AI Incident Response Playbook: How to Respond When AI Fails

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
An AI chatbot tells a customer they're owed a refund they're not owed. An AI summarizer omits a critical contract clause during a due diligence review, and the omission isn't caught until after signing. An AI lead scoring model starts routing your highest-value prospects to the wrong reps, and nobody notices for three weeks.
These are AI incidents. And they're different from the IT incidents your team already knows how to handle.
Does your incident response process know the difference? If not, you'll respond too slowly to the wrong signals, escalate the wrong things, and miss the problems that are quietly affecting hundreds of decisions before anyone notices.
This playbook is for chief information officers (CIOs), security leads, and transformation teams building their first AI-specific incident response capability, or auditing whether their existing process is adequate. It connects to Building Your AI Use Policy (which defines authorized AI scope) and Audit Trails for AI Execute Actions (which provides the evidence base for investigation).
How AI incidents differ from IT incidents
Key Facts: AI Incident Risk
- GDPR Article 33 requires notification to the relevant supervisory authority within 72 hours of becoming aware of a personal data breach; the 72-hour clock starts when the organization becomes aware, not when the investigation is complete (GDPR Article 33)
- AI incident categories include hallucination, Execute error, bias, data exposure, and model drift; traditional IT incident response (built around binary up/down failures) misses the latent, probabilistic nature of AI failures that can affect hundreds of decisions before detection (NIST Cybersecurity Framework research)
- Gartner predicts that over 40% of agentic AI projects will be canceled by 2027, with governance frameworks failing to keep pace as the leading cause; incident response infrastructure is one of the three most commonly absent governance components (Gartner, 2025)
Traditional IT incident response is built around a simple model: systems are either up or down. A server goes offline, a service returns a 500 error, a network link fails. The incident is binary and immediate. Detection is fast, usually automated. The fix is technical: restore the service.
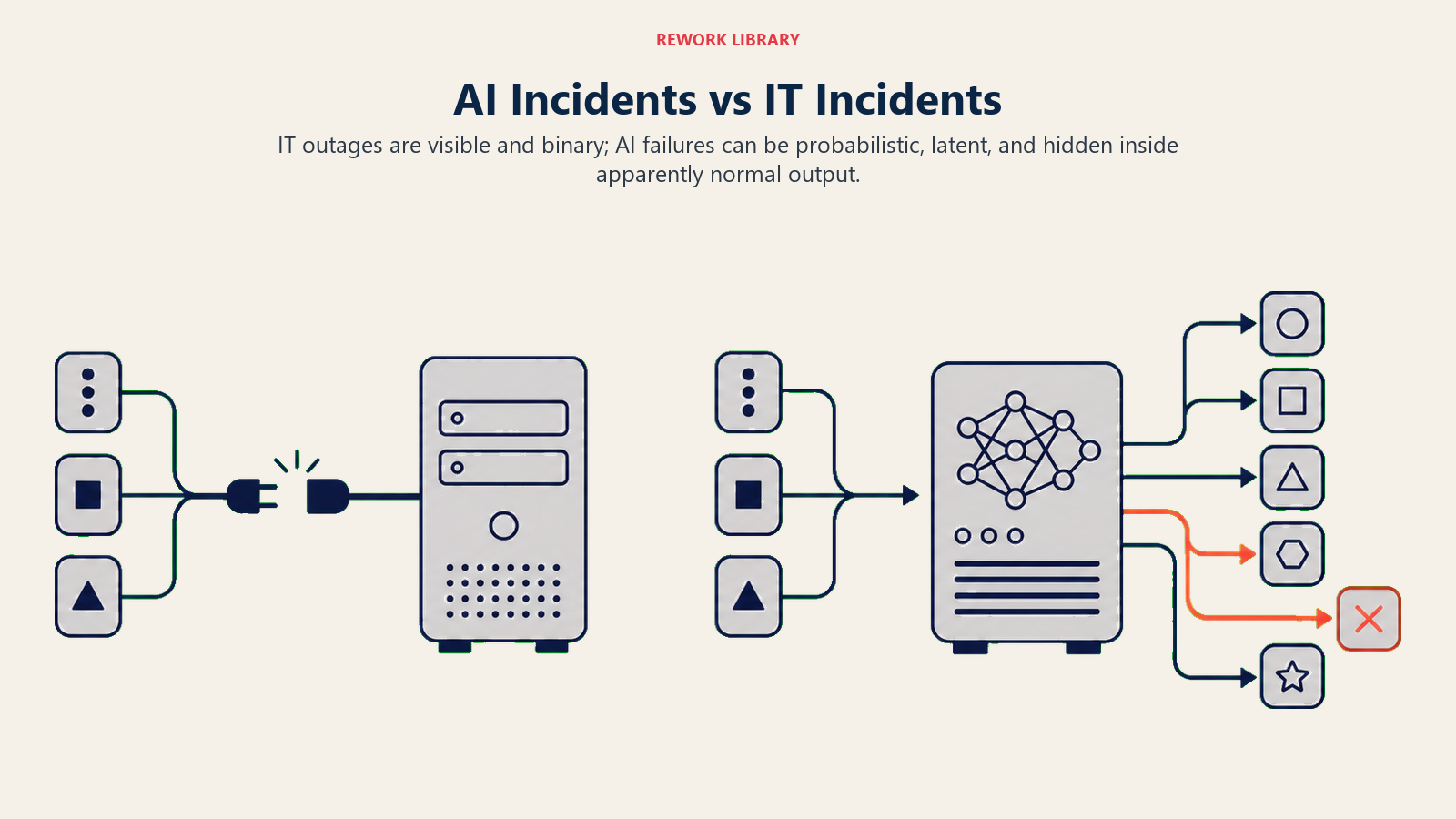
AI incidents don't work that way. The NIST Cybersecurity Framework's Respond function describes incident response as containing and managing impacts of detected events, but the CSF was designed around binary, detectable technical failures. AI incidents require a significantly different detection and response model.
They're probabilistic. An AI system that's working "fine" most of the time may be making incorrect decisions for a specific subpopulation of inputs: a particular customer segment, a particular document type, a particular language. The overall accuracy metrics look acceptable. The tail is failing badly.
They're latent. A biased scoring model, a hallucinating knowledge base, a prompt injection vulnerability, these can operate for weeks or months before anyone notices. The IT incident analogy would be a server that's silently corrupting data 3% of the time rather than crashing outright.
They're often invisible until they're consequential. An AI that sends wrong information to customers, makes discriminatory decisions in hiring, or leaks data into a prompt context doesn't generate a 500 error. It may generate a customer complaint, a regulator inquiry, or a journalist's call. This is one of the governance failure modes that derails otherwise well-funded AI transformations.
The root cause is harder to find. IT incidents have technical root causes: a misconfiguration, a code bug, a hardware failure. AI incidents can result from model behavior (the model was always going to fail on this input type), prompt design (the prompt is inconsistent in certain edge cases), data quality (the training or retrieval data was wrong), integration failure (the right output was generated but the wrong action was executed), or user behavior (humans started using the tool in a way it wasn't designed for).
Each root cause type requires a different response.
"AI incidents don't announce themselves with a 500 error. A biased scoring model can operate for months before anyone notices. An AI that sends wrong information to customers doesn't crash. It generates a customer complaint. The incident response process that works for IT outages will miss the majority of AI failures until they become crises." (Rework)
The 4-Type AI Incident Taxonomy
A classification framework for categorizing AI incidents by root cause type, enabling faster diagnosis and more targeted response. Type 1 (Hallucination): AI generated factually incorrect content that was acted on. Type 2 (Execute Error): AI took a consequential action incorrectly, with real-world consequences. Type 3 (Bias): AI made systematically discriminatory decisions affecting a subpopulation; highest regulatory exposure. Type 4 (Data Exposure): prompt input or AI output revealed information that should have been protected; may trigger GDPR Article 33 72-hour notification obligation. Type 5 (Model Drift): AI performance has degraded over time without a single detectable failure moment; the most commonly missed incident type. Each type has a distinct detection signal, response timeline, and root cause investigation approach. Using the wrong response protocol for the incident type produces slower resolution and may miss systemic issues.
AI incident taxonomy
Before you can respond to an AI incident, you need to know what kind of incident you have.
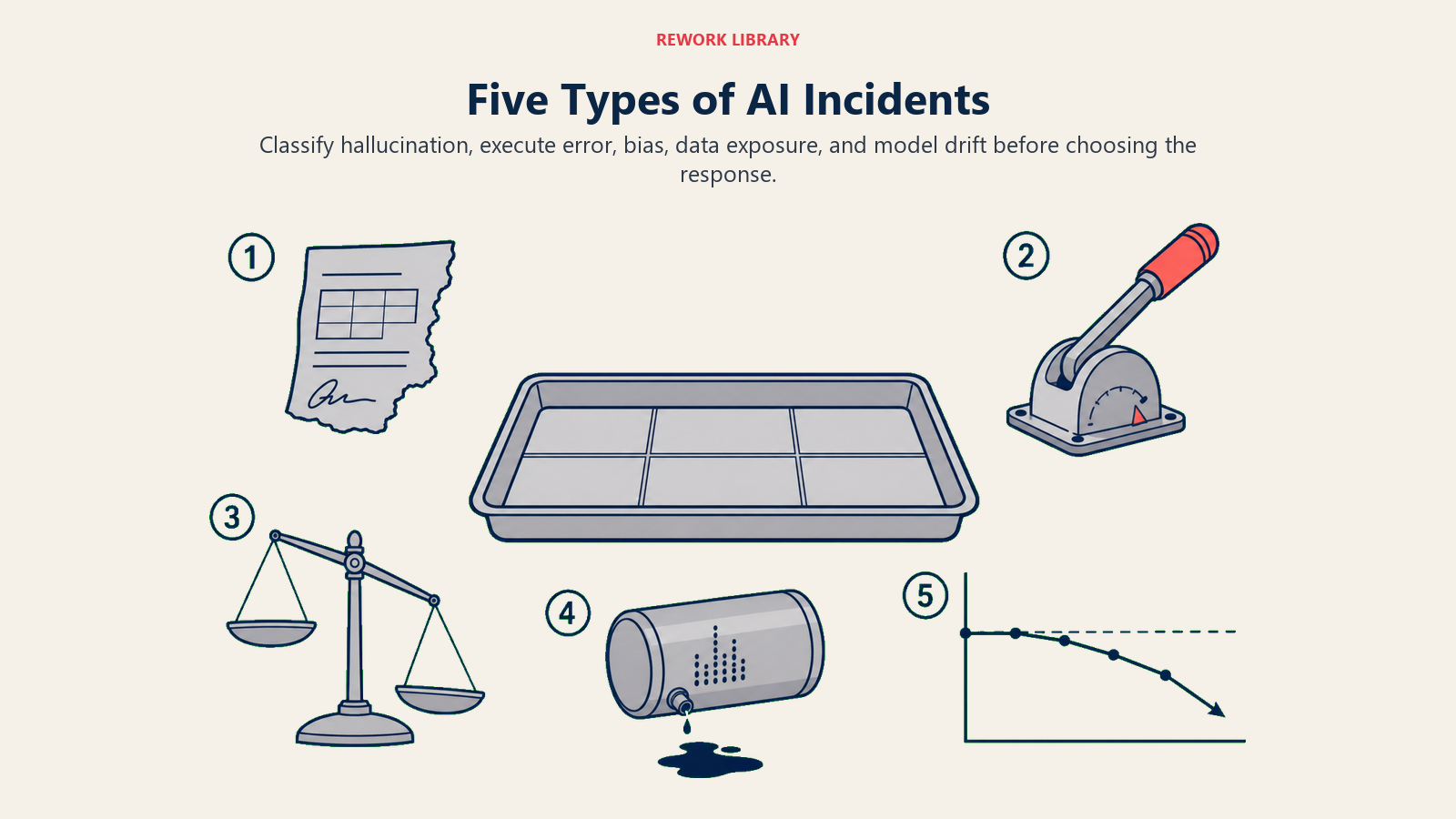
Type 1: Hallucination incident
The AI generated factually incorrect content that was acted on. A customer received wrong information about their policy coverage. A support agent used an AI-generated answer to resolve a ticket incorrectly. An AI-written document contained fabricated citations.
Detection signal: customer complaint, internal quality review, employee report, downstream system error caused by acting on incorrect information.
Key questions in response: Was the output reviewed before it was used? Was this a one-off or does the model consistently hallucinate on this type of question? Is there a prompt change that would fix it?
Type 2: Execute error
The AI took a consequential action incorrectly. This is the most time-sensitive incident type, because Execute actions change the state of the world. Wrong refund issued. Email sent to wrong recipient list. CRM records updated with incorrect data. Workflow triggered that shouldn't have been.
Detection signal: customer complaint, financial reconciliation discrepancy, downstream process error, employee report.
Key questions in response: Can the action be reversed? If so, who is authorized to reverse it and how? Who was affected? Is the root cause in the AI model, the trigger logic, or the integration between AI output and the external system?
Type 3: Bias incident
The AI made systematically discriminatory decisions. A scoring model disproportionately routed candidates of a certain demographic to rejection. A credit-adjacent AI declined applications at different rates for protected classes. A hiring AI filtered out candidates based on factors correlated with protected characteristics.
Detection signal: demographic audit of outcomes, employee report, regulator inquiry, legal challenge from an affected individual.
Key questions in response: How long was the system operating with this bias? How many individuals were affected? What remediation is owed to affected parties? Is this model still in production?
This incident type has the most severe regulatory exposure. Legal counsel must be involved immediately.
Type 4: Data exposure incident
Prompt input or AI output revealed information that should have been protected. Customer A's information appeared in Customer B's AI response. An employee's personal data was included in a prompt context accessible to unauthorized users. Confidential internal data was sent to a vendor's AI system that was not authorized to receive it.
Detection signal: customer complaint about seeing another user's data, internal audit, employee report, monitoring alert on data classification violations.
Key questions in response: What data was exposed? To whom? Was it personally identifiable information (PII), protected health information (PHI), financial data, or confidential business data? Was this a one-time event or a systematic flaw?
GDPR Article 33 note: if the exposure involved personal data of EU residents, you may have a 72-hour notification obligation to the relevant supervisory authority. This is not optional. The clock starts when you become aware of the incident, not when you complete the investigation.
Type 5: Model drift
AI performance has degraded over time without anyone noticing. The scoring model that was 78% accurate in Q1 is at 61% accuracy in Q3. The retrieval system that was returning correct documents is now returning outdated ones. The generation quality that was acceptable has degraded as the model or retrieval context has changed.
Detection signal: monitoring metrics (if you've built them), business outcome metrics (lead conversion rate declining, customer satisfaction dropping, support ticket resolution quality declining), employee reports that the AI "isn't as good as it used to be."
This is the incident type most often missed because there's no single moment of failure. It accumulates.
The 4-tier response framework
The tiering model gives teams a shared escalation path before an AI incident becomes a cross-functional scramble.

Once you've identified the incident type, the tier determines who responds, how fast, and what happens first.
Tier 4: Investigate
Criteria: Internal AI output error, no external exposure, no customer impact yet. A hallucination discovered during internal quality review. A Generate output that was incorrect but not acted on. Model drift detected by internal monitoring before it affected outcomes.
Response window: 24 hours to initial assessment.
Who responds: The team responsible for the AI system. No escalation required unless assessment reveals external exposure.
Actions: Document the incident in the AI risk register. Determine root cause. Assess whether the issue is systemic or isolated. Implement fix or workaround. Schedule post-incident review.
Tier 3: Contain
Criteria: Customer-facing incorrect output that wasn't acted on by the customer. A chatbot response that was wrong but the customer didn't act on it. A draft email with incorrect information that was caught before sending.
Response window: 4 hours to containment decision.
Who responds: Team lead plus IT security contact. Management notification (no escalation to CIO required unless it becomes Tier 2 or higher).
Actions: Contain the issue (disable the affected AI feature if it's still producing incorrect outputs). Assess breadth: was this customer affected, or potentially others? Document. Determine whether proactive customer communication is warranted (usually not for Tier 3, unless the incorrect output could cause the customer harm if they later act on it).
Tier 2: Incident response
Criteria: Customer-facing Execute error, data exposure incident that's been contained, hallucination that was acted on by customers.
Response window: 1 hour to initial response, ongoing management until resolved.
Who responds: CIO and security lead notified within the hour. Legal counsel on standby. Communications team engaged for customer notification drafting.
Actions: Assess impact (how many customers, what data, what actions taken). Contain (disable affected workflow, reverse Execute actions where possible). Customer communication plan: do affected customers need to be notified? What do they need to know? Regulatory notification assessment: does this constitute a GDPR Article 33 notifiable breach? Document everything in real time.
Tier 1: Crisis
Criteria: Regulatory exposure is confirmed or likely, large-scale customer impact, bias incident with affected individuals, data exposure involving sensitive personal data at scale.
Response window: Immediate. The chief executive officer (CEO) and General Counsel must be in the loop within the first hour.
Who responds: Executive leadership, legal counsel, external communications, regulatory affairs if applicable.
Actions: Executive decision on whether to suspend the AI system entirely pending investigation. External legal counsel engaged. Customer and regulator communication drafted and reviewed. Post-crisis review scheduled. If EU personal data is involved and the breach is notifiable, the 72-hour clock under GDPR Article 33 is running.
GDPR Article 33 and notification requirements
GDPR Article 33 requires notification to the relevant supervisory authority within 72 hours of becoming aware of a personal data breach, unless the breach "is unlikely to result in a risk to the rights and freedoms of natural persons."
An AI incident may constitute a personal data breach if:
- An AI system processed personal data in a way that resulted in unauthorized disclosure
- An AI output containing personal data was sent to an unauthorized recipient
- An AI system made an automated decision using personal data in a way that wasn't disclosed to data subjects
- Prompt injection or other exploitation led to data exfiltration
The 72-hour clock starts when you become aware of the breach, not when the investigation is complete. You can submit an initial notification that says "we're aware of an incident, investigation is ongoing" and supplement it later. Waiting until the investigation is complete before notifying is not compliant.
For US-based organizations operating in regulated industries, analogous requirements exist: the HIPAA Breach Notification Rule for PHI breaches, SEC cybersecurity disclosure rules for material cybersecurity incidents, and state-level breach notification laws.
Post-incident review: AI root cause analysis
The post-incident review for an AI incident follows a different structure than the standard IT post-mortem.
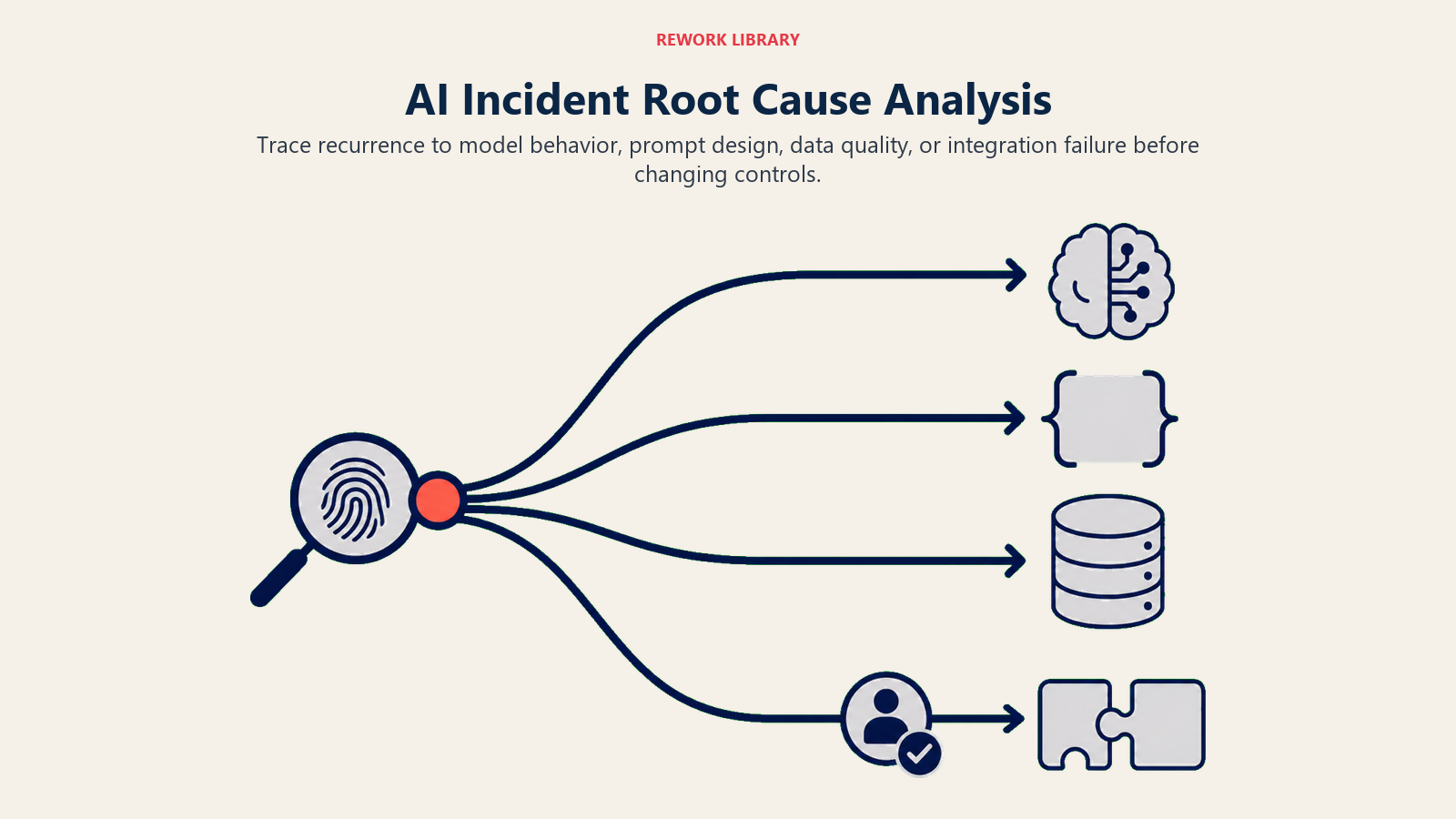
IT post-mortems ask: what technical failure caused the outage? Fix the technical failure, restore the service.
AI post-incident reviews ask four questions:
Was this a model failure? Did the AI produce an incorrect output because the underlying model was wrong, hallucinating, or performing poorly on this input type? If yes: what prompt changes, retrieval improvements, or model updates would prevent recurrence? Should this model continue to be used for this use case?
Was this a prompt or design failure? Did the AI produce an incorrect output because the prompt was ambiguous, the context window was insufficient, or the workflow wasn't designed to handle this input? If yes: this is often the most fixable root cause. Redesign the prompt template, add input validation, or add guardrails.
Was this a data failure? Did the AI produce an incorrect output because the retrieval data was outdated, the training data was biased, or the input data was malformed? If yes: data governance is the fix, not the model.
Was this an integration failure? Did the AI produce the right output but the integration between the AI system and the downstream Execute system failed? If yes: the AI governance root cause is less important than the integration engineering fix. But also: was there a human review step that should have caught this before Execute?
Document the root cause in the AI risk register. Update the relevant AI governance documents. If the incident revealed a gap in your human-in-the-loop design, fix the gap.
Building the reporting culture
Incident response depends on employees being willing and able to raise problems early, not just on the quality of the written playbook.
The most dangerous gap in any AI incident response program isn't the playbook. It's the employees who see a problem and don't report it.
An employee who noticed that the AI chatbot was giving wrong refund information last Tuesday. An engineer who saw an anomalous pattern in the AI output logs but wasn't sure it mattered. A customer success manager who heard a complaint about an AI-generated recommendation but chalked it up to a one-off.
Every one of these is an early signal. Most AI incidents that become crises started as signals that were seen and not acted on.
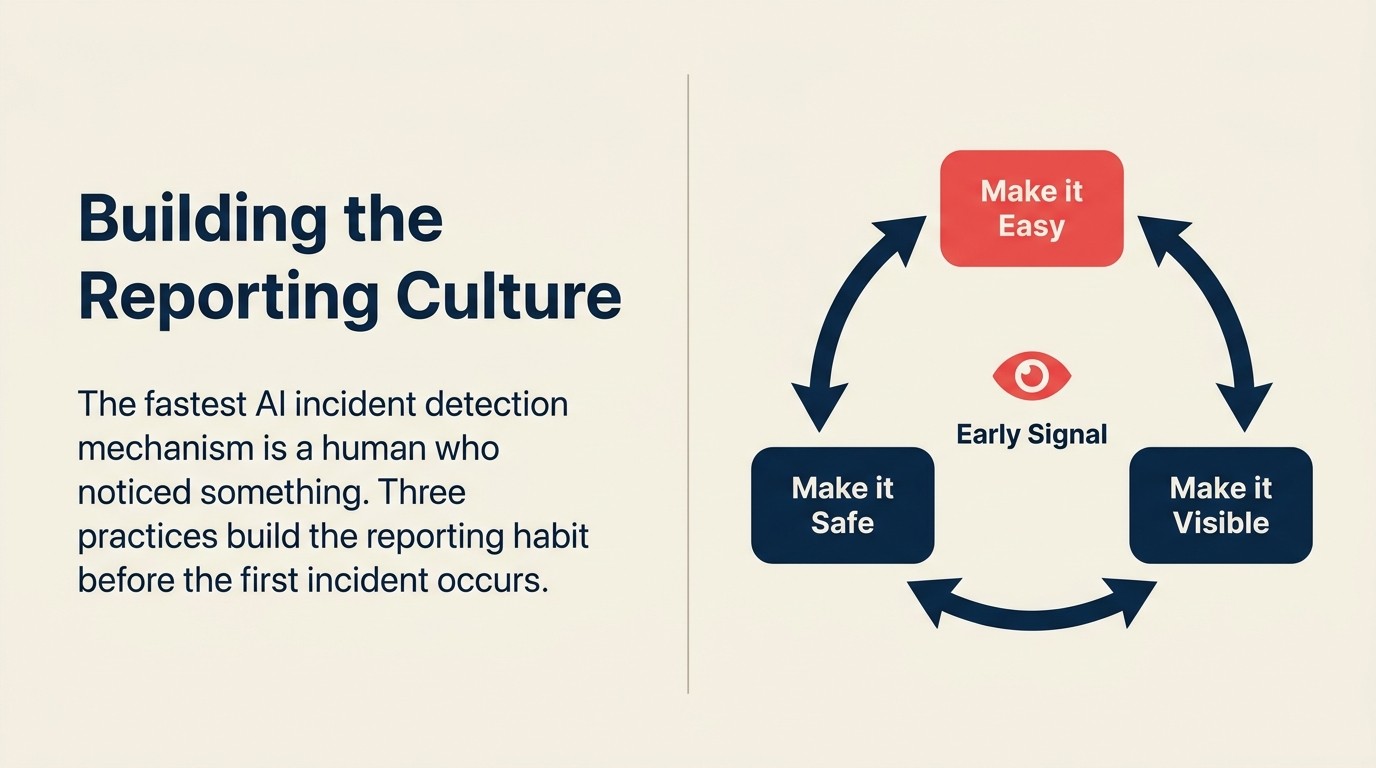
Building a reporting culture means three things:
Make reporting easy. One internal channel, one form, one email address. Employees shouldn't have to work through org charts to report a potential AI problem.
Make reporting safe. Employees who report problems must not be blamed for the incident or for raising a false alarm. The response to a report, even if it turns out to be a non-incident, should be "thank you for flagging this." If reporters feel blamed, they'll stop reporting.
Make reporting visible. When a report leads to a genuine incident being caught early, tell the team. Not "we had a major incident" but "because someone flagged an anomaly last week, we caught a problem before it affected customers." Social proof that reporting matters builds the habit.
The governance documents, the audit trails, and the response tiers all exist to manage incidents after they occur. The reporting culture is what determines whether you find out about problems early or late.
What this playbook doesn't replace
This playbook governs AI-specific incident response. It doesn't replace your existing IT incident response process, your data breach response process under GDPR or CCPA (California Consumer Privacy Act), or your HR incident process for discrimination-related complaints. Those processes still apply. For incidents that involve both an AI failure and a data breach, both playbooks run in parallel.
Connect this playbook to your audit trail framework, which provides the evidence you'll need during incident investigation. Connect it to your AI use policy, which defines the authorized scope of AI actions. And connect it to your AI risk register, which is where known risk patterns from past incidents get documented so future incidents are detected faster.
Rework Analysis: Based on enterprise AI incident patterns, the most common reason minor AI incidents escalate to crises is not the incident itself but the detection delay. A bias incident affecting 15% of a scoring model's outputs may run for 8-12 weeks before appearing in business metrics. A data exposure in a shared AI context may not surface until a customer reports seeing another user's data. The reporting culture section of this playbook exists because the fastest detection mechanism is a human who noticed something and reported it. Every week of detection delay compounds the regulatory exposure, the number of affected customers, and the remediation complexity.
The goal isn't to have a playbook you never need to use. It's to be ready when you do.
And the companies that run the cleanest incident responses are the ones who built the reporting culture long before the first incident. So the real question is: does your team know where to go when they see something wrong?
Frequently Asked Questions
What are the 4 types of AI incidents?
The 4-Type AI Incident Taxonomy classifies AI failures by root cause. Type 1 (Hallucination): AI generated factually incorrect content that was acted on. Type 2 (Execute Error): AI took a consequential real-world action incorrectly. Type 3 (Bias): AI made systematically discriminatory decisions affecting a subpopulation. Type 4 (Data Exposure): prompt input or AI output revealed protected information to unauthorized parties. A fifth type, Model Drift, describes gradual performance degradation over time without a single failure moment. Each type requires a different detection approach, response timeline, and root cause investigation.
How is an AI incident different from a standard IT incident?
IT incidents are binary: systems are either up or down. AI incidents are probabilistic and latent. A biased model can make incorrect decisions for a specific subpopulation for weeks while overall accuracy metrics look acceptable. A hallucinating knowledge base may produce wrong answers for a specific query type without crashing. AI incidents don't generate 500 errors. They generate customer complaints, regulator inquiries, or business metric degradation. Standard IT monitoring misses the majority of AI incident types until they become crises.
What is the GDPR Article 33 requirement for AI incidents?
GDPR Article 33 requires notification to the relevant supervisory authority within 72 hours of becoming aware of a personal data breach. An AI incident constitutes a potential breach if it results in unauthorized disclosure of personal data, an AI output containing personal data was sent to an unauthorized recipient, or prompt injection led to data exfiltration. The 72-hour clock starts when the organization becomes aware of the incident, not when the investigation is complete. Initial notification can be submitted while the investigation continues.
What is the 4-tier AI incident response framework?
Tier 4 (Investigate): internal error with no external exposure, 24-hour assessment window, team-level response. Tier 3 (Contain): customer-facing incorrect output not acted on by the customer, 4-hour containment decision, team lead plus IT security. Tier 2 (Incident Response): customer-facing Execute error, contained data exposure, or acted-on hallucination, 1-hour initial response, CIO and legal notified. Tier 1 (Crisis): confirmed regulatory exposure, large-scale customer impact, bias incident with affected individuals, or sensitive data exposure at scale, immediate executive involvement with General Counsel in the first hour.
How do you build a reporting culture for AI incidents?
Three practices build a reporting culture. Make reporting easy: one internal channel, one form or email address, 30-second reporting process. Make reporting safe: explicitly state in the policy that good-faith reporting is protected and that reporters will not be blamed for incidents or false alarms. Make reporting visible: when a report catches a problem early, tell the team that the early flag prevented a larger incident. Social proof that reporting matters builds the habit faster than any training program.
See also:
- AI Approval Gates and Vendor Review: the pre-deployment gate that reduces how often you'll need this playbook
- Data Classification for AI Access Rules: the data tier framework that determines if a Type 4 incident requires breach notification
- Stage 3 to 4: From Scaled to Integrated: why formal incident response becomes non-optional at Stage 4
- The 18-Month CEO AI Agenda: where incident response infrastructure fits in Phase 1 of the transformation roadmap

Co-Founder, Rework.com
On this page
- How AI incidents differ from IT incidents
- The 4-Type AI Incident Taxonomy
- AI incident taxonomy
- Type 1: Hallucination incident
- Type 2: Execute error
- Type 3: Bias incident
- Type 4: Data exposure incident
- Type 5: Model drift
- The 4-tier response framework
- Tier 4: Investigate
- Tier 3: Contain
- Tier 2: Incident response
- Tier 1: Crisis
- GDPR Article 33 and notification requirements
- Post-incident review: AI root cause analysis
- Building the reporting culture
- What this playbook doesn't replace