More in
Berita AI di Tempat Kerja
OpenAI Membuka Iklan ChatGPT untuk Bisnis Kecil dengan Anggaran Berapa Pun
Jun 6, 2026
AI Ada di Mana-mana di Tempat Kerja. Hanya 1 dari 10 yang Menyatakan AI Benar-benar Mengubah Pekerjaan Mereka
Jun 6, 2026
Momen $10,5 Miliar Vibe Coding: AI Kini Memulai Sebagian Besar Pembangunan Perangkat Lunak Baru
Jun 6, 2026
AI Agent Kini Memiliki Akses Sistem Lebih Besar dari Karyawan Anda. Sedikit yang Sudah Diamankan
Jun 5, 2026
Bangun atau Beli AI Anda? Perhatikan Apa yang Dibeli Para Raksasa.
Jun 5, 2026
Uber Membatasi Pengeluaran AI Karyawan di $1.500 per Kursi Setelah Anggaran Jebol
Jun 5, 2026
Perintah Eksekutif AI Trump Bersifat Deregulasi. Risiko Kepatuhan Anda Tidak Berubah
Jun 4, 2026
AI Mendorong 220 Unicorn Turun di Bawah $1 Miliar. Perusahaan Pra-ChatGPT Menghadapi Tantangan Besar
Jun 4, 2026
Harga Token Turun 67% Tahun Ini. Tagihan AI Anda Tetap Naik
Jun 3, 2026
Bisnis Kecil yang Menggunakan AI Melaporkan Pendapatan Lebih Tinggi dan Jam Kerja Lebih Singkat
Jun 3, 2026
Bahasa Indonesia
Claude Opus 4.8 Ditambah Putaran Pendanaan $965 Miliar Mengubah Model Enterprise Default. Inilah Uji Re-Underwriting CTO
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dua hal terjadi pada 28 Mei 2026 yang diperlakukan sebagian besar pemimpin teknologi enterprise sebagai berita terpisah. Keduanya tidak.
Pengumuman Anthropic merilis Claude Opus 4.8 -- 41 hari setelah Opus 4.7 -- sekaligus menutup Series H senilai $65 miliar yang mendorong valuasi post-money perusahaan ke $965 miliar. Ini bukan sekadar peluncuran model dan putaran pendanaan. Ini adalah sinyal stabilitas vendor dan lompatan kemampuan yang mendarat pada hari yang sama. Bagi chief technology officer (CTO) yang membuat keputusan model enterprise enam bulan lalu, kedua informasi ini penting -- dan pertanyaan yang tepat bukan "model mana yang menang?" Melainkan, "apakah kita perlu mengevaluasi ulang hubungan vendor AI default kita sekarang?"
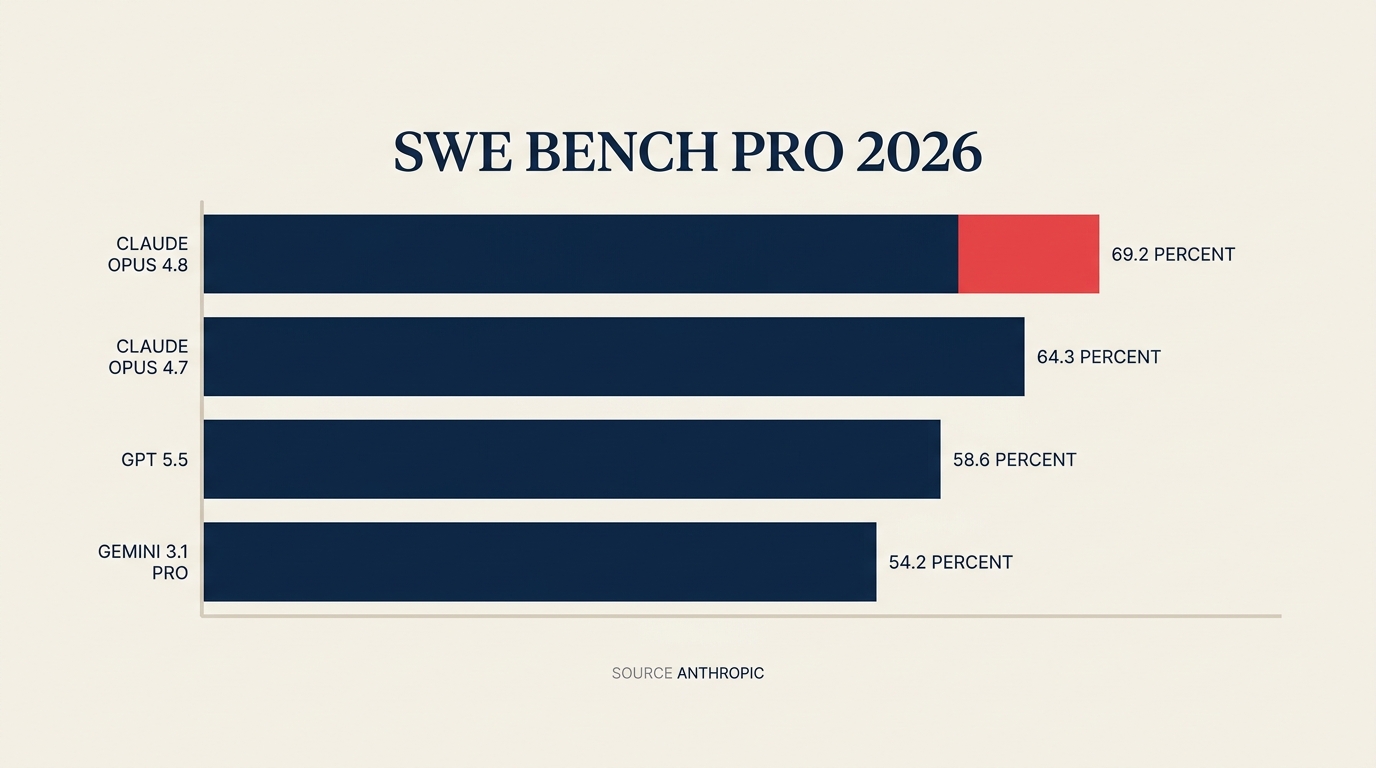
Menurut rilis Anthropic, Claude Opus 4.8 kini mendapat skor 69,2% pada SWE-Bench Pro, proksi industri yang paling mendekati pekerjaan rekayasa perangkat lunak produksi. GPT-5.5 mendapat skor 58,6% pada benchmark yang sama. Gemini 3.1 Pro berada di 54,2%. Ini bukan selisih kecil. Dan Anthropic mempertahankan harga identik dengan Opus 4.7: $5 per juta token input, $25 per juta token output.
Apa yang Baru Berubah, dan Mengapa Itu Memaksa Keputusan
Sebelum masuk ke kerangka, ada baiknya memperjelas apa yang "berubah." Tiga hal bergeser secara bersamaan: batas kemampuan, posisi keuangan vendor, dan luas permukaan penerapan.
Fakta Utama Claude Opus 4.8 mendapat skor 69,2% pada SWE-Bench Pro (benchmark rekayasa perangkat lunak) vs. GPT-5.5 di 58,6% dan Gemini 3.1 Pro di 54,2%. (Sumber: Anthropic) Valuasi post-money Anthropic tiga kali lipat dari $380 miliar pada Februari 2026 menjadi $965 miliar pada 28 Mei. (Sumber: TechCrunch) Pendapatan run-rate menembus $47 miliar lebih awal di Mei 2026 sebelum putaran ditutup. (Sumber: Anthropic)
Pada kemampuan: Opus 4.8 juga mendapat skor 88,6% pada SWE-bench Verified, 74,6% pada Terminal-Bench 2.1, dan 83,4% pada OSWorld-Verified computer use. Angka terakhir relevan bagi CTO mana pun yang membangun alur kerja otomatis yang menyentuh antarmuka desktop atau browser.
Pada posisi keuangan: Series H senilai $65 miliar mencakup $15 miliar yang sebelumnya dikomitmenkan dari hyperscaler -- $5 miliar dari Amazon saja -- ditambah investasi infrastruktur strategis dari Micron, Samsung, dan SK hynix. Ini bukan putaran perangkat lunak dengan komitmen infrastruktur simbolis. Ini adalah taruhan bahwa Anthropic akan mengendalikan bagian signifikan dari tumpukan komputasinya sendiri.
Pada luas permukaan penerapan: Opus 4.8 sudah berjalan hari ini di Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry, selain API langsung. Jika enterprise Anda terstandarisasi pada satu cloud dan menggunakannya sebagai alasan untuk tetap menggunakan model pesaing, alasan itu kini lebih lemah.
Semua ini tidak secara otomatis berarti Anda harus beralih. Namun ini berarti argumen untuk tidak meninjau keputusan Anda menjadi lebih sulit dipertahankan.
Uji Re-Underwriting Model

Sebagian besar keputusan model enterprise terjadi sekali lalu menua dengan tenang. Penerapan baru dimulai, tim rekayasa membangun kebiasaan di sekitar application programming interface (API) tertentu, dan biaya peralihan bertambah seiring waktu. Dinamika itu baik -- sampai ada rilis yang memaksa Anda memeriksa apakah keputusan awal masih berlaku.
Berikut kerangka lima pertanyaan untuk pemeriksaan tersebut:
1. Apakah model ini unggul pada pekerjaan Anda yang sebenarnya? Benchmark yang dipublikasikan adalah proksi. SWE-Bench Pro adalah proksi yang baik jika tim Anda melakukan rekayasa perangkat lunak -- ini menguji isu GitHub nyata, bukan teka-teki sintetis. Namun jika kasus penggunaan utama Anda adalah penelaahan kontrak, ringkasan dukungan pelanggan, atau analisis dokumen keuangan, jalankan evaluasi sendiri pada sampel tugas produksi Anda. Selisih benchmark 10 poin tidak otomatis berarti 10 poin pada beban kerja Anda.
2. Apakah vendor memiliki landasan finansial untuk mendukung kontrak multi-tahun? Valuasi $965 miliar dengan pendapatan run-rate $47 miliar dan suntikan tunai $65 miliar bukan profil risiko startup. Meski demikian, landasan keuangan kurang penting dibandingkan transparansi pengeluaran. Co-investor hyperscaler Anthropic punya insentif untuk menjaga perusahaan beroperasi -- itu adalah keselarasan yang berarti. Pertanyaannya adalah apakah tim hukum dan pengadaan Anda dapat menegosiasikan ketentuan yang mencerminkan tier baru ini.
3. Apakah model tersedia di seluruh jejak cloud Anda? Claude Opus 4.8 sudah berjalan di Bedrock, Vertex AI, dan Foundry hari ini. Jika beban kerja Anda tersebar di dua atau tiga hyperscaler dan pilihan model saat ini mengharuskan semua lalu lintas melalui satu endpoint cloud tunggal, Anda punya utang arsitektur yang rilis ini bisa bantu selesaikan.
4. Apakah orchestration agen vendor cocok dengan peta jalan Anda? Dynamic Workflows -- pratinjau penelitian yang dikirimkan dengan Opus 4.8 di Claude Code -- menjalankan puluhan hingga ratusan subagen paralel dari satu skrip orchestration dengan status yang dapat dilanjutkan. Ini kemampuan yang secara fundamental berbeda dari pipeline prompt-response. Jika peta jalan 12 bulan Anda mencakup agen otonom yang melakukan pekerjaan multi-langkah di seluruh basis kode atau kumpulan data besar, lapisan orchestration sama pentingnya dengan kualitas model dasar. Kami membahas arsitektur dan keputusan perimeter secara terpisah dalam artikel kami tentang self-hosted sandbox dan MCP tunnel Anthropic -- pertanyaan ini secara khusus tentang apakah model orchestration cocok dengan beban kerja agentic Anda.
5. Apa biaya dan risiko kembali jika Anda berpindah? Ini adalah pertanyaan yang paling sering dilewati tim. Jika Anda bermigrasi dari model saat ini ke Opus 4.8, seperti apa rollback dalam 12 bulan jika rilis pesaing menggeser gambaran benchmark kembali? Biaya peralihan large language model (LLM) mencakup rekayasa ulang prompt, pembangunan ulang fine-tune, pengujian integrasi, dan pelatihan ulang tim yang menggunakan alat tersebut. Ini bukan hal yang mustahil -- tetapi perlu diperhitungkan.
Jika jawaban jujur Anda adalah: "ya, model ini unggul pada pekerjaan kami; ya, vendor stabil; ya, model ini mencakup cloud kami; ya, lapisan agen cocok dengan peta jalan kami; dan biaya peralihan dapat diterima" -- maka pertanyaannya menjadi kapan bermigrasi, bukan apakah perlu.
Sinyal Mythos
Anthropic juga menyebutkan -- tanpa tanggal pasti -- bahwa model "kelas Mythos" akan tersedia bagi semua pelanggan dalam beberapa minggu mendatang. Ini layak dicatat untuk perencanaan CTO, tetapi tidak seharusnya menunda keputusan tentang Opus 4.8.
Jika Mythos hadir dalam empat hingga enam minggu dan uji re-underwriting di atas sudah mengarah ke Anthropic, urutannya sederhana: pindahkan beban kerja ke Opus 4.8 sekarang, perlakukan Mythos sebagai potensi peningkatan lebih lanjut, dan jangan biarkan logika "ada yang lebih baik segera hadir" menjadi alasan untuk tetap menggunakan model yang lebih lemah selama satu kuartal lagi. Logika itu hampir tidak pernah menghasilkan arah yang benar.
Konteks Kompetitif
Sinyal realignment Gartner yang kami bahas dalam pergeseran pasar AI coding agent relevan di sini: firma analis sudah menyesuaikan tier vendor AI enterprise mereka berdasarkan kecepatan kemampuan, bukan hanya posisi benchmark saat ini. Kecepatan rilis Anthropic 41 hari antara Opus 4.7 dan 4.8 adalah bagian dari sinyal kecepatan tersebut.
Posisi Google juga layak dipantau. Platform agen enterprise Gemini adalah pesaing serius untuk beban kerja multimodal di mana kemampuan native Gemini 3.1 Pro masih unggul. Selisih SWE-Bench Pro tidak berarti Gemini kalah di setiap kategori beban kerja -- artinya Anthropic memiliki keunggulan paling jelas pada tugas-tugas yang berdekatan dengan kode saat ini.
Dan bagi tim yang masih menjalankan keputusan arsitektur OpenAI sebagai pilihan enterprise default: selisih benchmark nyata dan cukup besar sehingga membutuhkan penjelasan kepada kepemimpinan rekayasa Anda jika Anda tidak setidaknya menjalankan evaluasi komparatif.
FAQ
Haruskah kami beralih dari GPT-5.5 ke Claude Opus 4.8? Argumen benchmark kuat -- selisih 10,6 poin pada SWE-Bench Pro bukan sekadar kebisingan. Namun jawaban yang tepat bergantung pada beban kerja Anda. Jalankan Uji Re-Underwriting Model di atas, khususnya pertanyaan 1 (apakah keunggulan bertahan pada tugas nyata Anda?) dan pertanyaan 5 (berapa biaya peralihan Anda?). Jika kedua jawaban menguntungkan, migrasi terkontrol dari satu beban kerja produksi adalah langkah berikutnya yang tepat -- bukan peralihan platform menyeluruh.
Apa arti valuasi $965 miliar bagi risiko enterprise? Ini mengubah profil risiko vendor dalam dua cara. Pertama, Anthropic tidak lagi berada dalam kategori "startup berdanaan baik yang bisa diakuisisi." Co-investor hyperscaler (Amazon, dengan $5 miliar) punya insentif struktural untuk menjaganya independen dan beroperasi. Kedua, pada valuasi ini, infrastruktur hukum dan pengadaan Anthropic akan mulai terlihat lebih seperti vendor perangkat lunak enterprise -- artinya perjanjian tingkat layanan (SLA), perjanjian pemrosesan data (DPA), dan sertifikasi kepatuhan yang lebih baik. Tetapi verifikasi ini dengan tim hukum Anda sendiri sebelum mengandalkannya.
Apa itu Mythos? Anthropic telah merujuk "Mythos" sebagai kelas model generasi berikutnya melampaui Opus 4.8, dengan ketersediaan lebih luas yang datang dalam beberapa minggu. Belum ada data benchmark publik. Perlakukan sebagai sinyal peta jalan, bukan komitmen perencanaan.
Yang Harus Dilakukan Minggu Ini
- Jalankan evaluasi benchmark Opus 4.8 terhadap dua tugas produksi paling representatif Anda. Jangan hanya mengandalkan benchmark yang dipublikasikan.
- Gunakan Uji Re-Underwriting Model lima pertanyaan dalam sesi CTO atau Head of AI selama 30 menit. Dokumentasikan jawaban Anda -- ini akan berguna ketika Mythos hadir dan Anda perlu memutuskan lagi.
- Periksa jejak cloud Anda saat ini terhadap ketersediaan Bedrock / Vertex AI / Foundry. Jika Anda telah menggunakan ketersediaan cloud sebagai alasan untuk tetap menggunakan model pesaing, hambatan tersebut mungkin tidak lagi berlaku.
Pelajari Lebih Lanjut
- Self-Hosted Sandbox dan MCP Tunnel Anthropic: Keputusan Arsitektur -- bagian perimeter dan infrastruktur; artikel ini berfokus pada keputusan pemilihan model
- Realignment Pasar AI Coding Agent Gartner
- Google Antigravity 2 dan Platform Agen Enterprise Gemini
- Keputusan Arsitektur CTO OpenAI GPT-5.4
