More in
AI bei der Arbeit: Neuigkeiten
OpenAI hat ChatGPT-Werbung für kleine Unternehmen ohne Mindestbudget geöffnet
Juni 6, 2026
AI ist überall im Arbeitsalltag. Nur 1 von 10 sagt, sie hat den Job grundlegend verändert
Juni 6, 2026
Vibe Codings 10,5-Mrd.-USD-Moment: AI startet jetzt die meisten neuen Software-Projekte
Juni 6, 2026
AI Agents haben jetzt mehr Systemzugriff als Ihre Mitarbeiter. Die wenigsten sind abgesichert
Juni 5, 2026
Selbst bauen oder kaufen? Beobachten Sie, was die Branchenriesen erworben haben.
Juni 5, 2026
Uber begrenzt die AI-Ausgaben pro Mitarbeiter auf 1.500 USD nach einem Budget-Überschuss
Juni 5, 2026
Trumps AI-Dekret ist deregulatorisch. Ihr Compliance-Risiko hat sich nicht verändert
Juni 4, 2026
AI hat 220 Einhörner unter 1 Mrd. USD gedrückt. Unternehmen aus der Vor-ChatGPT-Ära stehen vor einer Abrechnung
Juni 4, 2026
Token-Preise fielen in diesem Jahr um 67 %. Ihre AI-Rechnung steigt trotzdem
Juni 3, 2026
Kleine Unternehmen, die AI einsetzen, berichten von höheren Umsätzen und kürzeren Arbeitstagen
Juni 3, 2026
Claude Opus 4.8 plus eine 965-Mrd.-USD-Runde verändern das Standard-Unternehmensmodell. Hier ist der CTO-Neubewertungstest
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Am 28. Mai 2026 geschahen zwei Dinge, die die meisten Technologieführer in Unternehmen als separate Nachrichten behandeln. Das sind sie nicht.
Anthropics Ankündigung brachte Claude Opus 4.8 auf den Markt, 41 Tage nach Opus 4.7, und schloss gleichzeitig eine 65-Mrd.-USD-Series-H-Runde ab, die die Post-Money-Bewertung des Unternehmens auf 965 Mrd. USD trieb. Das ist kein Modell-Release und eine Finanzierungsrunde. Das sind ein Anbieter-Stabilitätssignal und ein Fähigkeitssprung, die am selben Tag eintreffen. Für Chief Technology Officers (CTOs), die vor sechs Monaten eine Unternehmensmodell-Entscheidung getroffen haben, sind beide Neuigkeiten relevant. Die richtige Frage lautet nicht: „Welches Modell gewinnt?" Sondern: „Müssen wir unsere Standard-AI-Anbieterbeziehung jetzt neu bewerten?"
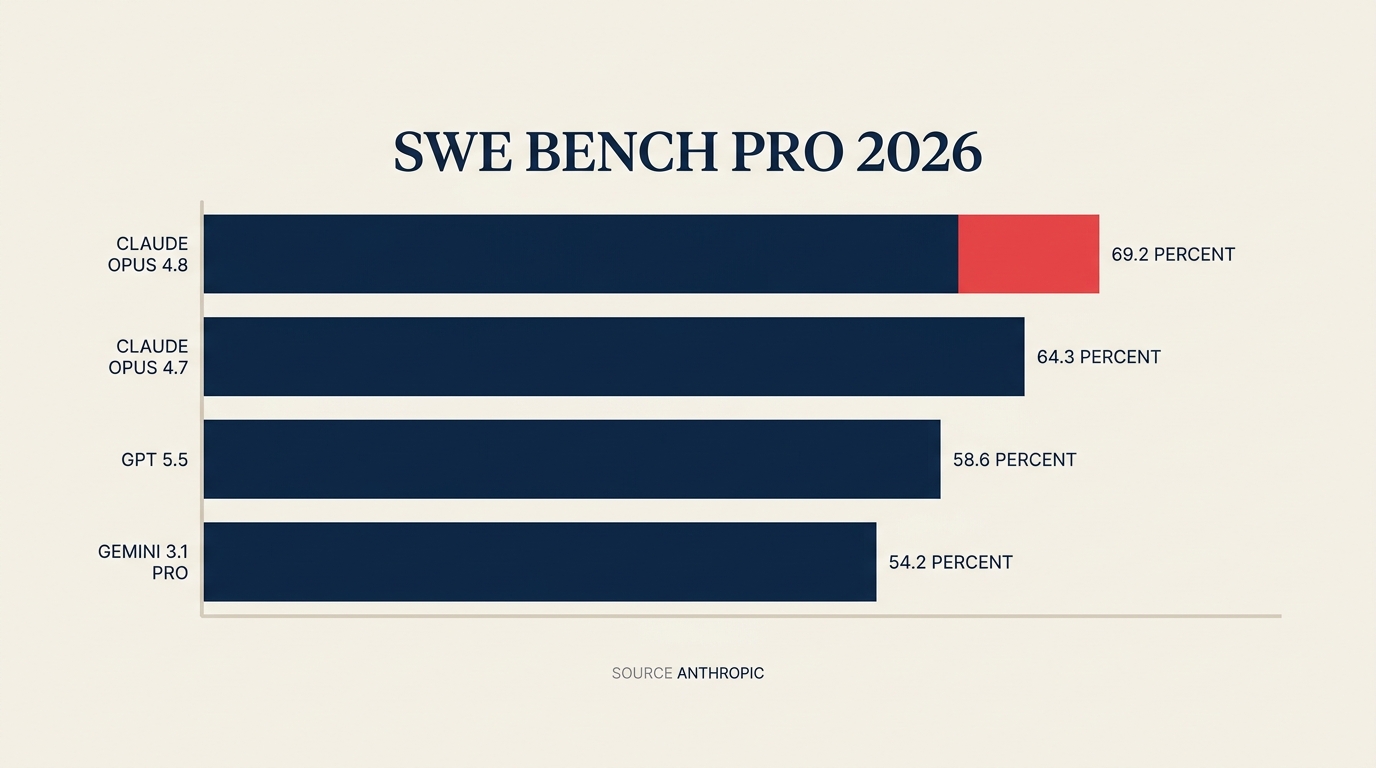
Laut Anthropics Release erzielt Claude Opus 4.8 nun 69,2 % auf SWE-Bench Pro, dem branchennächsten Proxy für produktive Software-Engineering-Arbeit. GPT-5.5 erzielt auf demselben Benchmark 58,6 %. Gemini 3.1 Pro liegt bei 54,2 %. Das ist kein marginaler Abstand. Und Anthropic hat die Preisgestaltung identisch zu Opus 4.7 beibehalten: 5 USD pro Million Input-Token, 25 USD pro Million Output-Token.
Was sich gerade geändert hat und warum es eine Entscheidung erfordert
Bevor wir zum Framework kommen, lohnt es sich, präzise zu sein, was sich „geändert" hat. Drei Dinge haben sich gleichzeitig verschoben: Fähigkeitsobergrenze, finanzielle Position des Anbieters und Bereitstellungsfläche.
Key Facts Claude Opus 4.8 erzielt 69,2 % auf SWE-Bench Pro (Software-Engineering-Benchmark) gegenüber GPT-5.5 mit 58,6 % und Gemini 3.1 Pro mit 54,2 %. (Quelle: Anthropic) Anthropics Post-Money-Bewertung hat sich von 380 Mrd. USD im Februar 2026 auf 965 Mrd. USD am 28. Mai verdreifacht. (Quelle: TechCrunch) Der Umsatz auf Laufbasis überschritt Anfang Mai 2026 47 Mrd. USD, bevor die Runde abgeschlossen wurde. (Quelle: Anthropic)
Zu den Fähigkeiten: Opus 4.8 erzielt auch 88,6 % auf SWE-bench Verified, 74,6 % auf Terminal-Bench 2.1 und 83,4 % auf OSWorld-Verified für die Computer-Nutzung. Diese letzte Zahl ist für jeden CTO relevant, der automatisierte Workflows entwickelt, die Desktop- oder Browser-Schnittstellen berühren.
Zur finanziellen Position: Die 65-Mrd.-USD-Series H umfasst 15 Mrd. USD, die zuvor von Hyperscalern zugesagt wurden, davon 5 Mrd. USD allein von Amazon, sowie strategische Infrastrukturinvestitionen von Micron, Samsung und SK hynix. Das ist keine Software-Runde mit symbolischen Infrastrukturverpflichtungen. Es ist eine Wette darauf, dass Anthropic bedeutende Teile seines eigenen Compute-Stacks kontrolliert.
Zur Bereitstellungsfläche: Opus 4.8 ist heute auf Amazon Bedrock, Google Cloud Vertex AI und Microsoft Foundry sowie über die direkte API verfügbar. Wenn Ihr Unternehmen auf eine einzelne Cloud standardisiert hat und dies als Grund verwendet hat, bei einem konkurrierenden Modell zu bleiben, ist dieser Grund jetzt schwächer.
Das bedeutet nicht automatisch, dass Sie wechseln sollten. Aber es bedeutet, dass das Argument, Ihre Entscheidung nicht zu überprüfen, schwerer zu machen ist.
Der Modell-Neubewertungstest

Die meisten Unternehmensmodell-Entscheidungen werden einmal getroffen und veralten dann still. Eine neue Bereitstellung beginnt, Engineering-Teams entwickeln Gewohnheiten rund um eine bestimmte Programmierschnittstelle (API), und die Wechselkosten häufen sich im Laufe der Zeit an. Diese Dynamik ist in Ordnung, bis ein Release Sie zwingt zu prüfen, ob die ursprüngliche Entscheidung noch gilt.
Hier ist das Fünf-Fragen-Framework für diese Prüfung:
1. Führt dieses Modell bei Ihrer tatsächlichen Arbeit? Veröffentlichte Benchmarks sind Näherungswerte. SWE-Bench Pro ist ein guter, wenn Ihre Teams Software-Engineering betreiben. Er testet echte GitHub-Issues, keine synthetischen Rätsel. Wenn Ihr primärer Anwendungsfall jedoch Vertragsüberprüfung, Zusammenfassung des Kundensupports oder Analyse von Finanzdokumenten ist, führen Sie Ihre eigene Bewertung an einer Stichprobe Ihrer Produktionsaufgaben durch. Ein 10-Punkte-Benchmark-Abstand übersetzt sich nicht automatisch in 10 Punkte bei Ihrer Arbeitslast.
2. Verfügt der Anbieter über die finanzielle Tragfähigkeit für mehrjährige Verträge? Eine Bewertung von 965 Mrd. USD mit 47 Mrd. USD Umsatz auf Laufbasis und einem Cash-Zufluss von 65 Mrd. USD entspricht nicht dem Risikoprofil eines Startups. Dennoch ist die Transparenz beim Kapitalverbrauch wichtiger als die finanzielle Reichweite allein. Anthropics Hyperscaler-Co-Investoren haben ein strukturelles Interesse daran, das Unternehmen operativ zu halten. Die Frage ist, ob Ihre Rechts- und Beschaffungsteams Konditionen aushandeln können, die diesem neuen Niveau entsprechen.
3. Ist das Modell über Ihren gesamten Cloud-Bestand verfügbar? Claude Opus 4.8 ist heute auf Bedrock, Vertex AI und Foundry verfügbar. Wenn Ihre Workloads zwei oder drei Hyperscaler umfassen und Ihre aktuelle Modellwahl erfordert, dass alles über einen einzelnen Cloud-Endpunkt geleitet wird, haben Sie Architekturschulden, die diese Version helfen könnte abzubauen.
4. Entspricht die Agent-Orchestrierung des Anbieters Ihrer Roadmap? Dynamic Workflows, die Forschungsvorschau, die mit Opus 4.8 in Claude Code ausgeliefert wird, führen Dutzende bis Hunderte paralleler Subagenten aus einem einzigen Orchestrierungsskript mit wiederaufnehmbarem Zustand aus. Das ist eine grundlegend andere Fähigkeit als Prompt-Antwort-Pipelines. Wenn Ihre 12-Monats-Roadmap autonome Agents umfasst, die mehrstufige Arbeit über große Codebasen oder Datensätze hinweg ausführen, ist die Orchestrierungsschicht genauso wichtig wie die Basismodellqualität. Wir haben die Architektur- und Perimeterentscheidungen separat in unserem Beitrag zu Anthropics Self-Hosted-Sandboxes und MCP-Tunneln behandelt. Diese Frage betrifft konkret, ob das Orchestrierungsmodell zu Ihren agentischen Workloads passt.
5. Was sind die Kosten und Risiken eines Rückwechsels, wenn Sie wechseln? Das ist die Frage, die die meisten Teams überspringen. Wenn Sie von Ihrem aktuellen Modell zu Opus 4.8 migrieren, wie sieht ein Rollback in 12 Monaten aus, wenn eine konkurrierende Version das Benchmark-Bild wieder verändert? LLM-Wechselkosten umfassen Prompt-Neugestaltung, Neuaufbau von Fine-Tuning, Integrationstests und Umschulung der Teams, die die Tools verwenden. Das sind keine unüberwindbaren Hürden, aber sie müssen in der Kalkulation berücksichtigt werden.
Wenn Ihre ehrlichen Antworten lauten: „Ja, es führt bei unserer Arbeit; ja, der Anbieter ist stabil; ja, es deckt unsere Clouds ab; ja, die Agent-Schicht passt zu unserer Roadmap; und die Wechselkosten sind akzeptabel" dann wird die Frage nicht ob, sondern wann Sie migrieren.
Das Mythos-Signal
Anthropic erwähnte auch, ohne konkretes Datum, dass ein „Mythos-Klasse"-Modell in den kommenden Wochen für alle Kunden verfügbar sein wird. Das ist für die CTO-Planung erwähnenswert, sollte aber eine Entscheidung zu Opus 4.8 nicht verzögern.
Wenn Mythos in vier bis sechs Wochen erscheint und der obige Neubewertungstest bereits auf Anthropic hindeutet, ist die Reihenfolge einfach: Workloads jetzt auf Opus 4.8 verschieben, Mythos als potenzielles weiteres Upgrade behandeln und nicht zulassen, dass „etwas Besseres kommt" ein Grund wird, ein weiteres Quartal bei einem schwächeren Modell zu bleiben. Diese Logik löst sich fast nie in die richtige Richtung auf.
Wettbewerbskontext
Das Gartner-Neuausrichtungssignal, das wir im Beitrag zu AI-Coding-Agent-Marktverschiebungen behandelt haben, ist hier relevant: Analystenunternehmen passen ihre Unternehmens-AI-Anbieter-Tiers bereits basierend auf der Fähigkeitsgeschwindigkeit an, nicht nur auf der aktuellen Benchmark-Position. Anthropics 41-Tage-Release-Kadenz zwischen Opus 4.7 und 4.8 ist Teil dieses Geschwindigkeitssignals.
Googles Position ist ebenfalls beobachtenswert. Geminis Enterprise-Agent-Plattform ist ein ernsthafter Konkurrent für multimodale Workloads, bei denen Gemini 3.1 Pros native Fähigkeiten noch führen. Der SWE-Bench-Pro-Abstand bedeutet nicht, dass Gemini in jeder Workload-Kategorie verliert, sondern dass Anthropic derzeit den klarsten Vorsprung bei code-nahen Aufgaben hat.
Für Teams, die OpenAIs Architekturentscheidungen noch als Standard-Unternehmensauswahl betreiben: Der Benchmark-Abstand ist real und groß genug, um Ihrer Engineering-Führungsebene eine Erklärung zu schulden, wenn Sie nicht zumindest eine vergleichende Bewertung durchführen.
Häufig gestellte Fragen
Sollten wir von GPT-5.5 zu Claude Opus 4.8 wechseln? Der Benchmark-Fall ist stark. Ein 10,6-Punkte-Abstand auf SWE-Bench Pro ist kein Rauschen. Die richtige Antwort hängt jedoch von Ihrer Arbeitslast ab. Führen Sie den oben beschriebenen Modell-Neubewertungstest durch, insbesondere Frage 1 (hält der Vorsprung bei Ihren tatsächlichen Aufgaben?) und Frage 5 (wie hoch sind Ihre Wechselkosten?). Wenn beide Antworten günstig sind, ist eine kontrollierte Migration einer Produktions-Workload der richtige nächste Schritt, kein vollständiger Plattformwechsel.
Was bedeutet eine Bewertung von 965 Mrd. USD tatsächlich für das Unternehmensrisiko? Sie verändert das Anbieter-Risikoprofil auf zwei Arten. Erstens ist Anthropic nicht mehr in der Kategorie „gut finanziertes Startup, das übernommen werden könnte". Die Hyperscaler-Co-Investoren (Amazon, mit 5 Mrd. USD) haben ein strukturelles Interesse daran, es unabhängig und operativ zu halten. Zweitens wird Anthropics Rechts- und Beschaffungsinfrastruktur bei dieser Bewertung anfangen, mehr wie die eines Enterprise-Software-Anbieters auszusehen, was bessere Service Level Agreements (SLAs), Datenverarbeitungsverträge und Compliance-Zertifizierungen bedeutet. Verifizieren Sie dies jedoch mit Ihrem eigenen Rechtsteam, bevor Sie sich darauf verlassen.
Was ist Mythos? Anthropic hat „Mythos" als eine Modellklasse der nächsten Generation jenseits von Opus 4.8 erwähnt, mit breiterer Verfügbarkeit in einigen Wochen. Es sind noch keine Benchmark-Daten öffentlich. Behandeln Sie es als Roadmap-Signal, nicht als Planungsverpflichtung.
Was Sie diese Woche tun sollten
- Führen Sie eine Benchmark-Bewertung von Opus 4.8 anhand Ihrer zwei repräsentativsten Produktionsaufgaben durch. Verlassen Sie sich nicht allein auf veröffentlichte Benchmarks.
- Verwenden Sie den Fünf-Fragen-Modell-Neubewertungstest in einer 30-minütigen CTO- oder Head-of-AI-Sitzung. Dokumentieren Sie Ihre Antworten. Sie werden nützlich sein, wenn Mythos erscheint und Sie erneut entscheiden müssen.
- Prüfen Sie Ihren aktuellen Cloud-Bestand gegenüber der Verfügbarkeit auf Bedrock / Vertex AI / Foundry. Wenn Sie die Cloud-Verfügbarkeit als Grund verwendet haben, bei einem konkurrierenden Modell zu bleiben, gilt diese Einschränkung möglicherweise nicht mehr.
Mehr erfahren
- Anthropics Self-Hosted-Sandboxes und MCP-Tunnel: Die Architekturentscheidung -- der Perimeter- und Infrastrukturteil; dieser Artikel konzentriert sich auf die Modellauswahl-Entscheidung
- Gartners AI-Coding-Agent-Markt-Neuausrichtung
- Google Antigravity 2 und die Gemini Enterprise Agent Platform
- OpenAI GPT-5.4 CTO-Architekturentscheidung
