Telemetrie-Loops für In-Produkt-KI: Feedback aufbauen, das sich kumuliert
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GitHub Copilot wird messbar besser alle paar Monate. Diese Verbesserung kommt nicht davon, dass GitHub-Ingenieure härter am Modell arbeiten. Sie kommt von Millionen von Entwicklern, die täglich Copilot-Vorschläge annehmen, modifizieren und ablehnen. Jede Interaktion ist ein Datenpunkt. Jeder Datenpunkt speist die nächste Modellversion. Das Produkt verbessert sich, weil Menschen es nutzen.
Das ist ein Telemetrie-Loop: ein strukturiertes System, das erfasst, was ein KI-Feature vorgeschlagen hat, was ein Nutzer als nächstes tat und welches Ergebnis folgte. Es ist der Unterschied zwischen einem KI-Feature, das auf seiner Launch-Qualität stagniert, und einem, das sich kumuliert verbessert.
Die meisten SaaS-Teams, die KI-Features bauen, überspringen dies. Sie shippen das Feature. Sie beobachten die Adoptionszahlen. Sie erklären Erfolg, wenn die Adoption steigt. Und dann, sechs Monate später, fragen sie sich, warum ihre KI-Vorschläge noch generisch wirken und warum der Churn unter KI-Feature-Nutzern nicht besser ist als unter Nicht-Nutzern.
Die Schleife ist der Punkt. Das ursprüngliche Modell ist nur der Ausgangszustand.
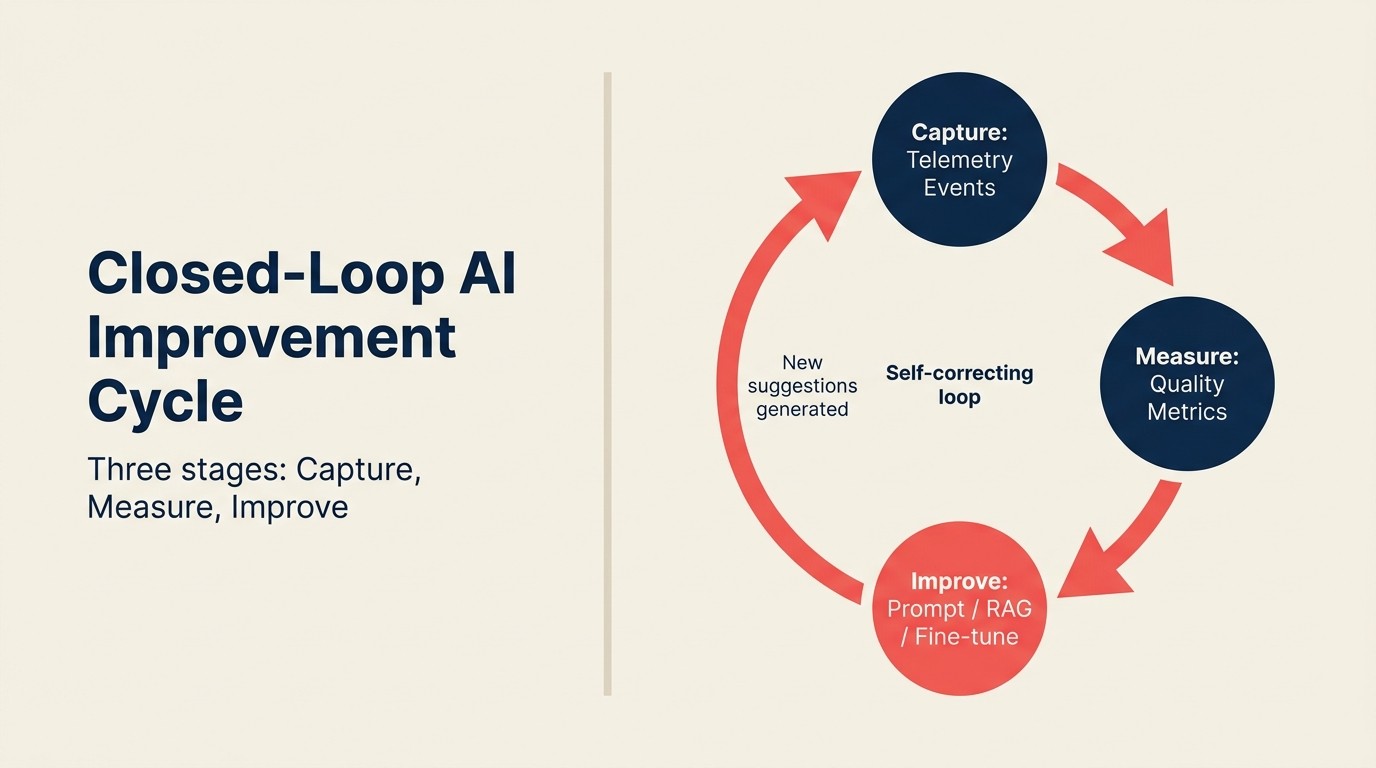
Der Closed-Loop AI Improvement Cycle
Der Closed-Loop AI Improvement Cycle ist ein dreistufiges Feedback-System, das die In-Produkt-KI-Nutzung in kontinuierliche Modellverbesserung umwandelt. Capture: Strukturierte Telemetrie-Events zeichnen auf, was die KI vorgeschlagen hat, was der Nutzer als nächstes tat und das nachgelagerte Ergebnis. Measure: Aggregierte Signale berechnen Qualitätsmetriken nach Vorschlagstyp (Akzeptanzrate, Modifikationsrate, Ergebnis-Korrelation). Improve: Qualitätsmetriken werden an den entsprechenden Verbesserungsmechanismus weitergeleitet (Prompt Engineering für API-basierte Features, Retrieval-Parameter-Anpassung für RAG-Features oder Fine-Tuning-Daten für angepasste Modelle). Der Zyklus schließt sich, wenn Verbesserungen neue Vorschläge generieren, die neue Capture-Events erzeugen. Eine Schleife, die bei Capture stoppt (Events protokollieren ohne Messen oder Verbessern), ist keine Schleife. Es ist ein Archiv.
Was ein Telemetrie-Loop eigentlich ist
Ein Telemetrie-Loop hat drei Stufen, die der Ingest-Fähigkeit des ACE Frameworks entsprechen:
Capture: Strukturierte Signale aus jeder KI-Feature-Interaktion sammeln. Was wurde vorgeschlagen, was wurde angezeigt, was war der Kontext. Das entspricht direkt der Ingest-Fähigkeit des ACE Frameworks.
Measure: Diese Signale zu Qualitätsmetriken aggregieren. Vorschlag-Akzeptanzrate, Modifikationsrate, Ergebnis-Korrelation.
Improve: Die gemessenen Signale zurück an die Modellverbesserung, Prompt-Verfeinerung oder Retrieval-Parameter-Anpassung weiterleiten.
Ohne alle drei Stufen haben Sie keine Schleife. Die meisten Teams haben die erste Stufe (sie protokollieren Events irgendwo), überspringen die zweite (sie haben keine Qualitätsmetriken) und erreichen die dritte nie (die Daten sitzen in einem Data Warehouse und niemand handelt daraufhin).
Eine echte Schleife schließt sich. Der Output von Improve speist das Verhalten des KI-Features zurück, das neue Capture-Daten generiert. Das System korrigiert sich im Laufe der Zeit selbst.
Key Facts: Telemetrie-Loops und KI-Verbesserung
- LinkedIns Verhaltens-Signal-Experimente zeigten, dass Verhaltens-Signale Content-Qualität 4-6x besser vorhersagten als explizite Bewertungen, weshalb implizites Feedback (annehmen/modifizieren/ablehnen) das hochwertige Signal in KI-Telemetrie-Loops ist
- GitHub Copilot schreibt fast die Hälfte des Codes eines Entwicklers, und kontrollierte Tests zeigen, dass Entwickler Aufgaben 55 % schneller erledigen; diese Qualität wurde durch Millionen von Akzeptanz- und Ablehnungssignalen von 15M+ Nutzern erreicht, nicht durch statische Modellverbesserung (Second Talent, 2025)
- McKinsey beschreibt die Kumulations-Dynamik explizit: schnellere Experimente generieren mehr Daten, mehr Daten verbessern die Modellqualität, bessere Performance zieht mehr Nutzer an, und die Lücke zwischen Organisationen, die diese Schleifen betreiben, und denen, die es nicht tun, wird strukturell (McKinsey State of AI, 2025)
Die drei Signal-Typen aus In-Produkt-KI

Nicht jedes Feedback ist gleich. Die drei Typen unterscheiden sich erheblich in Volumen, Genauigkeit und dem Aufwand der Erfassung.
Explizites Feedback ist am leichtesten zu verstehen und in der Praxis am wenigsten nützlich. Daumen hoch, Daumen runter, „War das hilfreich?"-Abfragen. Nutzer geben explizites Feedback selten und inkonsistent. Jemand, der einmal auf Daumen runter klickt und dann nie wieder, hat nicht aufgehört, Meinungen zu haben. Er hat aufgehört zu klicken. LinkedIn führte Experimente zu expliziten Feedback-Mechanismen durch und stellte fest, dass Verhaltens-Signale Content-Qualität 4-6x besser vorhersagten als explizite Bewertungen. Dasselbe Muster gilt in Produktkontexten.
Implizites Feedback ist der Ort, an dem das Signal lebt. Nutzer klicken nicht auf Daumen runter, aber sie verhalten sich ehrlich. Sie nehmen einen Vorschlag an, bearbeiten einen Vorschlag, ignorieren einen Vorschlag oder machen das Ergebnis rückgängig und erledigen die Aufgabe manuell. Diese Aktionen sagen mehr über Qualität aus als jedes Bewertungssystem.
Die zwei impliziten Metriken, die am meisten zählen, sind:
- Vorschlag-Akzeptanzrate: Welchen Prozentsatz der KI-Vorschläge verwendet der Nutzer ohne Modifikation?
- Modifikationsrate: Von den Vorschlägen, die Nutzer annehmen, wie viele bearbeiten sie vor der Fertigstellung?
Eine hohe Modifikationsrate sagt Ihnen, dass die KI-Richtung stimmt, aber die Details nicht. Eine niedrige Akzeptanzrate mit hoher manueller Vervollständigungsrate sagt Ihnen, dass der Vorschlag-Einfügepunkt falsch oder die Qualitätsschwelle zu niedrig ist. Das sind verschiedene Probleme mit verschiedenen Lösungen.
Outcome-Feedback ist am schwierigsten zu erfassen und am wertvollsten. Hat die KI-unterstützte Aufgabe ein besseres Ergebnis erzeugt als das manuelle Äquivalent? Hat die KI-verfasste E-Mail eine Antwort erhalten? Hat die KI-generierte Support-Antwort das Ticket ohne Eskalation gelöst? Hat die KI-vorgeschlagene nächste Aktion im CRM zu einem gebuchten Meeting geführt?
Outcome-Feedback erfordert die Verbindung Ihrer KI-Telemetrie mit Ihren nachgelagerten Geschäftsergebnissen, was normalerweise das Zusammenführen von Event-Daten mit CRM- oder Support-Ticket-Daten bedeutet. Es ist eine Engineering-Investition. Aber wenn Sie es haben, können Sie die Frage beantworten, die jeden Produktverantwortlichen tatsächlich interessiert: Macht unsere KI Kunden erfolgreicher, oder generiert sie nur Aktivität?
Warum implizites Feedback explizites übertrifft
Die Verhaltensökonomie hier ist über Produkte hinweg konsistent. Menschen berichten ihre Präferenzen nicht genau. Sie sagen, sie wollen eine Sache, und tun eine andere. Das gilt für KI-Feature-Feedback in genau derselben Weise wie für Umfrageantworten zu Produktfeatures.
Aber praktischer: Das Verhältnis von implizitem zu explizitem Feedback in den meisten Produkten liegt bei etwa 50-zu-1 oder höher. Für jeden Nutzer, der auf Daumen runter klickt, haben fünfzig Nutzer ein Verhaltens-Signal von gleichwertiger oder höherer Qualität gegeben. Nur für explizites Feedback zu optimieren bedeutet, 98 % des verfügbaren Signals zu ignorieren.
Notion AI lernte dies früh. Ihre KI-Schreib-Vorschläge werden basierend darauf verfeinert, wie Nutzer vorgeschlagenen Text annehmen, modifizieren oder ersetzen, nicht primär basierend auf expliziten Bewertungen. Die Produktingenieure können im Aggregat sehen, welche Vorschlagstypen so verwendet werden, wie sie sind, im Vergleich zu umgeschriebenen oder ignorierten. Diese Aggregatansicht beeinflusst die Prompt-Engineering- und Modellauswahlentscheidungen für die nächste Version.
Dasselbe Muster ist in Linears KI-Feature-Entwicklung sichtbar. Ihre Bug-Triage- und Prioritäts-Vorschläge werden durch die Kombination verfeinert, welche KI-vorgeschlagenen Prioritäten Ingenieure überschreiben, und wie oft manuell überschriebene Prioritäten sich als passend zur tatsächlichen Lösungsdringlichkeit herausstellen.
„Das Verhältnis von implizitem zu explizitem Feedback in den meisten Produkten liegt bei 50-zu-1 oder höher. Für jeden Nutzer, der auf Daumen runter klickt, haben fünfzig Nutzer ein Verhaltens-Signal von gleichwertiger oder höherer Qualität gegeben. Nur für explizites Feedback zu optimieren bedeutet, 98 % des verfügbaren Signals zu ignorieren." (Rework Analysis, basierend auf LinkedIns Verhaltensökonomie-Forschung)
„Statische KI-Features sind nicht neutral. Sie sind eine Kostenstelle ohne kumulativen Mehrwert. Jeden Monat, in dem ein Feature sich durch Telemetrie nicht verbessert, wird die Lücke zwischen seiner Qualität und einem Wettbewerber, der eine echte Schleife betreibt, größer. Die Entscheidung, die Schleife zu bauen, ist die KI-Infrastruktur-Entscheidung. Die Modellwahl ist weniger wichtig." (Rework Analysis, 2025)
Vergleich von Signal-Qualität und -Volumen
| Signal-Typ | Erfassungsschwierigkeit | Volumen | Qualität/Genauigkeit | Primäre Verwendung |
|---|---|---|---|---|
| Explizit (Daumen hoch/runter) | Einfach | Sehr niedrig (2-3 % der Interaktionen) | Schlecht (inkonsistente Selbstauskunft) | Seltene Randfall-Markierung |
| Implizite Annahme | Mittel | Hoch (jeder gezeigte Vorschlag) | Gut (ehrliches Verhaltens-Signal) | Akzeptanzrate, Modellverbesserung |
| Implizite Modifikation | Mittel | Hoch (jeder angenommene Vorschlag) | Sehr gut (zeigt Präferenzlücke) | Prompt Engineering, Spezifitäts-Tuning |
| Outcome-Feedback | Schwer (erfordert Datenzusammenführung) | Niedrig (Teilmenge der Sitzungen) | Ausgezeichnet (misst tatsächlichen Mehrwert) | ROI-Messung, Trainings-Signal |
Quellen: LinkedIn AI Behavioral Signal Research, Notion AI Telemetry Documentation, McKinsey AI Software Development Research 2025
Rework Analysis: Die meisten SaaS-Teams haben Stufe 1 des Telemetrie-Loops (Events protokollieren) und überspringen die Stufen 2 und 3 (Qualitätsmetriken messen und darauf reagieren). Die Daten sitzen in einem Warehouse und niemand schaut wöchentlich darauf. Der Minimum Viable Loop besteht aus vier Komponenten: suggestion_shown, suggestion_accepted und suggestion_modified Events in Segment oder Amplitude; ein wöchentliches Akzeptanzrate-Dashboard nach Feature; ein zweiwöchentliches Prompt-Review-Meeting, bei dem jemand tatsächlich die Daten liest; und eine Verpflichtung, Prompt-Änderungen für die schwächsten Vorschlagstypen zu shippen. Das ist die ganze Schleife.
Schema-Design für KI-Telemetrie

Das Event-Schema ist wichtig. Vage Events erzeugen vage Signale. Wenn Ihre Telemetrie wie ai_feature_used: true aussieht, können Sie keine Modifikationsrate berechnen, Sie können nicht nach Vorschlagstyp segmentieren, und Sie können nicht mit Ergebnissen korrelieren.
Ein minimales KI-Telemetrie-Schema sieht so aus:
suggestion_id: UUID (verbindet den Vorschlag durch seinen Lebenszyklus)
feature_id: string (welches KI-Feature dies generiert hat)
session_id: string (verbindet mit Nutzersitzungskontext)
context_hash: string (Fingerabdruck des Kontexts, den die KI erhalten hat)
suggestion_type: enum (draft, autocomplete, classification, recommendation)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp or null
suggestion_modified: boolean
modification_delta: integer (Zeichen-Bearbeitungsabstand vom Vorschlag zum Endstand)
user_dismissed: boolean
manual_completion: boolean (Nutzer hat die Aufgabe ohne Nutzung des Vorschlags erledigt)
outcome_event_id: string or null (FK zu nachgelagertem Ergebnis, falls erfasst)
Dieses Schema ermöglicht es Ihnen, jede Metrik zu berechnen, die für die Telemetrie-Loop-Qualität wichtig ist. Der context_hash ist besonders wichtig: Er ermöglicht es Ihnen zu identifizieren, ob ähnliche Kontexte im Laufe der Zeit konsistent bessere oder schlechtere Vorschläge erhalten, was die Kernmessung für Modellverbesserung ist.
Für Teams, die Segment oder Amplitude als Event-Pipeline verwenden, lässt sich dieses Schema sauber auf ein benutzerdefiniertes Event mit Standardeigenschaften abbilden. Die outcome_event_id-Zusammenführung erfordert entweder einen serverseitigen Anreicherungsschritt oder eine nachgelagerte Zusammenführung in Ihrem Data Warehouse.
Die Schleife für die Modellverbesserung nutzen
Was Sie mit den Telemetrie-Daten tun, hängt davon ab, wie Ihr KI-Feature gebaut ist.
Für GPT-4- oder Claude-API-basierte Features (der häufigste Fall für SaaS-KI im Jahr 2026) ist der Verbesserungsmechanismus Prompt Engineering. Eine hohe Modifikationsrate bei einem bestimmten Vorschlagstyp sagt Ihnen, dass der Prompt nicht spezifisch genug ist. Konsistente manuelle Vervollständigung nach KI-Vorschlag sagt Ihnen, dass der Vorschlag zum falschen Zeitpunkt im Workflow erscheint. Sie können Prompts wöchentlich iterieren, ohne das zugrunde liegende Modell anzufassen.
Für RAG (Retrieval-Augmented Generation) Features (KI, die vor der Generierung aus einer Wissensbasis abruft) speist Telemetrie die Retrieval-Parameter-Anpassung. Wenn Nutzer KI-Vorschläge, die einen bestimmten Wissensabschnitt zitieren, konsistent ignorieren, ist dieser Abschnitt entweder veraltet oder irrelevant. Telemetrie sagt Ihnen, welche Retrieval-Quellen tatsächlich verwendete Vorschläge versus Rauschen erzeugen. KI-gestützte Wissensbasis-Pflege für SaaS behandelt, wie man auf diese Signale reagiert, um das Retrieval-Corpus aktuell zu halten.
Für Fine-tuned oder angepasste Modelle (selten für Series A-C SaaS) werden hochwertige implizite Feedbacks mit Ergebnis-Labels zu Trainingsdaten. Die Modifikationsrate-Daten sind effektiv ein Präferenz-Datensatz. Die Ergebnis-Korrelations-Daten sind ein Reinforcement-Signal. Das ist der Ansatz, den GitHub mit Copilot in großem Maßstab verfolgt, aber er erfordert ML-Infrastruktur, die die meisten SaaS-Teams vor Maturity-Stufe 4 nicht aufbauen sollten.
Der kumulative Datenvorteil
Nach 12 Monaten mit einem echten Telemetrie-Loop ändert sich etwas an Ihrer Wettbewerbsposition.
Ihre KI-Features wurden auf dem tatsächlichen Verhalten Ihrer tatsächlichen Nutzer bei Ihren tatsächlichen Anwendungsfällen trainiert. Nicht auf generischem Internet-Text. Nicht auf Benchmark-Datensätzen. Die Muster Ihrer Nutzer, die Präferenzen Ihrer Nutzer, die Definitionen Ihrer Nutzer von „guter Vorschlag".
Ein Wettbewerber, der dasselbe Feature mit demselben zugrunde liegenden Modell startet, beginnt bei null. Er hat denselben API-Zugang, den Sie beim Launch hatten. Aber er hat nicht Ihre 12 Monate an Nutzerverhaltensdaten. Er kann sie nicht kaufen. Er muss sie verdienen, indem er seine eigene Schleife 12 Monate lang betreibt.
So werden Telemetrie-Loops zu einem dauerhaften Wettbewerbsvorteil. Nicht durch die Technologie, die allen zugänglich ist, sondern durch die akkumulierten Verhaltensdaten, die beeinflussen, wie die Technologie für Ihre spezifischen Nutzer performt.
Der kumulative Effekt beschleunigt sich bei Maturity-Stufen 4 und 5, wo KI-Features beginnen, Signale über Funktionen hinweg zu teilen. Wenn die Outcome-Daten Ihrer In-Produkt-KI das Health-Scoring Ihrer Customer-Success-KI speisen, und die Genauigkeit Ihrer Health-Scoring-KI zurück in die Features fließt, die Ihre In-Produkt-KI priorisiert, bauen Sie ein integriertes Lernsystem auf. McKinsey beschreibt diese Kumulations-Dynamik explizit: schnellere Experimente generieren mehr Daten, mehr Daten verbessern die Modellqualität, bessere Performance zieht mehr Nutzer an, und mit der Zeit wird die Lücke zwischen Organisationen, die diese Schleifen betreiben, und denen, die es nicht tun, strukturell. SaaS AI maturity stages zeigt, wie diese funktionsübergreifende Integration auf jeder Stufe aussieht.
Datenschutz- und Einwilligungsanforderungen
Nutzer-Feedback, das für das Modelltraining gesammelt und verwendet wird, ist aus Compliance-Perspektive nicht kostenlos. DSGVO (Datenschutz-Grundverordnung) Artikel 22 und CCPA (California Consumer Privacy Act) haben beide Anforderungen an automatisierte Entscheidungsfindung und Datennutzung. Die Verwendung von Verhaltensdaten zur Verbesserung von KI-Features, die dann Vorschläge an Nutzer machen, fällt in einigen Interpretationen unter automatisierte Entscheidungsfindung.
Die praktische Anforderung für die meisten SaaS-Unternehmen lautet: Ihre Nutzungsbedingungen und Datenschutzrichtlinie müssen explizit angeben, dass Sie Produktnutzungsdaten sammeln, um KI-Features zu verbessern, und Nutzer benötigen einen klaren Opt-out-Pfad. NISTs AI Risk Management Framework bietet eine nützliche Struktur für die Dokumentation, wie Verhaltens-Feedback-Daten durch KI-Verbesserungs-Pipelines fließen, was zunehmend wichtig wird, da Enterprise-Procurement-Teams ihre eigenen KI-Governance-Reviews durchführen, bevor sie SaaS-Tools genehmigen.
Die wichtigere Regel: Verwenden Sie keine kundespezifischen Daten, um KI für andere Kunden zu verbessern, ohne ausdrückliche Zustimmung. Aggregierte Verhaltensmuster sind generell in Ordnung. Spezifische nutzergenerierte Inhalte, die als Trainingsbeispiele verwendet werden, erfordern eine stärkere Einwilligungsarchitektur.
Das Anti-Muster: KI-Features, die nie lernen
Das Gegenteil eines Telemetrie-Loops ist ein KI-Feature, das ab dem ersten Tag statisch ist. Gleiches Modell, gleiche Prompts, gleiche Vorschläge, unabhängig davon, was Nutzer damit machen. Diese Features gibt es in vielen SaaS-Produkten derzeit. Sie wurden von Teams gebaut, die KI als Checkbox behandelten: „shippen, es ist KI."
Die Zeichen eines statischen KI-Features:
- Vorschlag-Qualität verbessert sich nicht über 6-Monats-Intervalle
- Das Team hat kein wöchentliches Review der KI-Feature-Metriken
- Das Data-Team hat kein Dashboard, das Akzeptanzrate oder Modifikationsrate verfolgt
- Prompt-Änderungen erfordern einen Sprint-Zyklus und geschehen vierteljährlich bestenfalls
Statische KI-Features sind nicht neutral. Sie sind eine Kostenstelle ohne kumulativen Mehrwert. Jeden Monat, in dem sie sich nicht verbessern, wird die Lücke zwischen Ihrer KI-Qualität und einem Wettbewerber, der eine Schleife betreibt, größer.
Die Entscheidung, die Schleife zu bauen, ist die KI-Infrastruktur-Entscheidung. Die Modellwahl ist weniger wichtig.
Wie „Schleife geschlossen" in der Praxis aussieht
Eine geschlossene Telemetrie-Schleife erzeugt ein wöchentliches Ritual: das KI-Feature-Metriken-Review. Akzeptanzrate hoch oder runter. Modifikationsrate nach Vorschlagstyp. Eventuell bewegende Ergebnis-Korrelationen. Angepasste Prompts basierend auf Signal. Neue Version geshippt.
GitHub Copilots Engineering-Team veröffentlicht regelmäßig Beiträge darüber, wie sie Akzeptanzdaten und Edit-Distance-Metriken nutzen, um Modelländerungen zu evaluieren. Linears Changelog zeigt KI-Prioritäts-Scoring-Verbesserungen in den meisten monatlichen Releases, getrieben durch die tatsächliche Reaktion der Ingenieure auf Vorschläge. Das sind keine Zufälle. Das sind Schleifen.
Für Ihr Team ist der Minimum Viable Telemetry Loop:
suggestion_shown,suggestion_accepted,suggestion_modifiedEvents in Segment oder Amplitude- Ein wöchentliches Dashboard mit Akzeptanzrate und Modifikationsrate nach Feature
- Ein Prompt-Review-Meeting alle zwei Wochen, bei dem jemand die Daten tatsächlich liest
- Eine Verpflichtung zu Prompt-Änderungen, die die schwächsten Vorschlagstypen verbessern
Das ist es. Das ist die Schleife. Es ist kein ML Engineering. Es ist Produktdisziplin.
Die Unternehmen, die 2027 und 2028 KI-Feature-Qualität besitzen werden, sind nicht die, die 2025 das beste Modell gewählt haben. Es sind die, die 2025 die Schleife gebaut und laufen gelassen haben.
Mehr erfahren:
- Was ist Ingest AI Capability: die ACE Ingest-Schicht, auf der Telemetrie-Loops aufgebaut werden
- How AI Patterns Combine Capabilities: wie Telemetrie-Daten über mehrere KI-Muster hinweg kumulieren
- KI-Features als Produkt: Wo man sie hinzufügt: wie man die Features identifiziert, für die es sich lohnt, eine Telemetrie-Schleife zu bauen
- KI-Copilots in der SaaS-Produkt-UI: die eingebetteten KI-Features, die die reichhaltigsten Telemetrie-Signale generieren
- SaaS AI Maturity Stages: wie funktionsübergreifende Telemetrie-Integration über Maturity-Stufen hinweg entwickelt wird
- The Product Telemetry Advantage in SaaS AI: wie SaaS-Telemetrie einen strukturellen Vorteil gegenüber reinen KI-Wettbewerbern schafft

Co-Founder, Rework.com
On this page
- Der Closed-Loop AI Improvement Cycle
- Was ein Telemetrie-Loop eigentlich ist
- Die drei Signal-Typen aus In-Produkt-KI
- Warum implizites Feedback explizites übertrifft
- Vergleich von Signal-Qualität und -Volumen
- Schema-Design für KI-Telemetrie
- Die Schleife für die Modellverbesserung nutzen
- Der kumulative Datenvorteil
- Datenschutz- und Einwilligungsanforderungen
- Das Anti-Muster: KI-Features, die nie lernen
- Wie „Schleife geschlossen" in der Praxis aussieht