More in
Noticias de AI en el Trabajo
OpenAI Abrio la Publicidad en ChatGPT a Pequenas Empresas con Cualquier Presupuesto
jun. 6, 2026
La AI Esta en Todas Partes en el Trabajo. Solo 1 de Cada 10 Dice que Transformo el Empleo
jun. 6, 2026
El Momento de $10.5B del Vibe Coding: AI Ahora Inicia la Mayoria de los Nuevos Desarrollos de Software
jun. 6, 2026
Los Agentes de AI Tienen Ahora Mas Acceso al Sistema que sus Empleados. Pocos Estan Asegurados
jun. 5, 2026
¿Deberia Construir su AI o Comprarla? Observe lo que Compraron los Gigantes.
jun. 5, 2026
Uber Limita el Gasto de AI por Empleado a $1,500 por Puesto Tras un Descontrol Presupuestario
jun. 5, 2026
La Orden Ejecutiva de AI de Trump es Desregulatoria. Su Riesgo de Cumplimiento No Cambio
jun. 4, 2026
La AI Empujo a 220 Unicornios por Debajo de $1B. Las Empresas Pre-ChatGPT Enfrentan un Ajuste de Cuentas
jun. 4, 2026
Los Precios por Token Cayeron un 67% Este Ano. Su Factura de AI Sigue Subiendo
jun. 3, 2026
Las Pequenas Empresas que Usan AI Reportan Mayores Ingresos y Jornadas Laborales Mas Cortas
jun. 3, 2026
Claude Opus 4.8 más una ronda de 965.000 millones de dólares cambia el modelo empresarial predeterminado. La prueba de re-evaluación del CTO
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
El 28 de mayo de 2026 ocurrieron dos cosas que la mayoría de los líderes tecnológicos empresariales están tratando como noticias separadas. No lo son.
El anuncio de Anthropic presentó Claude Opus 4.8, 41 días después de Opus 4.7, y al mismo tiempo cerró una Serie H de 65.000 millones de dólares que llevó la valoración post-money de la empresa a 965.000 millones. Eso no es un lanzamiento de modelo más una ronda de financiación. Es una señal de estabilidad del proveedor y un salto de capacidad que llegaron el mismo día. Para los Chief Technology Officers (CTOs) que tomaron una decisión de modelo empresarial hace seis meses, ambas noticias importan, y la pregunta correcta no es "¿qué modelo gana?", sino "¿necesitamos re-evaluar nuestra relación predeterminada con el proveedor de AI ahora mismo?"
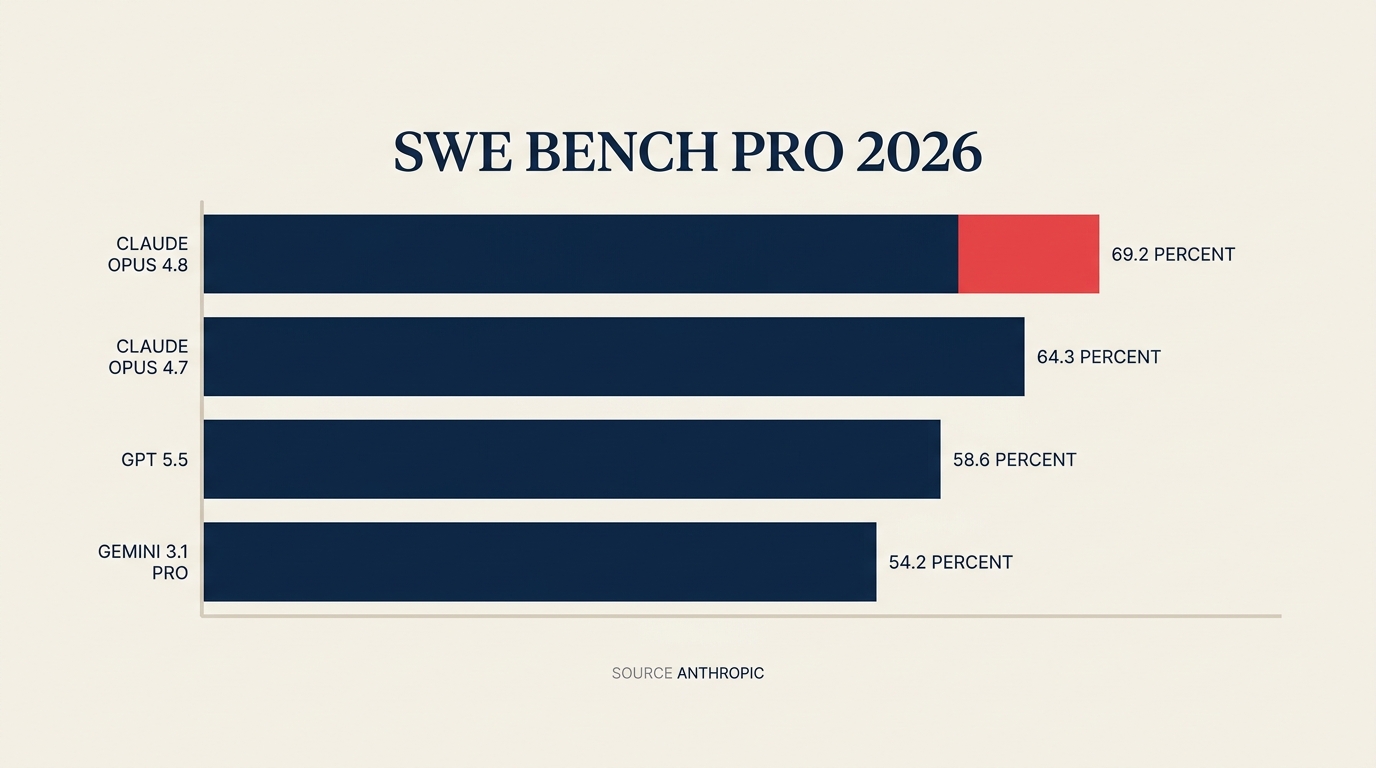
Según el comunicado de Anthropic, Claude Opus 4.8 ahora obtiene 69,2% en SWE-Bench Pro, el proxy más cercano de la industria para el trabajo de ingeniería de software en producción. GPT-5.5 obtiene 58,6% en el mismo benchmark. Gemini 3.1 Pro se sitúa en 54,2%. Esa no es una diferencia marginal. Y Anthropic mantuvo el precio idéntico al de Opus 4.7: 5 dólares por millón de tokens de entrada, 25 dólares por millón de tokens de salida.
Qué cambió y por qué obliga a tomar una decisión
Antes de pasar al marco de evaluación, conviene precisar qué "cambió". Tres cosas se modificaron simultáneamente: el techo de capacidad, la posición financiera del proveedor y la superficie de implementación.
Datos clave Claude Opus 4.8 obtiene 69,2% en SWE-Bench Pro (benchmark de ingeniería de software) frente al 58,6% de GPT-5.5 y el 54,2% de Gemini 3.1 Pro. (Fuente: Anthropic) La valoración post-money de Anthropic se triplicó de 380.000 millones de dólares en febrero de 2026 a 965.000 millones el 28 de mayo. (Fuente: TechCrunch) Los ingresos en tasa de ejecución superaron los 47.000 millones de dólares a principios de mayo de 2026, antes del cierre de la ronda. (Fuente: Anthropic)
En cuanto a capacidad: Opus 4.8 también obtiene 88,6% en SWE-bench Verified, 74,6% en Terminal-Bench 2.1 y 83,4% en OSWorld-Verified para uso de computadora. Este último número es relevante para cualquier CTO que construya flujos de trabajo automatizados que toquen interfaces de escritorio o navegador.
En cuanto a posición financiera: la Serie H de 65.000 millones de dólares incluye 15.000 millones comprometidos previamente por hyperscalers, 5.000 millones solo de Amazon, más inversiones estratégicas en infraestructura de Micron, Samsung y SK hynix. Esta no es una ronda de software con compromisos de infraestructura simbólicos. Es una apuesta sobre que Anthropic controlará partes significativas de su propia pila de cómputo.
En cuanto a superficie de implementación: Opus 4.8 ya está disponible en Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry, además de la API directa. Si su empresa estandarizó en una sola nube y usó eso como razón para mantener un modelo competidor, ese argumento es más débil ahora.
Nada de esto implica automáticamente que deba cambiar. Pero sí significa que es más difícil justificar no revisar su decisión.
La prueba de re-evaluación del modelo

La mayoría de las decisiones de modelo empresarial ocurren una vez y luego envejecen silenciosamente. Comienza una nueva implementación, los equipos de ingeniería desarrollan memoria muscular en torno a una interfaz de programación de aplicaciones (API) particular, y los costos de cambio se acumulan con el tiempo. Esa dinámica es aceptable, hasta que un lanzamiento lo obliga a verificar si la decisión original sigue siendo válida.
Aquí está el marco de cinco preguntas para esa verificación:
1. ¿Lidera este modelo en su trabajo real? Los benchmarks publicados son aproximaciones. SWE-Bench Pro es una buena si sus equipos hacen ingeniería de software: evalúa problemas reales de GitHub, no ejercicios sintéticos. Pero si su caso de uso principal es la revisión de contratos, el resumen de atención al cliente o el análisis de documentos financieros, ejecute su propia evaluación con una muestra de sus tareas en producción. Una diferencia de 10 puntos en el benchmark no se traduce automáticamente en 10 puntos en su carga de trabajo.
2. ¿Tiene el proveedor la solidez financiera para respaldar contratos plurianuales? Una valoración de 965.000 millones de dólares con 47.000 millones en tasa de ejecución y una infusión de efectivo de 65.000 millones no es el perfil de riesgo de una startup. Dicho esto, la solidez financiera importa menos que la transparencia sobre el gasto. Los co-inversores hyperscaler de Anthropic tienen incentivos para mantener la empresa operativa, lo cual es un alineamiento significativo. La pregunta es si sus equipos legal y de compras pueden negociar términos que reflejen este nuevo nivel.
3. ¿Está el modelo disponible en toda su infraestructura cloud? Claude Opus 4.8 ya está disponible en Bedrock, Vertex AI y Foundry. Si sus cargas de trabajo abarcan dos o tres hyperscalers y su elección de modelo actual requiere enrutar todo a través de un único endpoint en la nube, tiene deuda arquitectónica que este lanzamiento podría ayudar a saldar.
4. ¿Se ajusta la orquestación de agentes del proveedor a su hoja de ruta? Dynamic Workflows, la vista previa de investigación que acompaña a Opus 4.8 en Claude Code, ejecuta decenas o cientos de subagentes en paralelo desde un único script de orquestación con estado reanudable. Esa es una capacidad fundamentalmente diferente a los pipelines de pregunta-respuesta. Si su hoja de ruta a 12 meses incluye agentes autónomos que realizan trabajo de varios pasos en grandes bases de código o conjuntos de datos, la capa de orquestación importa tanto como la calidad del modelo base. Cubrimos las decisiones de arquitectura y perímetro por separado en nuestro artículo sobre los sandboxes autohospedados y los túneles MCP de Anthropic. Esta pregunta trata específicamente de si el modelo de orquestación se adapta a sus cargas de trabajo agénticas.
5. ¿Cuál es el costo y el riesgo de volver atrás si realiza el cambio? Esta es la pregunta que la mayoría de los equipos omite. Si migra de su modelo actual a Opus 4.8, ¿cómo sería una vuelta atrás en 12 meses si un lanzamiento competidor cambia el panorama de benchmarks? Los costos de cambio de un Large Language Model (LLM) incluyen la re-ingeniería de prompts, la reconstrucción de ajustes finos, las pruebas de integración y la reentrenamiento de los equipos que usan las herramientas. No son insuperables, pero deben estar en el cálculo.
Si sus respuestas honestas son: "sí, lidera en nuestro trabajo; sí, el proveedor es estable; sí, cubre nuestras nubes; sí, la capa de agentes se adapta a nuestra hoja de ruta; y el costo de cambio es aceptable", entonces la pregunta pasa a ser cuándo migrar, no si hacerlo.
La señal de Mythos
Anthropic también mencionó, sin una fecha concreta, que un modelo de "clase Mythos" estará disponible para todos los clientes en las próximas semanas. Vale la pena tenerlo en cuenta para la planificación del CTO, pero no debería retrasar una decisión sobre Opus 4.8.
Si Mythos se lanza en cuatro a seis semanas y la prueba de re-evaluación anterior ya apunta hacia Anthropic, la secuencia es sencilla: migre las cargas de trabajo a Opus 4.8 ahora, trate Mythos como una posible mejora adicional, y no permita que "algo mejor está por venir" se convierta en una razón para quedarse en un modelo más débil durante otro trimestre. Esa lógica casi nunca se resuelve en la dirección correcta.
Contexto competitivo
La señal de realineamiento de Gartner que cubrimos en los cambios del mercado de agentes de codificación AI es relevante aquí: las firmas analistas ya están ajustando sus niveles de proveedores de AI empresarial basándose en la velocidad de capacidad, no solo en la posición actual en los benchmarks. La cadencia de lanzamiento de 41 días entre Opus 4.7 y 4.8 de Anthropic forma parte de esa señal de velocidad.
La posición de Google también vale la pena seguir. La plataforma de agentes empresariales Gemini Enterprise es un competidor serio para cargas de trabajo multimodales donde las capacidades nativas de Gemini 3.1 Pro siguen siendo superiores. La diferencia en SWE-Bench Pro no significa que Gemini pierda en todas las categorías de cargas de trabajo: significa que Anthropic tiene la ventaja más clara en tareas adyacentes al código en este momento.
Y para los equipos que todavía consideran las decisiones de arquitectura de OpenAI como la elección empresarial predeterminada: la diferencia en los benchmarks es real y suficientemente grande como para requerir una explicación ante su liderazgo de ingeniería si no están ejecutando al menos una evaluación comparativa.
Preguntas frecuentes
¿Deberíamos cambiar de GPT-5.5 a Claude Opus 4.8? El argumento de los benchmarks es sólido: una diferencia de 10,6 puntos en SWE-Bench Pro no es ruido. Pero la respuesta correcta depende de su carga de trabajo. Ejecute la prueba de re-evaluación del modelo anterior, específicamente la pregunta 1 (¿la ventaja se mantiene en sus tareas reales?) y la pregunta 5 (¿cuál es su costo de cambio?). Si ambas respuestas son favorables, una migración controlada de una carga de trabajo en producción es el paso correcto, no un cambio total de plataforma.
¿Qué significa una valoración de 965.000 millones de dólares para el riesgo empresarial? Cambia el perfil de riesgo del proveedor en dos formas. Primero, Anthropic ya no está en la categoría de "startup bien financiada que podría ser adquirida". Los co-inversores hyperscaler (Amazon, con 5.000 millones de dólares) tienen incentivos estructurales para mantenerla independiente y operativa. Segundo, con esta valoración, la infraestructura legal y de compras de Anthropic comenzará a parecerse más a la de un proveedor de software empresarial: mejores acuerdos de nivel de servicio (SLAs), acuerdos de procesamiento de datos (DPAs) y certificaciones de cumplimiento normativo. Pero verifique esto con su propio equipo legal antes de basarse en ello.
¿Qué es Mythos? Anthropic ha mencionado "Mythos" como una clase de modelo de próxima generación más allá de Opus 4.8, con disponibilidad más amplia en las próximas semanas. Aún no hay datos de benchmarks públicos. Trátelo como una señal de hoja de ruta, no como un compromiso de planificación.
Qué hacer esta semana
- Ejecute una evaluación de Opus 4.8 frente a sus dos tareas en producción más representativas. No confíe únicamente en los benchmarks publicados.
- Use las cinco preguntas de la prueba de re-evaluación del modelo en una sesión de 30 minutos con el CTO o el responsable de AI. Documente sus respuestas: serán útiles cuando Mythos se lance y deba decidir nuevamente.
- Verifique su infraestructura cloud actual frente a la disponibilidad en Bedrock / Vertex AI / Foundry. Si ha estado usando la disponibilidad en la nube como razón para mantener un modelo competidor, esa limitación puede ya no aplicar.
Más información
- Los sandboxes autohospedados y los túneles MCP de Anthropic: La decisión de arquitectura, la parte de perímetro e infraestructura; este artículo se enfoca en la decisión de selección del modelo
- El realineamiento del mercado de agentes de codificación AI de Gartner
- Google Antigravity 2 y la plataforma de agentes empresariales Gemini Enterprise
- Decisión de arquitectura CTO con OpenAI GPT-5.4
