Comprar vs. Construir para Funciones de IA en SaaS: El Marco de Decisión que Realmente Funciona
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La pregunta de construir vs. comprar existe en el software desde hace décadas. La versión de IA de esta pregunta parece similar en la superficie pero es estructuralmente diferente de maneras que cambian la respuesta.
La diferencia está en la tercera opción: wrap.
Las APIs de LLM (large language model) de OpenAI, Anthropic y Google han creado un camino que no existía antes de 2022. Se pueden construir funciones de IA sin entrenar modelos, sin ingenieros de ML y sin una inversión de infraestructura de datos de varios millones de dólares. Se llama a una API, se le pasa un prompt bien diseñado y contexto, y se obtiene un resultado inteligente. No es magia, pero es rápido, y para la mayoría de las superficies de producto SaaS, es el punto de partida correcto.
El marco clásico de comprar o construir pasa por alto esto porque fue diseñado para una era en que "construir IA" significaba "contratar científicos de datos y entrenar modelos con sus datos." Eso sigue siendo una opción. Simplemente ya no es la única. Para la mayoría de las empresas SaaS por debajo de Series C, es la incorrecta.
Así que la decisión real es de tres vías: Buy, Wrap o Build.
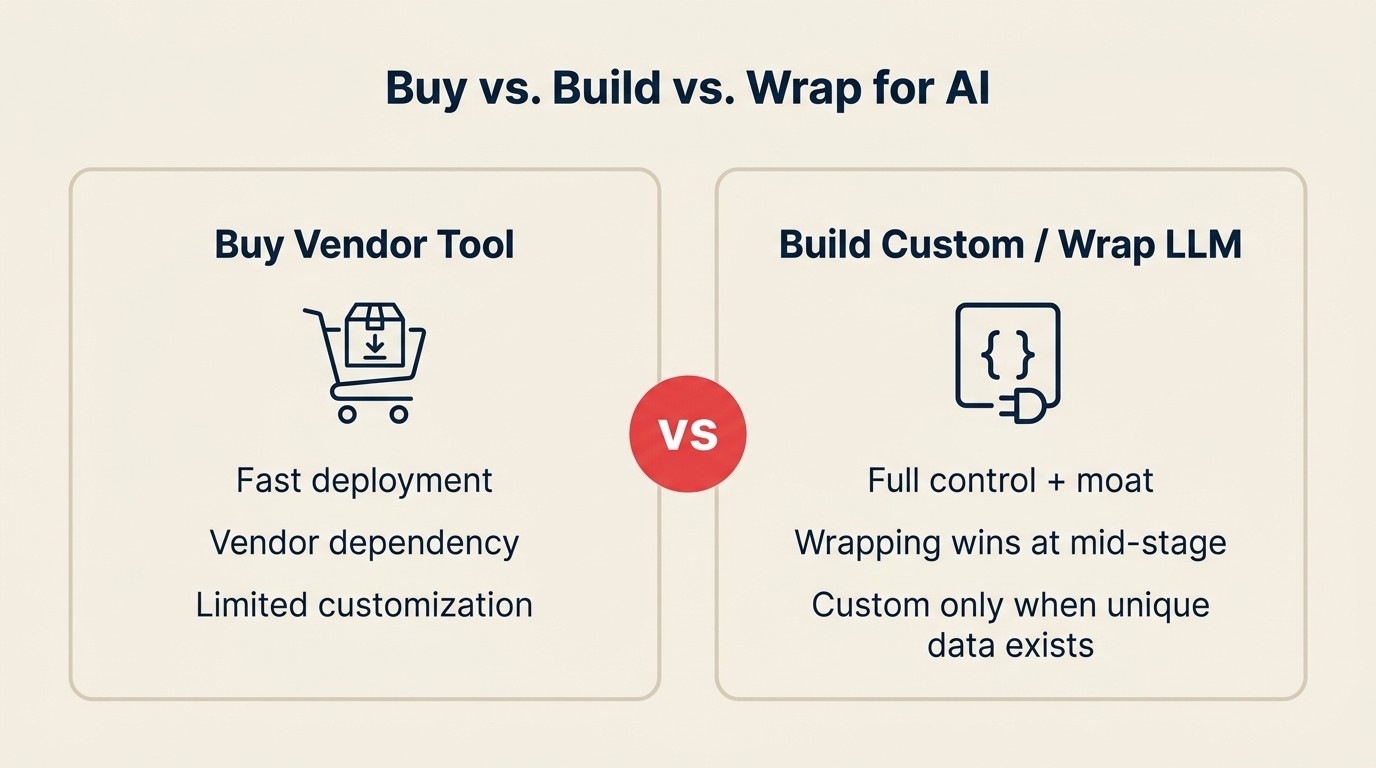
The Buy/Wrap/Build Decision
The Buy/Wrap/Build Decision es un marco de tres vías específico para las funciones de IA en SaaS. Buy compra un producto de proveedor de IA dedicado y lo integra en el flujo de trabajo: despliegue rápido, diferenciación limitada, dependencia del proveedor. Wrap usa APIs de LLM directamente para construir funciones de IA dentro de la superficie del propio producto: velocidad media, costo moderado, diferenciación significativa porque se controla la experiencia y el contexto. Build entrena o hace fine-tune a modelos personalizados: máximo techo de diferenciación, máximo costo, máximo tiempo, requiere talento de ML. La mayoría de las empresas SaaS omite Wrap y evalúa solo Buy o Build. Para la mayoría de las funciones de IA en producto por debajo de $50M de ARR, Wrap es el punto de partida correcto.
Definiendo las tres opciones
Buy: Comprar un producto de proveedor de IA dedicado e integrarlo en el flujo de trabajo. Gong para análisis de llamadas de ventas, Gainsight o Vitally para puntuación de salud de CS, Intercom Fin para deflección de soporte. Rápido de desplegar. Probado en producción. Capacidad limitada para diferenciarse.
Wrap: Usar las APIs de LLM de OpenAI, Anthropic o Google directamente para construir funciones de IA dentro del propio producto u operaciones. El código es propio, la UI es propia, el modelo es de ellos. Velocidad de construcción media, costo moderado a escala moderada, potencial de diferenciación significativo porque se controla la experiencia.
Build: Entrenar o hacer fine-tune a modelos propios. Pipeline de ML personalizado. Datos de entrenamiento propietarios. Máximo techo de diferenciación, máximo costo, máximo tiempo, requiere talento de ML. Reservado para los casos en que la IA es genuinamente el diferenciador central del producto y los datos crean un moat.
La mayoría de los equipos SaaS, cuando dicen "¿deberíamos construir IA?", están implícitamente preguntando sobre Build. La mayoría de las veces, la respuesta correcta es empezar con Wrap y ver si Build está realmente justificado por los datos y el panorama competitivo.
Key Facts: Economía de Buy vs. Build en IA SaaS
- Construir un agente de IA de complejidad media desde cero tarda un mínimo de 3-5 meses; un enfoque buy o wrap puede llevar al mercado en semanas (Ptolemay LLM TCO Research, 2025)
- 3 de cada 4 empresas que intentan construir arquitecturas de IA agéntica completamente en casa fracasan, porque estas arquitecturas requieren stacks RAG sofisticados, pipelines de datos avanzados y experiencia especializada en ML que la mayoría de los equipos SaaS no tienen antes de la Etapa 3 (Forrester, 2025)
- El gasto mensual promedio en IA saltó de $63,000 en 2024 a $85,500 en 2025, un aumento del 36%, con la proporción de empresas que planean gastar más de $100,000 por mes en IA más que duplicándose en el mismo período (Binadox, 2025)
Cuándo comprar (Buy)
Comprar es la respuesta correcta cuando el caso de uso es bien comprendido, bien servido por los proveedores existentes, y el tiempo hasta obtener valor importa más que la diferenciación.
El análisis de llamadas de ventas es un caso de uso de Buy para la mayoría de las empresas SaaS. Gong lleva años refinando la puntuación de llamadas de IA, tiene modelos entrenados en millones de llamadas de ventas e integra con todos los CRM principales. Construir un análisis de llamadas de IA propio no hace a la empresa más competitiva; solo retrasa la obtención del valor mientras se reinventa algo que ya funciona. El artículo Buy vs. build by pattern mapea esta decisión en cada patrón ACE para que se pueda aplicar de forma consistente a cada capacidad de IA que se evalúe.
La deflección de soporte mediante chatbot de IA es similar. Intercom Fin, Zendesk AI y productos similares tienen modelos sólidos ajustados para la resolución de soporte. Su IA mejora con las interacciones de soporte de todos los clientes, no solo los propios. Si se hace wrap de una API de LLM para un bot de soporte propio, el modelo comienza en frío mientras ellos han tenido datos de entrenamiento durante años.
La regla: Comprar cuando el caso de uso es estandarizado, el proveedor tiene ventajas reales de datos de entrenamiento sobre una llamada fresca a la API de LLM, y la diferenciación en este caso de uso no impulsa la elección del cliente.
Los clientes no eligen el producto SaaS porque el chatbot de soporte tenga una personalidad única. Lo eligen por la capacidad central del producto. Comprar la IA de soporte e invertir el tiempo de ingeniería de IA donde importa.
El perfil de costo de comprar: $15,000-80,000 por año por herramienta para SaaS de mercado medio. La decisión de compra con 10 herramientas es una línea presupuestaria significativa. Pero es predecible y no requiere headcount de ingeniería para mantenimiento.
Cuándo hacer wrap (Wrap)
El wrap es correcto cuando se necesita IA en la superficie del propio producto, el caso de uso es lo suficientemente específico como para que las herramientas genéricas de proveedores no encajen, y aún no hay suficientes datos propietarios para justificar el entrenamiento de modelos personalizados.
Los AI copilots en producto son el caso de uso canónico de Wrap. Si el SaaS es una herramienta de gestión de proyectos y se quiere añadir un asistente de IA que ayude a los usuarios a redactar descripciones de tareas, auto-sugerir dependencias y resumir el estado del proyecto para los stakeholders, no hay ningún proveedor que haga exactamente esto para el modelo de datos propio. Hay que construirlo, pero no hay que entrenar un modelo. Se hace Wrap de una API de LLM: se le pasa contexto de la base de datos, se diseña el prompt cuidadosamente, se gestiona el resultado en la UI. El artículo AI Copilots Embebidos en la UI del Producto SaaS cubre las decisiones de diseño de producto que siguen a la elección de construir/wrap.
El wrap también es correcto para funciones de IA en flujos de trabajo que son específicos del caso de uso del producto. Si la herramienta SaaS es una plataforma de documentos legales y se quiere que la IA señale cláusulas de contrato potencialmente problemáticas, no hay que entrenar un modelo en derecho contractual. Se hace wrap de Claude o GPT-4 con un system prompt bien diseñado que incluye el marco de evaluación de cláusulas. La versión 1 se lanza en semanas, no meses.
La regla: Hacer wrap cuando la función requiere el contexto del propio producto, cuando ningún proveedor tiene una solución pre-construida que encaje, y cuando el equipo carece de la experiencia en ML o los datos para construir modelos personalizados.
El perfil de costo del wrap: Aquí es donde los equipos se sorprenden. Los precios de la API de LLM con bajo uso son triviales. A escala, no lo son.
GPT-4o de OpenAI a $2.50 por millón de tokens de entrada y $10 por millón de tokens de salida suena barato. Hacer el cálculo para 10,000 MAUs (monthly active users) cada uno generando 20 completions de IA por mes, con un promedio de 2,000 tokens de entrada y 500 tokens de salida por llamada:
- Entrada mensual: 10,000 x 20 x 2,000 = 400M tokens x $2.50/M = $1,000
- Salida mensual: 10,000 x 20 x 500 = 100M tokens x $10/M = $1,000
- Costo mensual de LLM: $2,000
Eso es manejable. Pero si 100 usuarios avanzados ejecutan 500 completions cada uno en lugar de 20, y sus prompts tienen 5,000 tokens con 2,000 tokens de salida:
- Entrada mensual: 100 x 500 x 5,000 = 250M tokens x $2.50/M = $625
- Salida mensual: 100 x 500 x 2,000 = 100M tokens x $10/M = $1,000
Sigue siendo manejable. El riesgo real aparece cuando se ha fijado un precio plano para la función de IA (sin límites de uso) y no se ha modelado el usuario del percentil 95. Un solo cliente empresarial con 200 usuarios activos cada uno ejecutando 100 completions diarios puede costar $40,000-60,000/mes en costos de API si no hay guardas de consumo.
El wrap requiere arquitectura de consumo desde el principio. Los límites de tasa por usuario, los dashboards de uso y los caps de consumo en los tiers de precio plano no son funciones opcionales para añadir después.
Los precios de Anthropic y Google siguen patrones similares, con Claude 3.5 Sonnet a $3/M de entrada y $15/M de salida en 2026. Los cálculos no cambian materialmente por la elección del modelo. El requisito de arquitectura es el mismo.
Cuándo construir (realmente construir)
Construir modelos personalizados se justifica cuando tres condiciones son todas verdaderas simultáneamente:
- Los propios datos crean una ventaja defendible que un proveedor no puede replicar con sus datos de entrenamiento genéricos
- La función de IA es central para la diferenciación del producto (los clientes lo eligen en parte por ella)
- La empresa tiene o puede contratar talento de ingeniería de ML
Si alguna de estas tres condiciones es falsa, el wrap sirve mejor.
La condición del moat de datos SaaS es la más importante. Si el producto genera datos de comportamiento únicos a escala, esos datos son un activo para el entrenamiento del modelo. GitHub tenía esto para la completación de código: los repositorios de código de millones de desarrolladores, cada uno con historial de commits, feedback de revisión de código y contexto de autoría. Ningún competidor podía comprar ese conjunto de datos. La calidad de Copilot es en parte una función de la posición de datos única de GitHub.
La mayoría de las empresas SaaS no tienen ese moat en Series A o B. Tienen 500-5,000 clientes. Sus datos son valiosos para el diseño de prompts y la recuperación RAG, pero no son suficientemente grandes ni únicos para mejorar significativamente un modelo fine-tuned sobre un modelo base bien prompeado. Construir antes de que exista el moat de datos es quemar recursos de ingeniería para obtener peores resultados que el wrap.
La regla: Construir cuando los propios datos propietarios a escala crean una calidad del modelo que el wrap no puede replicar, y cuando esa calidad es la razón por la que los clientes pagan.
El perfil de costo de construir: Las ejecuciones de entrenamiento de modelos son $50,000-500,000+ para un fine-tuning significativo. Los salarios de los ingenieros de ML en 2026 son $200,000-350,000 totalmente cargados. La infraestructura de inferencia en producción cuesta $10,000-50,000/mes a escala SaaS. Se añaden 6-12 meses de tiempo hasta producción y el costo de oportunidad de no lanzar funciones de producto durante ese período. El análisis de Forrester sobre build vs. buy en la era de la IA señala que 3 de cada 4 empresas que intentan construir arquitecturas de IA agéntica completamente en casa fracasan, porque estas arquitecturas requieren stacks RAG sofisticados, pipelines de datos avanzados y experiencia especializada en ML que la mayoría de los equipos SaaS no tienen en la Etapa 2 o 3.
Por debajo de $20M de ARR, esta estructura de costos es difícil de justificar a menos que la IA sea literalmente el producto. Por encima de $50M de ARR con evidencia sólida de moat de datos, puede ser la inversión correcta.
Los riesgos ocultos que hay que considerar
Cada opción tiene costos que no aparecen en la estimación presupuestaria inicial.
El costo oculto de comprar: Dependencia del proveedor. Cuando Gainsight cambia su modelo de precios (ocurre), el presupuesto de operaciones de CS cambia sin intervención propia. Cuando Gong depreca una función alrededor de la cual se construyó un flujo de trabajo, hay que reconstruir el flujo. Más importante: la mejora de la IA se acumula en el modelo del proveedor, no en el propio. Cada llamada de ventas procesada a través de Gong entrena el modelo de Gong, no el propio. Se está mejorando su producto. En la madurez de la Etapa 4, esto importa porque el moat de datos no se construye cuando se compra. El artículo sobre estrategias de mitigación del lock-in de proveedores de IA cubre cómo proteger la flexibilidad incluso dentro de las decisiones de Buy.
El costo oculto del wrap: Deprecación del modelo. OpenAI deprecó GPT-4 32k y varios otros modelos con 6-12 meses de aviso. Si la arquitectura del wrap está estrechamente acoplada a una versión específica del modelo, la migración es un proyecto de ingeniería significativo. La arquitectura correcta envuelve el modelo detrás de una capa de abstracción para poder intercambiar modelos subyacentes sin reescribir el código de la función de IA.
El costo oculto de construir: No es solo el costo inicial. Los modelos necesitan mantenimiento. Los pipelines de datos necesitan monitoreo. El rendimiento del modelo se degrada a medida que el mundo cambia y los datos de entrenamiento se vuelven obsoletos. El equipo que se contrata para construir el modelo inicial es ahora el equipo responsable de mantenerlo, monitorearlo y reentrenarlo. Este es un costo operativo continuo que las opciones de buy y wrap no imponen.
"Las empresas que saltan directamente a Build en la Etapa 1 gastan $800,000 en ingeniería de ML y terminan con un copilot peor que el que habría producido una suscripción a la API de Anthropic de $200/mes. Comprar las herramientas GTM de IA. Hacer wrap de las APIs de LLM para la IA de producto. Reservar Build para los casos de uso del moat de datos propietarios." (Rework Analysis, 2025)
"La deprecación del modelo es el costo oculto del Wrap que los equipos no presupuestan. OpenAI deprecó GPT-4 32k y varios otros modelos con 6-12 meses de aviso. Si la arquitectura del wrap está estrechamente acoplada a una versión específica del modelo, la migración es un proyecto de ingeniería significativo. La arquitectura correcta envuelve el modelo detrás de una capa de abstracción para poder intercambiar modelos subyacentes sin reescribir el código de la función de IA." (Rework Analysis, 2025)
Buy vs. Wrap vs. Build: Matriz de Decisión
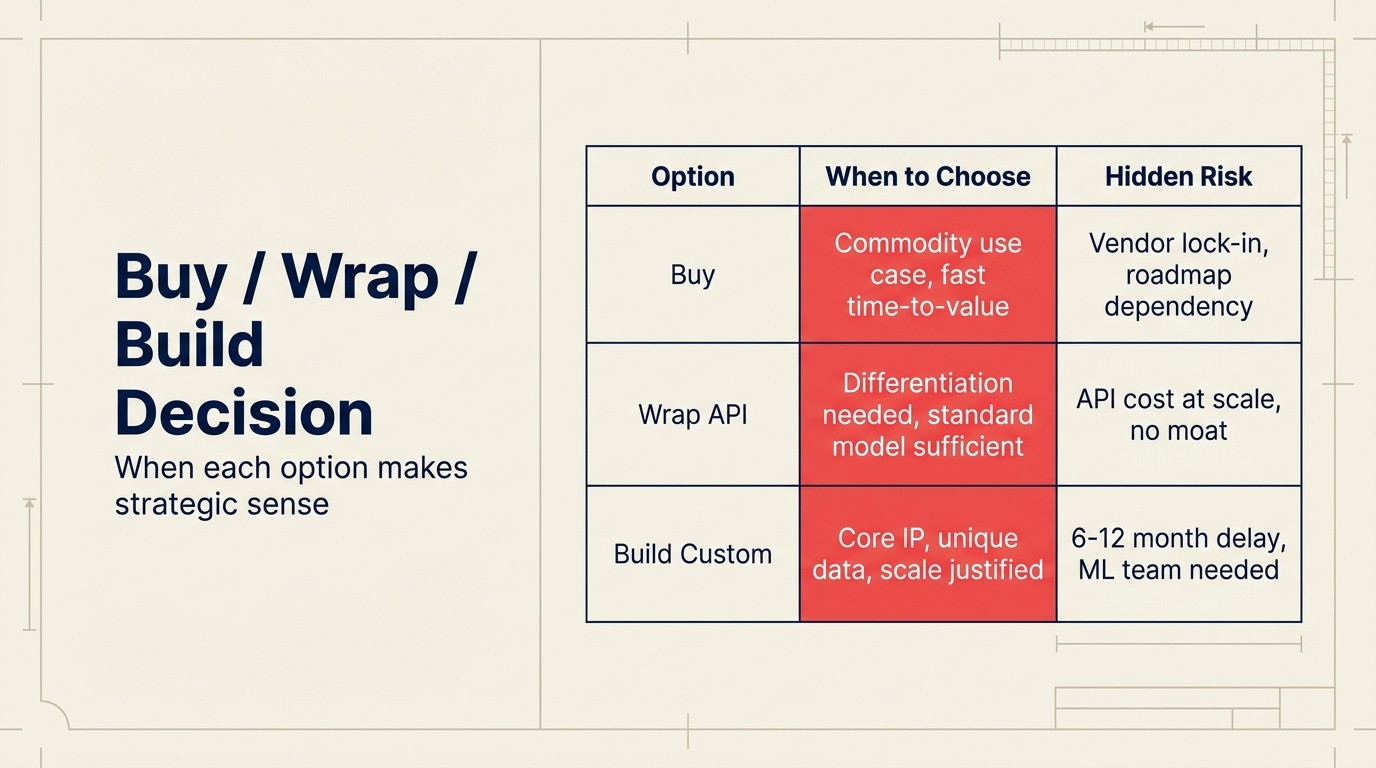
| Decisión | Ejemplo de Caso de Uso | Tiempo de Despliegue | Perfil de Costo | Diferenciación |
|---|---|---|---|---|
| Buy | Puntuación de llamadas de IA (Gong), puntuación de salud de CS (Gainsight), deflección de soporte (Intercom Fin) | Semanas | $15,000-80,000/año por herramienta | Limitada; el proveedor mejora el modelo genérico, no el propio |
| Wrap | AI copilot en producto, resumen de documentos con IA, personalización del onboarding | 4-8 semanas | $2,000-10,000/mes a escala media; mayor con usuarios avanzados | Alta; se controla la experiencia y el contexto |
| Build | Completación de código con entrenamiento en codebase (GitHub Copilot), detección de fraude en transacciones propietarias | 6-12 meses | $50,000-500,000+ entrenamiento; $10,000-50,000/mes inferencia | Máxima; moat de datos propietarios |
Fuentes: Forrester Build vs. Buy in the Age of AI 2025, Ptolemay LLM TCO Research 2025, Vendasta Build vs. Buy AI Analysis 2026
Rework Analysis: El error más costoso en inversión de IA SaaS es construir modelos personalizados antes de que exista el moat de datos. La mayoría de las empresas de Series A-B tienen 500-5,000 clientes. Sus datos son valiosos para el diseño de prompts y la recuperación RAG, pero no son suficientemente grandes ni únicos para mejorar significativamente un modelo fine-tuned sobre un modelo base bien prompeado. Los equipos que evalúan Build antes de confirmar las tres condiciones (ventaja de datos defendible, diferenciador central del producto, talento de ML disponible) están quemando capital de ingeniería para obtener peores resultados que los que produciría el wrap. Ejecutar primero el test de dos preguntas: ¿esta función requiere el contexto y los datos específicos de la empresa? ¿Es esta una razón por la que los clientes nos eligen versus una función de soporte que aprecian?
Un marco de decisión para tomar la determinación
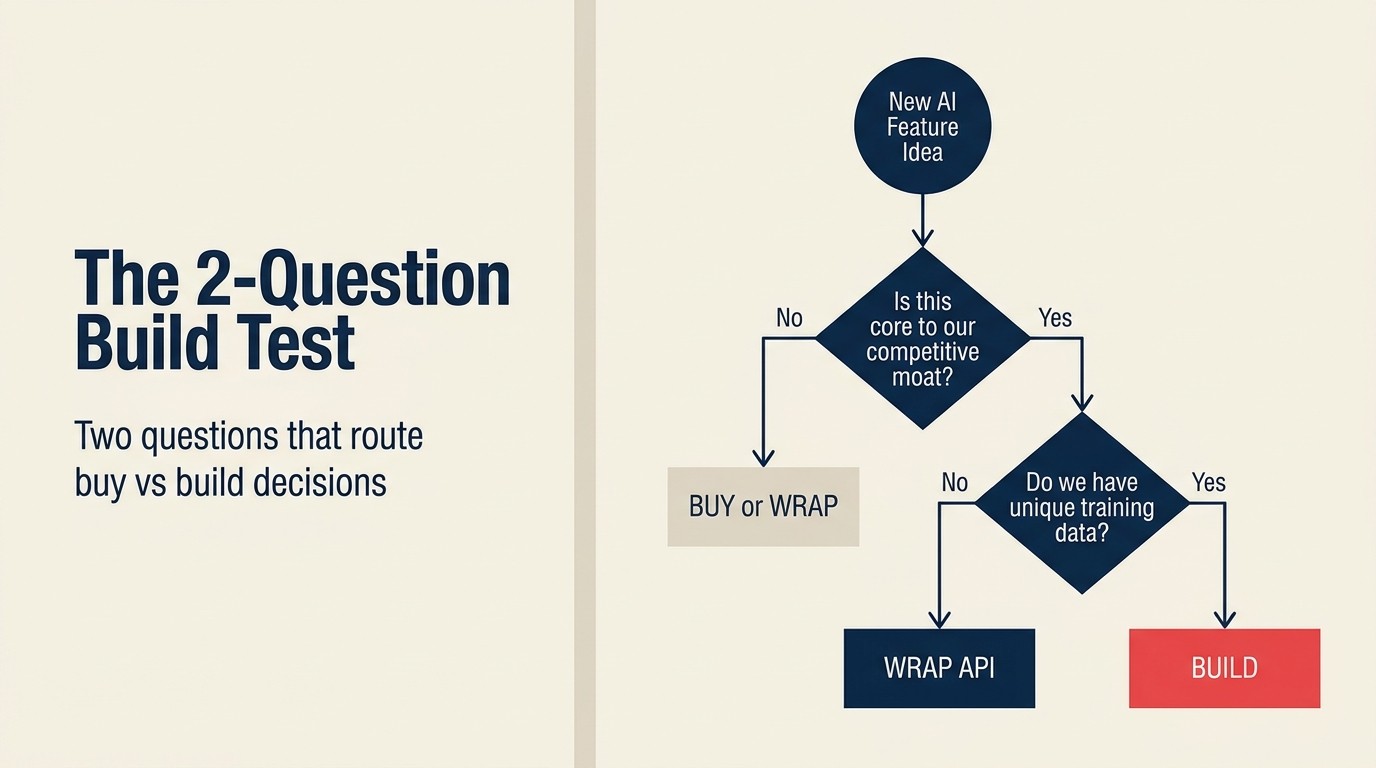
La versión más simple es un test de dos preguntas:
- ¿Esta función de IA requiere el contexto y los datos específicos de la empresa para ser significativamente mejor que una solución genérica de proveedor?
- ¿Es esta función de IA algo por lo que los clientes eligen explícitamente el producto, versus una función de soporte que aprecian pero no evalúan contra alternativas?
Si la respuesta a la pregunta 1 es no: Buy. Si la respuesta a la pregunta 1 es sí y a la pregunta 2 es no: Wrap. Si la respuesta a ambas es sí, y se tienen los datos y el talento: Build.
Aplicar esto a escenarios específicos:
| Función | Decisión | Por qué |
|---|---|---|
| Puntuación de llamadas de IA para el equipo de ventas | Buy (Gong) | Ventaja de datos de entrenamiento del proveedor; no diferencia el producto |
| Puntuación de salud de CS | Buy (Gainsight/Vitally) | Bien servido por proveedores; no es superficie del producto |
| AI copilot en producto | Wrap | Requiere el contexto de los propios datos; diferencia el producto |
| Resumen de documentos con IA | Wrap | La calidad del LLM es suficiente; sin ventaja de datos de entrenamiento |
| Completación de código de IA (si eres GitHub) | Build | Datos de entrenamiento propietarios; diferenciador central del producto |
| Detección de fraude en los propios datos de transacciones | Build (eventualmente) | Moat de datos propietarios; central para la confianza en el producto |
El marco indica qué elección hacer. La secuenciación indica cuándo.
La secuenciación que funciona en la práctica
Para la mayoría de las empresas SaaS en madurez de Etapa 2-3:
- Comprar las herramientas GTM de IA (Gong, Gainsight, Intercom AI) en los primeros 6 meses. Obtener los datos sobre cómo se ven los buenos resultados asistidos por IA en el contexto propio.
- Hacer wrap de APIs de LLM para las funciones de IA en producto comenzando en la Etapa 2. No esperar hasta la Etapa 4 para añadir IA al producto.
- Evaluar Build en la Etapa 4 cuando haya 18-24 meses de datos de comportamiento de usuarios, una hipótesis clara de moat de datos y un ARR que soporte headcount de ML.
Las empresas que saltan directamente a Build en la Etapa 1 son las que gastan $800,000 en ingeniería de ML y terminan con un copilot peor que el que habría producido una suscripción a la API de Anthropic de $200/mes. Los benchmarks de SaaS de OpenView sobre precios basados en uso muestran que las empresas con la mayor retención neta en dólares son a menudo las que compraron herramientas de IA de primera clase para GTM e hicieron wrap de APIs para la IA de producto, en lugar de intentar construir modelos propietarios antes de que el volumen de datos lo justificara.
Por defecto, comprar para IA GTM. Por defecto, wrap para IA de producto. Reservar build para los casos de uso del moat de datos propietarios. Luego revisar a medida que los datos se acumulan.
Preguntas Frecuentes
¿Qué es the Buy/Wrap/Build Decision para funciones de IA en SaaS?
Un marco de tres vías que reemplaza el binario clásico de "construir vs. comprar" con una tercera opción específica para SaaS. Buy: comprar un producto de proveedor de IA dedicado. Wrap: usar APIs de LLM para construir funciones de IA dentro del propio producto con el propio contexto y prompts. Build: entrenar o hacer fine-tune a modelos personalizados con datos propietarios. La mayoría de las empresas SaaS evalúan por defecto solo Buy o Build y omiten Wrap, que a menudo es la elección correcta para las funciones de IA en producto.
¿Cuándo debería una empresa SaaS elegir Buy sobre Wrap?
Cuando el caso de uso es bien comprendido, bien servido por proveedores existentes, el tiempo hasta obtener valor importa más que la diferenciación, y el proveedor tiene ventajas reales de datos de entrenamiento. El análisis de llamadas de ventas, la puntuación de salud de CS y la deflección de soporte de IA son casos de uso de Buy para la mayoría de las empresas SaaS. Los proveedores llevan entrenando en millones de interacciones. Un wrap de API de LLM fresco comienza en frío por comparación.
¿Cuándo es el Wrap la elección correcta?
Cuando se necesita IA dentro de la superficie del propio producto, el caso de uso es específico del modelo de datos propio, y aún no hay suficientes datos propietarios para justificar el entrenamiento de modelos personalizados. Los AI copilots en producto, el resumen de documentos con IA en el contexto del propio producto y las sugerencias de flujos de trabajo impulsadas por IA son casos de uso canónicos de Wrap. Se necesita el contexto del propio producto como contexto. Ningún proveedor tiene una solución pre-construida que encaje. Y no se necesita experiencia en ML para lanzarlo.
¿Cuáles son los riesgos de costo de consumo del Wrap que los equipos pasan por alto?
Los precios de la API de LLM escalan con el uso, no con los asientos. Los equipos modelan al usuario mediano y se pierden al usuario avanzado del percentil 95. Un solo cliente empresarial con 200 usuarios activos ejecutando 100 completions de IA diarios puede generar $40,000-60,000/mes en costos de API si no hay guardas de consumo. Tres decisiones de arquitectura requeridas antes de lanzar cualquier función de Wrap a precio plano: límites de consumo por usuario por tier, monitoreo de uso con alertas automáticas al 150% del consumo modelado, y precios basados en consumo para clientes empresariales con alto uso esperado.
¿Qué condiciones deben ser verdaderas antes de construir modelos personalizados?
Las tres condiciones deben cumplirse simultáneamente: los propios datos crean una ventaja defendible que un proveedor no puede replicar con datos de entrenamiento genéricos; la función de IA es central para la diferenciación del producto (los clientes lo eligen en parte por ella); y la empresa tiene o puede contratar talento de ingeniería de ML. Si alguna de las tres es falsa, el Wrap sirve mejor. La condición del moat de datos es la más importante.
¿Cuál es el costo oculto de Buy que los equipos subestiman?
La dependencia del proveedor y la erosión del moat de datos. Cada llamada de ventas procesada a través de Gong entrena el modelo de Gong, no el propio. Cada ticket de soporte a través de Intercom Fin mejora el modelo de recuperación de Intercom. Se está mejorando sus productos sin construir ninguna ventaja propietaria. En la madurez de la Etapa 4, esto importa porque la mejora de la IA se acumula en el modelo del proveedor en lugar del propio flywheel de datos.
Aprenda Más:
- Buy vs. Build by Pattern: la decisión mapeada en cada patrón ACE
- Build vs. Buy vs. Integrate Decision: el marco de decisión a nivel estratégico para infraestructura de IA
- AI Vendor Lock-In Mitigation Strategies: cómo proteger la flexibilidad dentro de las decisiones de Buy
- Las Etapas de Madurez de IA en SaaS: cómo las decisiones de buy/wrap/build cambian según las etapas
- AI Copilots Integrados en la UI del Producto SaaS: decisiones de diseño de producto que siguen a una elección de Wrap
- La Carrera Armamentista de IA en SaaS: Velocidad para Lanzar: contexto competitivo para la decisión de build/buy

Co-Founder, Rework.com
On this page
- The Buy/Wrap/Build Decision
- Definiendo las tres opciones
- Cuándo comprar (Buy)
- Cuándo hacer wrap (Wrap)
- Cuándo construir (realmente construir)
- Los riesgos ocultos que hay que considerar
- Buy vs. Wrap vs. Build: Matriz de Decisión
- Un marco de decisión para tomar la determinación
- La secuenciación que funciona en la práctica