agora, trate o Mythos como um potencial upgrade adicional e não deixe "algo melhor está chegando" se tornar um motivo para permanecer em um modelo mais fraco por mais um trimestre. Essa lógica quase nunca se resolve da maneira certa.
Contexto Competitivo
O sinal de realinhamento do Gartner que cobrimos em mudanças no mercado de agentes de codificação com AI é relevante aqui: as firmas de análise já estão ajustando seus tiers de fornecedores de AI empresarial com base na velocidade de capacidade, não apenas na posição atual no benchmark. O ritmo de lançamento de 41 dias da Anthropic entre Opus 4.7 e 4.8 faz parte desse sinal de velocidade.
A posição do Google também merece atenção. A plataforma de agentes do Gemini Enterprise é uma concorrente séria para cargas de trabalho multimodais onde as capacidades nativas do Gemini 3.1 Pro ainda lideram. A diferença no SWE-Bench Pro não significa que o Gemini perde em todas as categorias de carga de trabalho -- significa que a Anthropic tem a liderança mais clara em tarefas relacionadas a código agora.
E para equipes que ainda rodam as decisões de arquitetura da OpenAI como escolha empresarial padrão: a diferença no benchmark é real e grande o suficiente para exigir uma explicação à sua liderança de engenharia se você não estiver ao menos conduzindo uma avaliação comparativa.
Perguntas Frequentes
Devemos trocar do GPT-5.5 para o Claude Opus 4.8? O caso do benchmark é forte -- uma diferença de 10,6 pontos no SWE-Bench Pro não é ruído. Mas a resposta certa depende da sua carga de trabalho. Execute o Teste de Reavaliação do Modelo acima, especificamente a pergunta 1 (a liderança se mantém nas suas tarefas reais?) e a pergunta 5 (qual é o seu custo de troca?). Se ambas as respostas forem favoráveis, uma migração controlada de uma carga de trabalho de produção é o próximo passo certo -- não uma troca total de plataforma.
O que uma avaliação de US$ 965 bilhões significa de fato para o risco empresarial? Isso muda o perfil de risco do fornecedor de duas formas. Primeiro, a Anthropic não está mais na categoria de "startup bem financiada que pode ser adquirida". Os co-investidores hyperscalers (Amazon, com US$ 5 bilhões) têm incentivo estrutural para mantê-la independente e operacional. Segundo, com essa avaliação, a infraestrutura jurídica e de compras da Anthropic começará a se parecer mais com a de um fornecedor de software empresarial -- o que significa melhores service level agreements (SLAs), acordos de processamento de dados (DPAs) e certificações de conformidade. Mas verifique isso com sua própria equipe jurídica antes de depender dessas garantias.
O que é Mythos? A Anthropic referenciou "Mythos" como uma classe de modelo de próxima geração além do Opus 4.8, com disponibilidade mais ampla chegando em semanas. Nenhum dado de benchmark é público ainda. Trate-o como um sinal de roadmap, não como um compromisso de planejamento.
O Que Fazer Esta Semana
- Execute uma avaliação de benchmark do Opus 4.8 em relação às suas duas tarefas de produção mais representativas. Não dependa apenas de benchmarks publicados.
- Use o Teste de Reavaliação do Modelo de cinco perguntas em uma sessão de 30 minutos com seu CTO ou Head de AI. Documente suas respostas -- elas serão úteis quando o Mythos chegar e você precisar decidir novamente.
- Verifique sua infraestrutura cloud atual em relação à disponibilidade no Bedrock, Vertex AI e Foundry. Se você estava usando a disponibilidade cloud como razão para permanecer em um modelo concorrente, essa restrição pode não se aplicar mais.
Saiba Mais
- Sandboxes Self-Hosted e MCP Tunnels da Anthropic: A Decisão de Arquitetura -- a parte de perímetro e infraestrutura; este artigo foca na decisão de seleção de modelo
- Realinhamento do Mercado de Agentes de Codificação com AI pelo Gartner
- Google Antigravity 2 e a Plataforma de Agentes do Gemini Enterprise
- Decisão de Arquitetura do CTO para OpenAI GPT-5.4
