リードデータ管理:レベニューインテリジェンス基盤の構築

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
データ品質の低さは収益への隠れた税金だ。調査によると、無駄な営業時間、逃した機会、誤った情報に基づく悪い意思決定を通じて、B2B企業に収益ポテンシャルの20-30%のコストをかけている。しかし、ほとんどの企業はデータ管理を後回しにする。すでに壊滅的に壊れているときにのみ注目を得るもの。
現実はこうだ:レベニューエンジンのすべてのシステムはリードデータで動いている。スコアリングモデル、ナーチャープログラム、ルーティングロジック、分析。これらすべてが正確で完全で一貫性のあるデータを持つことに依存している。悪いデータが入れば悪い結果が出る、どれだけプロセスが洗練されていても。
このガイドでは、一度きりのクリーンアッププロジェクトではなく、体系的な能力としてデータ品質を構築し維持する方法を示す。データを負債から戦略的資産に変えるフレームワーク、プロセス、ガバナンス構造を学ぶ。
重要な事実:リードデータ品質の影響
- 不良データはアメリカ企業に年間3兆1000億ドルの損失をもたらしています。
- B2Bデータは毎月**2.1%**の割合で劣化します(年間約25%)。
- 営業担当者はデータ品質の問題により、販売時間の**27%**を無駄にしています。
- ビジネスプロフェッショナルの**25〜30%**が毎年転職し、連絡先データが陳腐化します。
- 一般的なCRMデータベースには**10〜30%**の重複レコードが存在します。
データ品質の5つの次元

データ品質は単純なイエス/ノーの質問ではない。多次元だ。5つの重要な次元で評価し管理する必要がある:
正確性:正しく真実の情報
正確性はデータが現実を反映していることを意味する。メールアドレスは実際にその人のメール。会社名は正しくスペルされている。電話番号は正しい人につながる。
不正確なデータは以下のように現れる:
- アドレスが間違っているためメールがバウンス
- 間違った人や切断された番号への電話
- コンタクトの間違ったタイトルや会社
- かつては正しかったが今は違う古い情報
主な原因:手動入力エラー、古いソース、フォームスパム、悪いデータを含む購入リスト。
測定方法:バウンス率、間違い番号率、コンタクト試行失敗率を追跡。
目標ベンチマーク:ハードバウンス率2%未満、電話番号失敗率5%未満。
完全性:必須フィールドすべてが入力
完全なデータはアクションを取るために必要なすべての情報を持っていることを意味する。名前とメールだけではなく、役職、会社、会社規模、業界、およびプロセスが依存するその他のフィールドを持つこと。
不完全なデータは摩擦を生む:
- 企業データなしにリードを適切にスコアリングできない
- 地理や会社規模を知らずにリードをルーティングできない
- 役職や業界なしにアウトリーチをパーソナライズできない
- ステージやエンゲージメントデータなしにナーチャーをセグメント化できない
主な原因:最小限のフォームフィールド、プログレッシブプロファイリングなし、担当者がデータ入力をスキップ、リードが部分的な情報を自己入力。
測定方法:フィールド別およびリードソース別のフィールド完了率。
目標ベンチマーク:重要フィールド(名前、メール、会社)で90%以上完了、二次フィールド(タイトル、会社規模、電話)で70%以上。
一貫性:システム間で標準化
一貫したデータは同じ情報がどこでも同じ方法でフォーマットされていることを意味する。「VP of Sales」と「Vice President, Sales」と「Sales VP」はすべて1つのフォーマットに標準化されるべき。「IBM」と「IBM Corporation」と「International Business Machines」は1つのレコードであるべき。
不一貫なデータは以下を壊す:
- レポートとセグメンテーション(タイトルが標準化されていないとタイトルでグループ化できない)
- 重複排除(会社名が異なると重複を識別できない)
- アカウントベース戦略(会社データが一貫していないとコンタクトをアカウントにロールアップできない)
主な原因:自由形式テキストフィールド、異なる規則を持つ複数のデータソース、バリデーションルールの欠如、標準化プロセスなし。
測定方法:キーフィールドのバリエーションを分析(「役職」や「会社名」のユニーク値)、重複レコード率。
目標ベンチマーク:重複レコード5%未満、すべての重要な分類フィールドに標準化されたピックリスト。
タイムリー性:現在の最新状態
タイムリーなデータは昨年の状態ではなく、現在の状態を反映する。コンタクトはまだ会社にいる。タイトルはまだ正確。エンゲージメントアクティビティは最近。会社はまだ事業中。
古いデータは以下を引き起こす:
- 会社を去った人へのアウトリーチ(恥ずかしく無駄)
- 古い企業データに基づく間違ったルーティング
- 古いエンゲージメントに基づく不正確なスコアリング
- 古いステージ/ステータスデータに基づく悪い予測
主な原因:リフレッシュプロセスなし、エンゲージメントモニタリングの欠如、静的なデータインポート、減衰メカニズムなし。
測定方法:フィールド別の最終更新からの経過時間、過去30/90/180日以内に更新されたレコードの割合。
目標ベンチマーク:コンタクトデータは6ヶ月ごとにリフレッシュ、エンゲージメントデータはリアルタイム、企業データは四半期ごとにリフレッシュ。
一意性:重複なし、クリーンなレコード
一意のデータはリードごとに1レコード、重複なしを意味する。重複レコードは履歴を断片化し、所有権を混乱させ、コミュニケーション災害を作り(同じ人が3人の担当者から3通のメールを受け取る)、レポートを無価値にする。
重複問題:
- 複数の担当者が同じリードにコンタクト
- 断片化されたエンゲージメント履歴
- 不正確なレポート(重複でカウントが膨らむ)
- 破損したデータでのマージ試行失敗
主な原因:複数のフォーム送信、重複排除なしのリストインポート、同じ人の異なるメールアドレス、リアルタイム重複チェックの欠如。
測定方法:重複レコード割合、マージ頻度、重複関連のサポートチケット。
目標ベンチマーク:重複率2%未満、エントリーポイントでの自動重複排除。
データキャプチャベストプラクティス
データ品質を確保する最良のタイミングはキャプチャポイント。最初からクリーンなデータは後でダーティなデータをクリーニングするより勝る。
必須 vs 任意フィールド戦略
必須にするすべてのフィールドがコンバージョン率を下げる。しかし、スキップするすべてのフィールドがデータ品質を下げる。バランスが必要。
常に必須:
- ファーストネームとラストネーム(「フルネーム」ではなく別々に)
- メールアドレス(バリデーション付き)
- 会社名
条件付き必須(プロセスニーズによる):
- 役職(B2Bでは重要、B2Cではあまり)
- 電話番号(リードに電話する場合のみ、メールのみなら不要)
- 会社規模(適格化要素の場合)
任意にする(提供されたら収集、強制しない):
- 二次連絡先情報
- エンリッチできる詳細な会社データ
- 好みのデータ
- キャンペーンアトリビューションフィールド
ルール:すぐに使用し、別の方法で簡単に取得できないものだけを必須にする。
プログレッシブプロファイリング方法論
最初のフォームで15フィールドを求めない。3つ求め、次のインタラクションでさらに3つ、その後さらに3つ。
プログレッシブプロファイリング戦略:
- 最初のインタラクション(ゲートコンテンツ、ニュースレター登録):名前、メール、会社
- 2回目のインタラクション(別のダウンロード、ウェビナー登録):役職、会社規模
- 3回目のインタラクション(デモリクエスト、トライアル):電話番号、特定のニーズ
- 営業インタラクション(適格化コール):その他すべて
マーケティングオートメーションプラットフォームは、すでに入力されたフィールドを非表示にし、ネット新規フィールドのみを表示すべき。これは最初から圧倒することなく、時間をかけて完全なデータをキャプチャする。
リアルタイムフィールドバリデーション
悪いデータをエントリーでキャッチし、データベースに入った後ではない。
メールバリデーション:フォーマットをチェック、ドメインが存在することを確認、使い捨てメールプロバイダー(guerrillamailなど)をフラグ、B2Bなら個人メールをフラグ。
電話バリデーション:正しいフォーマット、国コード要件、最小長をチェック。
会社バリデーション:会社データベースからオートコンプリートを提供、ナンセンスエントリー(「test」「company」「N/A」)をフラグ。
名前バリデーション:明らかな偽物(「Mickey Mouse」「Test Test」)をフラグ、ファーストネームとラストネームの両方を必須。
多くのフォームツールとCRMは組み込みバリデーションを提供する。それを使う。
キャプチャポイントでのエンリッチメント
リードがフォームを送信したらすぐに、追加データでレコードをエンリッチ。これはギャップを埋め、完全性を即座に改善する。
エンリッチメントソース:
- 会社データプロバイダー(Clearbit、ZoomInfo、DiscoverOrg)
- メール検証サービス(NeverBounce、BriteVerify)
- ソーシャルプロファイルエンリッチメント(LinkedInデータ)
- IPジオロケーション(会社と所在地データ用)
詳細なアプローチについてはリードデータエンリッチメントを参照。
リアルタイムでエンリッチしてルーティング、スコアリング、初期コンタクトがすべて完全なデータから恩恵を受けるようにする。
完了のためのフォーム最適化
悪いフォームUXは悪いデータを作る。人々は急いで、太い指でエントリーするか、完全に放棄する。
UXベストプラクティス:
- モバイル最適化フォーム(トラフィックの60%以上がモバイル)
- 標準フィールドでオートコンプリート有効
- 明確なフィールドラベルと例
- インラインバリデーション(送信前にエラーを表示)
- マルチステップフォームの進行インジケーター
- 最小限のフィールド(追加のフィールドごとにコンバージョンが約5-10%低下)
実際のモバイルデバイスでフォームをテスト。完了が苦痛なら、データ品質が苦しむ。

データエンリッチメント戦略
良いキャプチャでも、ギャップがある。エンリッチメントがそれを埋める。
自動化されたエンリッチメントツール
現代のエンリッチメントツールはリードレコードにデータを自動的に追加する。メールアドレスまたは会社名でマッチし、以下を追加:
- 役職と職位レベル
- 会社規模、収益、業界
- 会社テクノロジースタック
- ソーシャルプロファイル
- 直通電話番号
- 会社の資金調達と成長データ
人気のエンリッチメントベンダー:
- Clearbit:リアルタイムエンリッチメントAPI、ウェブフォームに良い
- ZoomInfo:深いB2Bコンタクトと会社データ
- Lusha:連絡先情報エンリッチメント
- HG Insights:テクノロジーインストールデータ
- BuiltWith:ウェブサイトテクノロジー検出
ほとんどは主要なCRMとマーケティングオートメーションプラットフォームと直接統合。
サードパーティデータプロバイダー
自動化されたエンリッチメントを超えて、リスト構築とバルクエンリッチメントのためにデータプロバイダーと作業できる:
- 購入リスト(品質とコンプライアンスに注意)
- インテントデータプロバイダー(Bombora、6sense、TechTarget)
- 企業データ(Dun & Bradstreet、InsideView)
- テクノグラフィックデータ(BuiltWith、Datanyze)
プロバイダーを慎重に評価する。安いデータは通常悪いデータ。
エンリッチメントタイミング:即時 vs バッチ
いつエンリッチするかの2つのアプローチ:
即時/リアルタイムエンリッチメント:
- フォーム送信またはリード作成時に発生
- 即時のルーティングとスコアリングを可能にする
- より高価(エンリッチメントごとに支払い)
- 高価値リードまたは重要なワークフローに最適
バッチエンリッチメント:
- 定期的なジョブを実行してリードをバルクでエンリッチ
- より安い(ボリューム価格)
- キャプチャとエンリッチメント間のラグタイム
- 大きなデータベースまたは優先度の低いリードに最適
ハイブリッドアプローチ:重要なフィールドは即座にエンリッチ、あればいいフィールドはバッチでエンリッチ。
コスト便益分析
エンリッチメントは無料ではない。価値があるか評価する。
計算:
- エンリッチされたレコードあたりのコスト
- 改善されたコンバージョン率の価値(より良いルーティング、スコアリング、パーソナライゼーション)
- 担当者が節約した時間(リードを手動でリサーチしない)
計算例:
- エンリッチメントコストがリードあたり50円
- 10,000リード = 50万円
- コンバージョンが2%改善 = 200の追加商談
- 200商談 × 20%勝率 × 250万円ACV = 1億円の追加収益
- ROI:1億円の利益 / 50万円のコスト = 200倍のリターン
小さなコンバージョン改善でもエンリッチメントコストを正当化する。
継続的なデータメンテナンスプロセス
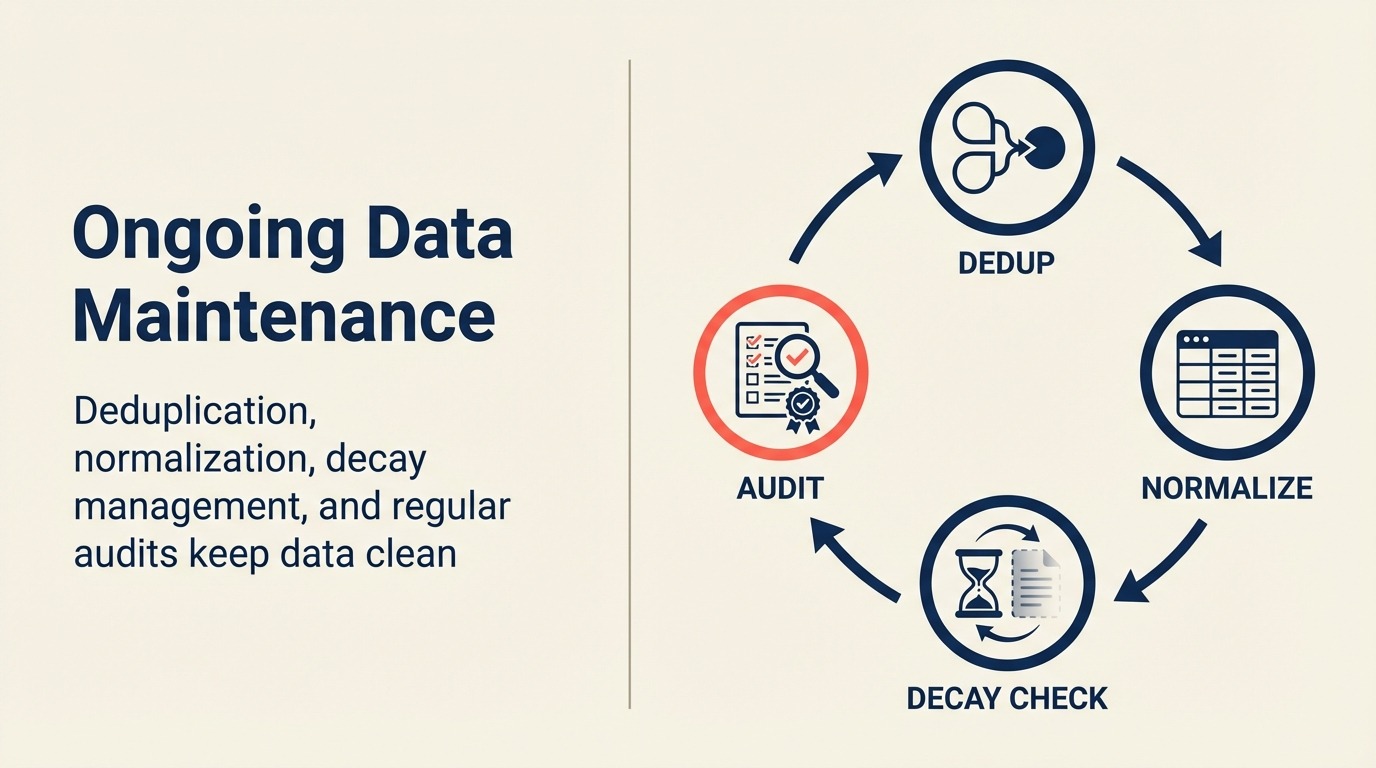
データは劣化する。人々は転職し、会社は買収され、メールは無効になる。データを新鮮に保つシステムが必要。
定期的なデータ品質監査
四半期ごとに監査を実行し、5つの次元すべてで品質を測定:
- 200-500レコードのサンプルを取得
- 正確性を手動で検証(番号に電話、LinkedInプロファイルをチェック)
- 完全性をチェック(何%が必須フィールドすべてを持っているか)
- 一貫性を評価(何件の重複/非標準化エントリがあるか)
- タイムリー性をテスト(何%のデータが古いか)
発見を文書化し、時間経過で傾向を追跡。良くなっているか悪くなっているか?
劣化防止メカニズム
劣化を防ぐまたはフラグするシステムを構築:
メールバリデーション:データベースで定期的にバリデーションを実行し、発生前にデリバラビリティの問題を特定。ハードバウンスは即座に削除。
エンゲージメントモニタリング:エンゲージメントの欠如は悪いデータを示す可能性がある。誰かが12ヶ月間メールを開いていないなら、まだ会社にいるか確認。
転職検出:LinkedIn Sales Navigatorなどのツールはコンタクトが転職したときにアラート。それに応じてレコードを更新または廃止。
会社ステータスモニタリング:会社が廃業、買収、またはデータに影響する大きな変化を経験したかを追跡。
更新とリフレッシュワークフロー
異なるデータタイプをリフレッシュするスケジュールを設定:
コンタクトデータ:6ヶ月ごとにリフレッシュ(人々は頻繁に転職) 会社企業データ:四半期ごとにリフレッシュ(規模とステータスの変化) テクノロジーデータ:毎月リフレッシュ(企業は定期的にツールを追加/削除) エンゲージメントデータ:リアルタイム更新(遅延させない)
エンリッチメントプロバイダーまたはデータサービスを通じてこれらのリフレッシュを自動化。
自動化された重複排除ルーティン
手動の重複排除に頼らない。自動化されたプロセスを構築:
エントリーポイントで:新しいレコードを作成する前に重複をチェック。マージルール:
- 完全一致メール = 新規作成の代わりに既存レコードを更新
- 類似の名前 + 会社 = 手動レビューのためにフラグ
- 同じドメイン + 類似の名前 = 潜在的な重複アラート
定期的なクリーンアップ:すり抜けた重複をキャッチするために週次または月次の重複排除ジョブを実行。
マージルール:マージ時にどのレコードが勝つか定義:
- 最近更新されたデータを保持
- 最も完全なレコードを保持
- すべてのアクティビティ履歴を保存
- エンゲージメントスコアを結合
ほとんどのCRMには組み込みの重複排除ツールがある。それらを使用し、ニーズに合わせてルールをカスタマイズ。
データクレンジングキャンペーン
定期的にプロアクティブなクリーンアップを実行:
標準化キャンペーン:フィールドを標準化されたフォーマットにバルク更新(役職、会社名、業界)。
完全性キャンペーン:重要なフィールドが欠けているレコードを識別し、バルクでエンリッチ。
バリデーションキャンペーン:データベース全体をバリデーションツールに通し、問題をフラグ/修正。
パージキャンペーン:救いようのないレコードを削除またはアーカイブ(無効なメール、間違ったターゲットオーディエンス、2年以上ゼロエンゲージメント)。
これらを四半期または半期ごとにスケジュール。
データガバナンスフレームワーク
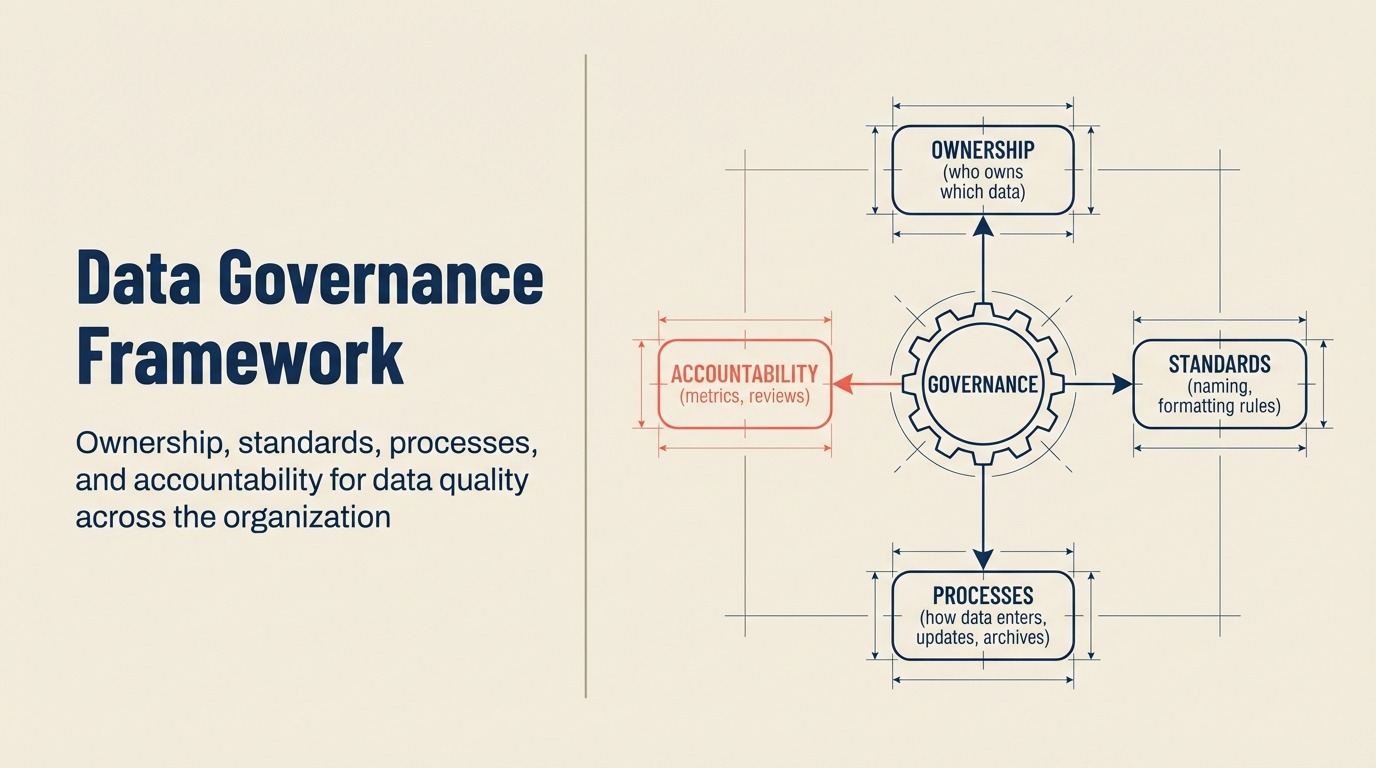
良いデータにはツールだけでなく、組織的な規律が必要。
所有権と説明責任モデル
誰かがデータ品質を所有する必要がある。役割を定義:
データオーナー(通常、レベニューオペレーションまたはセールスオペレーション):
- データ基準とポリシーを設定
- データ品質メトリクスを管理
- エンリッチメントとクレンジングプロセスを所有
- データ紛争を解決
データスチュワード(通常、フロントラインマネージャー):
- チーム内で基準を強制
- レコードのデータ品質をレビュー
- 何が機能している/していないかについてフィードバック提供
データユーザー(営業担当者、マーケター):
- データ入力基準に従う
- 発見されたデータ問題をフラグ
- 必須フィールドを完了
データ品質をマネージャーのKPIにする。データ品質がスコアカードにあれば、彼らはそれを気にする。
データ基準と定義
各フィールドの意味と入力方法を正確に文書化する。
基準例:
- 会社規模フィールド:グローバルの従業員数、ピックリストから選択
- スモール:1-50人
- ミッドマーケット:51-500人
- エンタープライズ:501人以上
- ソース:可能なら自己報告、そうでなければエンリッチメントデータから
- 更新頻度:年次または変更が判明したとき
すべての重要なフィールドについてこれらの定義を持つデータ辞書を作成する。CRMに触れるすべての人がアクセスできるようにする。
アクセス制御ポリシー
すべての人がすべてを編集すべきではない。アクセスレベルを定義:
閲覧のみ:データを見れる、編集できない(レポートユーザー) 自分のレコードを編集:所有するリード/コンタクトを編集できる(営業担当者) すべてのレコードを編集:任意のレコードを編集できる(営業マネージャー、オペレーション) 管理者アクセス:フィールド構造、自動化などを変更できる(オペレーション管理者)
バルク更新またはレコード削除ができる人を制限する。事故は起こり、マスデータ破壊は高価。
コンプライアンス要件:GDPR、CCPA、CAN-SPAM
データガバナンスは品質だけでなく、法的コンプライアンスでもある。
GDPR要件(ヨーロッパデータ):
- データ収集と処理のための合法的根拠
- リクエストに応じて個人にデータを提供する能力
- リクエストに応じてデータを削除する能力(「忘れられる権利」)
- ベンダーとのデータ処理契約
- 侵害通知手順
CCPA要件(カリフォルニアデータ):
- 何のデータを収集し、なぜかを開示
- データ販売のオプトアウトを許可
- リクエストに応じてデータを提供
- リクエストに応じてデータを削除
CAN-SPAM要件(メール):
- 明確な配信停止メカニズム
- 10日以内に配信停止を尊重
- 正確なFromアドレスと件名
- メールに物理的な郵送先住所
これらの要件をデータ管理プロセスに組み込む。非コンプライアンスは悪いプラクティスだけでなく、違法で高価。
データ保持ポリシー
どのくらいデータを保持すべきか?永遠ではない。
保持期間を定義:
- アクティブリード:エンゲージしているかICPに適合している限り保持
- 非アクティブリード:ゼロエンゲージメントで24ヶ月後にアーカイブ
- 不適格リード:リサイクル可能でなければ12-18ヶ月後にアーカイブ
- 顧客:無期限に保持(または契約要件ごと)
- 配信停止/オプトアウト:抑制のためにメール/識別子を保持、他のデータは削除
これらのポリシーに基づいて自動アーカイブ/削除ワークフローを構築。
システム統合と同期
リードデータは複数のシステムに存在する。同期を維持する必要がある。
マーケティングオートメーション双方向同期
マーケティングオートメーションプラットフォーム(Marketo、HubSpot、Pardotなど)とCRMは双方向で同期すべき:
CRM → マーケティングオートメーション:
- リード作成/更新
- ステータスとステージ変更
- 営業アクティビティとノート
- 商談データ
マーケティングオートメーション → CRM:
- フォーム送信と新規リード
- メールエンゲージメントアクティビティ
- ウェブサイト行動とスコアリング
- キャンペーンメンバーシップ
同期頻度:重要なデータ(新規リード、ステータス変更)はリアルタイム、アクティビティデータは時間別または日次バッチ。
CRM統合パターン
複数のCRMまたは営業ツールを使用する場合、リードデータの「マスター」システムとして1つに標準化。他のすべてのシステムはそれに同期し、お互いに同期しない(統合のスパイダーウェブを避ける)。
一般的なパターン:
- Salesforce(またはHubSpot CRM)= マスターリードデータベース
- マーケティングオートメーションはSalesforceに同期
- 営業エンゲージメントツール(Outreach、SalesLoft)はSalesforceに同期
- BI/分析ツールはSalesforceから読み取り
これにより単一の真実のソースが作られる。
エンリッチメントツール接続
エンリッチメントツールをCRMに接続して、レコードを自動的に更新:
- リアルタイムエンリッチメント用のAPI統合
- 定期的なリフレッシュ用のスケジュールされたバッチジョブ
- イベントベースエンリッチメント用のWebhookトリガー
エンリッチされたデータを手動でエクスポート/インポートしない。ラグとエラーを作る。
マスターデータ管理アプローチ
複数のビジネスユニットまたはシステムを持つ複雑な組織には、正式なマスターデータ管理(MDM)を検討:
MDMがすること:
- 各エンティティ(リード、コンタクト、アカウント)に1つのゴールデンレコードを定義
- どのシステムがどのフィールドに権限を持つか管理
- システム間でデータが異なるときの競合を解決
- どこでも一貫性を確保
MDMが必要なとき:
- 複数のCRMまたはデータベース
- M&Aでデータサイロが作られた
- 複雑なアカウント階層
- データ一貫性のための規制要件
MDMは複雑で高価。本当に必要な場合にのみ投資。
データ品質メトリクスとモニタリング
測定しないものは改善できない。毎月これらのメトリクスを追跡。
品質スコアダッシュボード
次元全体で複合データ品質スコアを作成:
- 正確性:メールデリバラビリティ率、電話番号正確性
- 完全性:すべての重要フィールドが入力されているレコードの割合
- 一貫性:重複率、標準化率
- タイムリー性:過去90日以内に更新されたレコードの割合
- 一意性:一意である(重複でない)レコードの割合
これらを単一の0-100品質スコアにロールアップ。時間経過とリードソース別の傾向を追跡。
フィールド完了率
各フィールドが入力されているレコードの割合を追跡:
- メール:100%であるべき(必須)
- 会社:95%以上であるべき
- タイトル:目標85%以上
- 電話:目標70%以上(電話を使用する場合)
- 会社規模:目標80%以上
- 業界:目標75%以上
ギャップを識別し、エンリッチメント努力を優先順位付け。
劣化率追跡
データがどれだけ速く劣化するかを測定:
- 年間何%のメールが無効になるか?(10-15%が典型的)
- 年間何%のコンタクトが転職するか?(20-25%が典型的)
- 年間何%の電話番号が無効になるか?(15-20%が典型的)
これらの劣化率を使用してリフレッシュサイクルを計画。
重複検出率
追跡:
- 月間作成される新しい重複
- 総重複割合
- 重複識別までの時間
- 重複マージまでの時間
重複が増加傾向なら、防止メカニズムが機能していない。
一般的なデータ管理課題
良いプロセスでも、これらの問題が発生する。
重複リード防止
重複は以下のときに発生:
- 同じ人がわずかに異なる情報で複数のフォームを送信
- リストインポートが既存レコードに対してチェックされない
- 異なるシステムが独立してリードを作成
- 営業担当者が既存を確認せずに手動でレコードを作成
解決策:
- エントリーポイントでの厳格なマッチングルール
- ファジーマッチングアルゴリズム(「Bob Smith」と「Robert Smith」をキャッチ)
- 潜在的な重複検出時のリード所有権アラート
- 定期的な自動重複排除ジョブ
不完全なレコードの処理
重要なデータが欠けているリードにどう対処するか?
オプション:
- エンリッチされるまでキューに保持(悪いデータで営業にルーティングしない)
- 営業にルーティングするが「不完全」としてフラグ(低優先度)
- プログレッシブプロファイリングのためにマーケティングに戻す
- エンリッチできず最低限を満たさなければ不適格化
ポリシーを文書化し、ルーティングロジックを自動化。
古いデータの識別
データの年齢だけでは古いとは限らない。昨日エンゲージしたが2年間タイトルを更新していないリードは問題ないかもしれない。
古さのインジケーター:
- メールハードバウンス
- 電話番号が切断
- 12ヶ月以上ゼロエンゲージメント
- コンタクトがもう会社にいない(LinkedInチェック)
- 会社が廃業
これらをレビューまたは自動アーカイブのためにフラグ。
システム間の不一致
システム間でデータが異なるとき、どれが正しい?
解決ルール:
- 最近更新されたものが勝つ(通常)
- 特定のフィールドについてシステムオブレコードが勝つ(ステータスはCRM、エンゲージメントはマーケティングオートメーション)
- 高価値の競合は手動レビュー必要
- 傾向分析のために競合を記録(なぜシステムが同期していない?)
データ品質を文化に組み込む
ツールとプロセスは重要だが、文化がもっと重要。
データ品質を可視化:チームミーティングでメトリクスを共有。改善を祝う。問題を指摘する(個人を責めずに)。
報酬に紐付ける:データ品質がノルマ達成やチーム目標に影響するなら、人々は気にする。しなければ、しない。
継続的に訓練:人々がデータ基準を知っていると仮定しない。なぜ重要か、どう正しく行うかについて定期的なトレーニング。
簡単にする:正しいことをするのが難しければ、人々はしない。フォームをシンプル化し、バリデーションを追加し、できることを自動化する。
ループを閉じる:悪いデータがどう案件を失わせたか、良いデータがどう勝つのを助けたか担当者に示す。パイプラインレビューを通じて影響を具体的にする。
データ管理の位置づけ
データ品質はリード管理のその他すべてを可能にする:
- リードスコアリングは完全で正確な企業データと行動データに依存
- マルチチャネルキャプチャはソース間での重複排除を必要とする
- ステータス管理は一貫した、タイムリーなステータスデータを必要とする
- リード管理とはは信頼性の高いリードデータを持つことから始まる
データ管理をインフラストラクチャと考える。機能しているとき、誰も気づかない。壊れているとき、すべてが壊れる。
品質の1つの次元から始める。おそらく完全性または正確性。それを体系的に改善する。次に次へ。すべてを一度に修正しようとしない。
目標は完璧ではない。より良い意思決定とより効率的なレベニューオペレーションを可能にする「十分に良い」データへの継続的な改善。それは達成可能であり、努力する価値がある。
さらに学ぶ
リード管理とデータドリブンレベニューオペレーションの知識を拡大:
- リードソース概要 - リードがどこから来るか、ソースデータが品質にどう影響するか理解する
- リードレスポンスタイム - クリーンなデータがより速いレスポンスとより高いコンバージョンをどう可能にするか学ぶ
- リードフォローアップベストプラクティス - 正確な連絡先情報が効果的なフォローアップをどう推進するか発見
- パイプライン衛生 - 営業パイプライン管理のためのデータ品質プラクティスを探索
- SaaS RevOpsフレームワーク - データ管理が現代のレベニューオペレーションにどう適合するか見る
- リードライフサイクルステージ - カスタマージャーニー全体でデータ要件がどう変わるか理解する
よくある質問
不良なリードデータは企業にどのくらいのコストをかけますか?
調査によると、データ品質の問題はアメリカ企業に年間3兆1000億ドルの損失をもたらしています。個々の企業レベルでは、不良データは収益ポテンシャルの20〜30%のコストをかけると推定されます。これには無駄な営業時間、誤ったターゲティングによる機会損失、誤情報に基づく意思決定のコストが含まれます。
リードデータはどれくらいの速さで劣化しますか?
B2Bデータは毎月約2.1%の割合で劣化します(年間約25%)。これはビジネスプロフェッショナルの25〜30%が毎年転職し、企業が住所変更・合併・事業停止を経験するためです。積極的なデータメンテナンスなしに、CRMデータベースは1〜2年で大幅に陳腐化します。
CRMデータベースの重複率の一般的な割合はどのくらいですか?
一般的なCRMデータベースには10〜30%の重複レコードが含まれています。これは単なる煩わしさではなく、実際の問題を引き起こします:同じリードへの複数回の連絡、不正確なレポーティング、誤ったリードスコアリング、誤ったアトリビューションです。定期的な重複排除は必須のメンテナンス作業です。
データ品質への投資はROIをどのように改善しますか?
データ品質への投資のROIは複数の観点で測定できます:営業担当者の時間節約(現在は27%がデータ問題に費やされている)、改善されたコンバージョン率(正確なデータでより良いターゲティング)、削減されたマーケティング費用の無駄(メール配信失敗、誤った見込み客へのアウトリーチ)。多くの企業は初期投資の3〜5倍のROIを報告しています。
どのリードをデータクリーニングで優先すべきですか?
アクティブなパイプライン内のリードから始めてください。次に最近エンゲージしたリード、そしてリターゲティングキャンペーンの対象になる予定のリードを優先します。古い低エンゲージメントのリードは後回しにするか、定期的な自動検証プロセスに任せてください。高価値のアカウントのデータは手動での確認を検討してください。
最初のフォーム入力で必須にすべきフィールドはどれですか?
最初のコンタクトには、姓名、会社名、メールアドレス、電話番号(B2Bの場合)の4フィールドが最低限必要です。役職、会社規模、業界などの追加情報はプログレッシブプロファイリングまたはデータエンリッチメントツールで後から取得できます。フィールドを増やすほどコンバージョン率が下がるため、最初のフォームは最小限にしてください。

Senior Operations & Growth Strategist
On this page
- データ品質の5つの次元
- 正確性:正しく真実の情報
- 完全性:必須フィールドすべてが入力
- 一貫性:システム間で標準化
- タイムリー性:現在の最新状態
- 一意性:重複なし、クリーンなレコード
- データキャプチャベストプラクティス
- 必須 vs 任意フィールド戦略
- プログレッシブプロファイリング方法論
- リアルタイムフィールドバリデーション
- キャプチャポイントでのエンリッチメント
- 完了のためのフォーム最適化
- データエンリッチメント戦略
- 自動化されたエンリッチメントツール
- サードパーティデータプロバイダー
- エンリッチメントタイミング:即時 vs バッチ
- コスト便益分析
- 継続的なデータメンテナンスプロセス
- 定期的なデータ品質監査
- 劣化防止メカニズム
- 更新とリフレッシュワークフロー
- 自動化された重複排除ルーティン
- データクレンジングキャンペーン
- データガバナンスフレームワーク
- 所有権と説明責任モデル
- データ基準と定義
- アクセス制御ポリシー
- コンプライアンス要件:GDPR、CCPA、CAN-SPAM
- データ保持ポリシー
- システム統合と同期
- マーケティングオートメーション双方向同期
- CRM統合パターン
- エンリッチメントツール接続
- マスターデータ管理アプローチ
- データ品質メトリクスとモニタリング
- 品質スコアダッシュボード
- フィールド完了率
- 劣化率追跡
- 重複検出率
- 一般的なデータ管理課題
- 重複リード防止
- 不完全なレコードの処理
- 古いデータの識別
- システム間の不一致
- データ品質を文化に組み込む
- データ管理の位置づけ
- さらに学ぶ
- よくある質問