Telemetry Loop cho In-Product AI: Xây Dựng Feedback Tích Lũy
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GitHub Copilot ngày càng tốt hơn đáng kể sau mỗi vài tháng. Sự cải tiến đó không đến từ GitHub engineer làm việc chăm chỉ hơn trên mô hình. Nó đến từ hàng triệu developer chấp nhận, sửa đổi và từ chối Copilot suggestion mỗi ngày. Mỗi tương tác là một data point. Mỗi data point feed vào model version tiếp theo. Sản phẩm cải thiện vì mọi người dùng nó.
Đây là telemetry loop: hệ thống có cấu trúc capture những gì AI feature gợi ý, người dùng làm gì tiếp theo, và outcome theo sau là gì. Đó là sự khác biệt giữa AI feature đạt đỉnh tại launch quality và AI feature tích lũy.
Hầu hết SaaS team build AI feature bỏ qua điều này. Họ ship feature. Họ xem adoption number. Họ tuyên bố thành công nếu adoption tăng. Rồi sáu tháng sau, họ tự hỏi tại sao AI suggestion của họ vẫn cảm giác generic và tại sao churn trong AI feature user không tốt hơn non-user.
Loop mới là điểm mấu chốt. Initial model chỉ là starting condition.
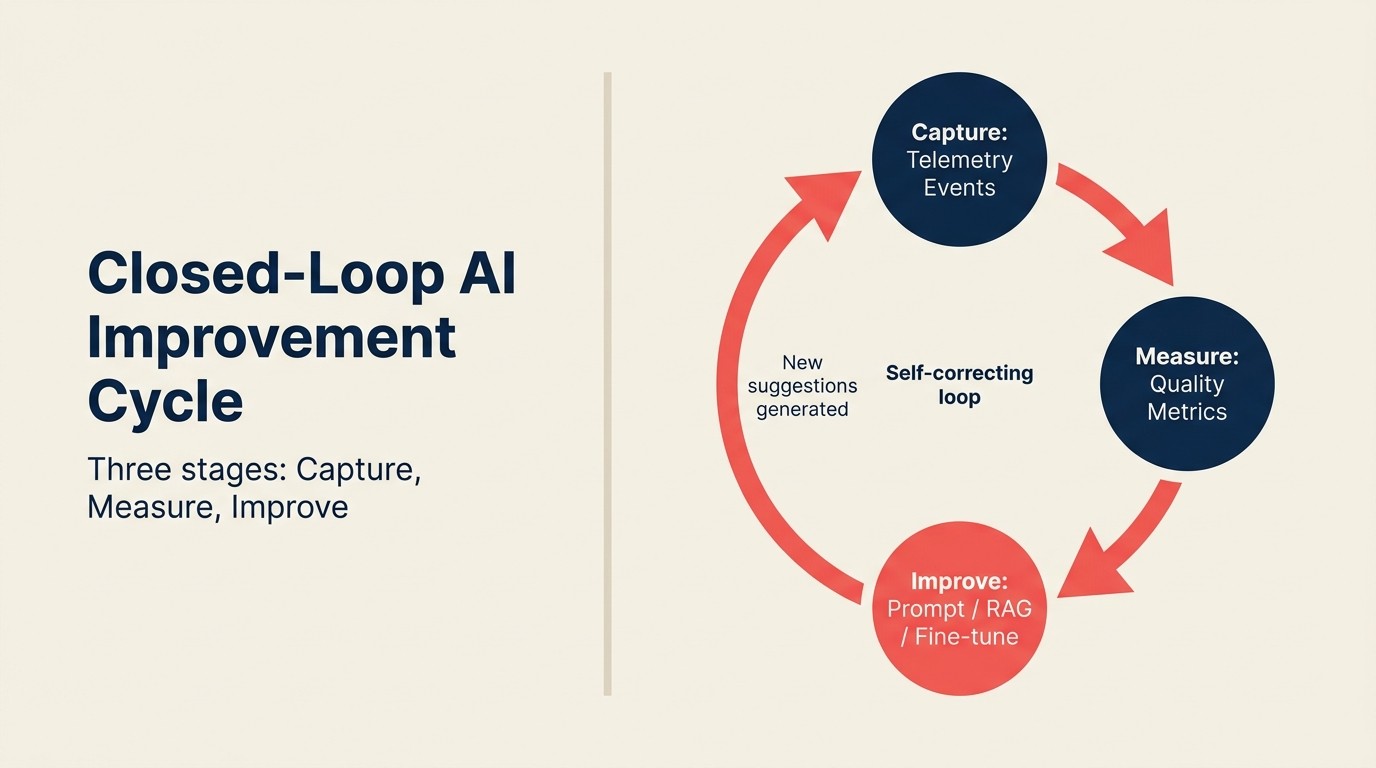
Chu Kỳ Cải Tiến AI Vòng Kín
Closed-Loop AI Improvement Cycle là three-stage feedback system chuyển đổi in-product AI usage thành continuous model improvement. Capture: structured telemetry event ghi lại AI gợi ý gì, người dùng làm gì tiếp theo, và downstream outcome. Measure: aggregate signal tính quality metric theo suggestion type (acceptance rate, modification rate, outcome correlation). Improve: quality metric route đến improvement mechanism phù hợp (prompt engineering cho API-based feature, retrieval parameter adjustment cho RAG feature, hoặc fine-tuning data cho custom model). Chu kỳ đóng khi improvement tạo ra suggestion mới sinh capture event mới. Loop dừng ở Capture (ghi event không measure hoặc improve) không phải loop. Đó là archive.
Telemetry loop thực sự là gì
Telemetry loop có ba giai đoạn, ánh xạ đến ACE Framework Ingest capability:
Capture: Thu thập structured signal từ mỗi AI feature interaction. AI gợi ý gì, hiển thị gì, context là gì. Ánh xạ trực tiếp đến ACE Framework Ingest capability.
Measure: Aggregate các signal đó thành quality metric. Suggestion acceptance rate, modification rate, outcome correlation.
Improve: Route các measured signal về model improvement, prompt refinement, hoặc retrieval parameter adjustment.
Không có cả ba giai đoạn, bạn không có loop. Hầu hết team có giai đoạn đầu (họ log event ở đâu đó), skip giai đoạn thứ hai (họ không có quality metric), và không bao giờ đạt giai đoạn thứ ba (data ngồi trong data warehouse và không ai act theo nó).
Loop thực sự đóng lại. Output của Improve feed trở lại vào AI feature behavior, sinh Capture data mới. Hệ thống tự hiệu chỉnh theo thời gian.
Key Facts: Telemetry Loop và AI Improvement
- Behavioral signal experiment của LinkedIn cho thấy behavioral signal dự đoán content quality tốt hơn 4-6x so với explicit rating, đó là lý do implicit feedback (accept/modify/reject) là high-value signal trong AI telemetry loop
- GitHub Copilot viết gần một nửa code của developer, và controlled test cho thấy developer hoàn thành task nhanh hơn 55%; quality này đạt mức hiện tại thông qua hàng triệu acceptance và rejection signal từ 15M+ user, không phải qua static model improvement (Second Talent, 2025)
- McKinsey mô tả compounding dynamic rõ ràng: faster experimentation sinh nhiều data hơn, nhiều data cải thiện model quality, better performance thu hút nhiều user hơn, và gap giữa organization chạy loop này và không chạy trở thành structural theo thời gian (McKinsey State of AI, 2025)
Ba loại tín hiệu từ in-product AI

Không phải tất cả feedback đều bình đẳng. Ba loại khác nhau rất nhiều về volume, accuracy và độ khó thu thập.
Explicit feedback là dễ hiểu nhất và ít hữu ích nhất trong thực tế. Thumbs-up, thumbs-down, prompt "điều này có hữu ích không?". Người dùng đưa explicit feedback hiếm và không nhất quán. Ai đó click thumbs-down một lần và không bao giờ click lại chưa ngừng có ý kiến. Họ đã ngừng click. LinkedIn chạy experiment về explicit feedback mechanism và thấy behavioral signal dự đoán content quality tốt hơn 4-6x so với explicit rating. Cùng pattern xuất hiện trong product context.
Implicit feedback là nơi signal tồn tại. Người dùng không click thumbs-down, nhưng họ hành xử trung thực. Họ accept suggestion, edit suggestion, ignore suggestion, hoặc undo kết quả và làm task thủ công. Các hành động này cho bạn biết nhiều hơn về quality so với bất kỳ rating system nào.
Hai implicit metric quan trọng nhất:
- Suggestion acceptance rate: Bao nhiêu phần trăm AI suggestion người dùng dùng không sửa đổi?
- Modification rate: Trong số suggestion người dùng accept, bao nhiêu người edit trước khi finalize?
Modification rate cao cho bạn biết hướng AI đúng nhưng specifics sai. Acceptance rate thấp với manual-completion rate cao cho bạn biết suggestion insertion point sai hoặc quality threshold quá thấp. Đây là các vấn đề khác nhau với fix khác nhau.
Outcome feedback là loại khó collect nhất và có giá trị nhất. AI-assisted task có tạo ra kết quả tốt hơn manual equivalent không? Email do AI draft có nhận reply không? AI-generated support response có resolve ticket không cần escalation không? AI-suggested next action trong CRM có dẫn đến meeting được book không?
Outcome feedback đòi hỏi kết nối AI telemetry của bạn với downstream business outcome, thường có nghĩa là join event data với CRM hoặc support ticket data. Đó là engineering investment. Nhưng khi bạn có nó, bạn trả lời được câu hỏi mà mọi product leader thực sự quan tâm: AI của chúng ta có làm khách hàng thành công hơn không, hay nó chỉ generate activity?
Tại sao implicit feedback vượt trội explicit
Behavioral economics ở đây nhất quán trên các sản phẩm. Mọi người không self-report chính xác về preference. Họ nói họ muốn một thứ và làm thứ khác. Điều này đúng cho AI feature feedback theo cách chính xác như với survey response về product feature.
Thực tế hơn: ratio của implicit feedback so với explicit feedback trong hầu hết product là khoảng 50-to-1 hoặc cao hơn. Với mỗi user click thumbs-down, năm mươi user đã tạo behavioral signal chất lượng tương đương hoặc cao hơn. Optimize chỉ cho explicit feedback nghĩa là bỏ qua 98% signal bạn có thể dùng.
Notion AI học điều này sớm. AI writing suggestion của họ được refined dựa trên cách người dùng accept, modify hoặc replace suggested text, không chủ yếu dựa trên explicit rating. Product engineer có thể thấy ở dạng aggregate loại suggestion nào được dùng nguyên trạng so với rewrite so với ignore. Aggregate view đó định hình prompt engineering và model selection decision cho version tiếp theo.
Cùng pattern thấy được trong Linear AI feature development. Bug triage và priority suggestion của họ được refined thông qua combination của AI-suggested priority nào engineer override, và tần suất manually overridden priority hóa ra khớp với actual resolution urgency. Model không chỉ train trên labeled data. Nó train trên khoảng cách giữa những gì nó gợi ý và những gì thực sự xảy ra.
"Ratio của implicit feedback so với explicit feedback trong hầu hết product là 50-to-1 hoặc cao hơn. Với mỗi user click thumbs-down, năm mươi user đã tạo behavioral signal chất lượng tương đương hoặc cao hơn. Optimize chỉ cho explicit feedback nghĩa là bỏ qua 98% signal có sẵn." (Rework Analysis, dựa trên LinkedIn behavioral economics research)
"Static AI feature không trung lập. Chúng là chi phí không có compounding value. Mỗi tháng feature không improve qua telemetry, gap giữa quality của nó và competitor đang chạy loop thực sự ngày càng rộng hơn. Quyết định build loop là AI infrastructure decision. Model choice ít quan trọng hơn." (Rework Analysis, 2025)
So Sánh Chất Lượng và Khối Lượng Signal
| Loại Signal | Độ Khó Thu Thập | Volume | Chất Lượng/Accuracy | Sử Dụng Chính |
|---|---|---|---|---|
| Explicit (thumbs up/down) | Dễ | Rất thấp (2-3% interaction) | Kém (self-reporting không nhất quán) | Edge-case flagging hiếm gặp |
| Implicit acceptance | Trung bình | Cao (mỗi suggestion được hiển thị) | Tốt (honest behavioral signal) | Acceptance rate, model improvement |
| Implicit modification | Trung bình | Cao (mỗi suggestion được accept) | Rất tốt (cho thấy preference gap) | Prompt engineering, specificity tuning |
| Outcome feedback | Khó (đòi hỏi data join) | Thấp (subset của session) | Xuất sắc (đo actual value) | ROI measurement, training signal |
Nguồn: LinkedIn AI behavioral signal research, Notion AI telemetry documentation, McKinsey AI Software Development research 2025
Phân Tích Rework: Hầu hết SaaS team có Stage 1 của telemetry loop (log event) và skip Stage 2 và 3 (measure quality metric và act theo chúng). Data ngồi trong warehouse và không ai review hàng tuần. Minimum viable loop là bốn thành phần: event suggestion_shown, suggestion_accepted và suggestion_modified trong Segment hoặc Amplitude; weekly acceptance rate dashboard theo feature; biweekly prompt review meeting nơi ai đó đọc data; và commitment ship prompt change cho weakest-performing suggestion type. Đó là toàn bộ loop.
Schema design cho AI telemetry

Event schema quan trọng. Vague event tạo vague signal. Nếu telemetry của bạn trông như ai_feature_used: true, bạn không tính được modification rate, không segment được theo suggestion type, và không correlate được với outcome.
Minimal AI telemetry schema trông như thế này:
suggestion_id: UUID (link suggestion qua lifecycle của nó)
feature_id: string (AI feature nào generate ra cái này)
session_id: string (kết nối với user session context)
context_hash: string (fingerprint của context AI nhận)
suggestion_type: enum (draft, autocomplete, classification, recommendation)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp hoặc null
suggestion_modified: boolean
modification_delta: integer (character edit distance từ suggestion đến final)
user_dismissed: boolean
manual_completion: boolean (user hoàn thành task không dùng suggestion)
outcome_event_id: string hoặc null (FK đến downstream outcome, nếu capture được)
Schema này cho phép tính mọi metric quan trọng cho telemetry loop quality. context_hash đặc biệt quan trọng: nó cho phép xác định liệu similar context có nhận suggestion ngày càng tốt hơn hay tệ hơn theo thời gian, đây là core measurement cho model improvement.
Với team dùng Segment hoặc Amplitude làm event pipeline, schema này map gọn vào custom event với standard property. outcome_event_id join đòi hỏi server-side enrichment step hoặc downstream join trong data warehouse. Khi bạn có schema capture đúng event, những gì bạn làm với signal đó phụ thuộc hoàn toàn vào cách AI feature của bạn được build.
Dùng loop để cải tiến mô hình
Những gì bạn làm với telemetry data phụ thuộc vào cách AI feature được build.
Với GPT-4 hoặc Claude API-based feature (trường hợp phổ biến nhất cho SaaS AI năm 2026), improvement mechanism là prompt engineering. Modification rate cao trên một suggestion type cụ thể cho bạn biết prompt không đủ specific. Consistent manual completion sau AI suggestion cho bạn biết suggestion xuất hiện sai thời điểm trong workflow. Bạn iterate trên prompt hàng tuần mà không cần động vào underlying model.
Với RAG (Retrieval-Augmented Generation) feature (AI retrieve từ knowledge base trước khi generate), telemetry feed retrieval parameter adjustment. Nếu người dùng liên tục ignore AI suggestion trích dẫn một knowledge base section cụ thể, section đó đã lỗi thời hoặc không liên quan. Telemetry cho bạn biết retrieval source nào thực sự tạo ra suggestion được dùng so với noise. AI knowledge base maintenance cho SaaS bao gồm cách act theo signal này để giữ retrieval corpus hiện tại.
Với fine-tuned hoặc custom model (hiếm cho Series A-C SaaS), high-quality implicit feedback với outcome label trở thành training data. Modification rate data thực chất là preference dataset. Outcome correlation data là reinforcement signal. Đây là cách GitHub dùng với Copilot ở scale, nhưng nó đòi hỏi ML infrastructure mà hầu hết SaaS team không nên build trước Stage 4 maturity.
Data moat tích lũy
Sau 12 tháng chạy telemetry loop thực sự, điều gì đó thay đổi về competitive position của bạn.
AI feature của bạn train trên actual behavior của actual user của bạn làm actual use case của bạn. Không phải generic internet text. Không phải benchmark dataset. Pattern của user bạn, preference của user bạn, định nghĩa của user bạn về "good suggestion."
Competitor launch cùng feature với cùng underlying model bắt đầu từ zero. Họ có cùng API access bạn có khi launch. Nhưng họ không có 12 tháng behavioral data của user bạn. Họ không thể mua nó. Họ phải kiếm nó bằng cách chạy loop riêng của họ 12 tháng.
Đây là cách telemetry loop trở thành durable competitive advantage. Không phải từ technology, thứ available cho tất cả mọi người, mà từ accumulated behavioral data định hình cách technology perform cho specific user của bạn.
Compounding effect tăng tốc ở Stage 4 và 5 maturity, nơi AI feature bắt đầu chia sẻ signal trên các function. Nếu outcome data của in-product AI feed CS AI health scoring, và accuracy của health scoring AI feed trở lại vào feature mà in-product AI prioritize, bạn đang build integrated learning system. Thứ đó thực sự khó sao chép. McKinsey mô tả compounding dynamic này rõ ràng: faster experimentation sinh nhiều data hơn, nhiều data cải thiện model quality, better performance thu hút nhiều user hơn, và theo thời gian gap giữa organization chạy loop này và không chạy trở thành structural. Các giai đoạn trưởng thành AI trong SaaS map out cross-function integration này trông như thế nào ở mỗi stage.
Yêu cầu về privacy và consent
User feedback được collect và dùng để train model không miễn phí từ góc độ compliance. GDPR (General Data Protection Regulation) Article 22 và CCPA (California Consumer Privacy Act) đều có yêu cầu về automated decision-making và data use. Dùng behavioral data để improve AI feature sau đó đưa suggestion cho user có thể thuộc automated decision-making trong một số interpretation.
Yêu cầu thực tế cho hầu hết SaaS company: terms of service và privacy policy của bạn cần nêu rõ ràng rằng bạn collect product usage data để improve AI feature, và user cần clear opt-out path. NIST AI Risk Management Framework cung cấp cấu trúc hữu ích để document cách behavioral feedback data chạy qua AI improvement pipeline, thứ ngày càng quan trọng khi enterprise procurement team chạy AI governance review riêng trước khi approve SaaS tool. Điều này khác với AI training trên user content, yêu cầu consent architecture chặt chẽ hơn.
UX friction concern là thực nhưng có thể giải quyết. Notion, Linear và hầu hết major SaaS AI product xử lý điều này thông qua privacy settings section giải thích những gì được collect, dùng để làm gì, và cách opt-out. Hầu hết user không opt-out. Nhưng có mechanism quan trọng cho compliance và trust.
Quy tắc quan trọng hơn: đừng dùng customer-specific data để improve AI cho customer khác mà không có explicit consent. Aggregate behavioral pattern thường ổn. Specific user-generated content làm training example đòi hỏi stronger consent architecture.
Anti-pattern: AI feature không bao giờ học
Ngược lại với telemetry loop là AI feature tĩnh từ ngày đầu. Cùng model, cùng prompt, cùng suggestion, bất kể user làm gì. Những feature này tồn tại trong nhiều SaaS product hiện nay. Chúng được build bởi team coi AI như checkbox: "ship nó, đó là AI."
Dấu hiệu của static AI feature:
- Suggestion quality không cải thiện trong khoảng 6 tháng
- Team không có weekly review về AI feature metric
- Data team không có dashboard track acceptance rate hoặc modification rate
- Prompt change đòi hỏi sprint cycle và xảy ra quarterly tốt nhất
Static AI feature không trung lập. Chúng là chi phí không có compounding value. Mỗi tháng chúng không improve, gap giữa AI quality của bạn và competitor đang chạy loop ngày càng rộng.
Quyết định build loop là AI infrastructure decision. Model choice ít quan trọng hơn.
"Loop đã đóng" trông như thế nào trong thực tế
Closed telemetry loop tạo ra weekly ritual: AI feature metrics review. Acceptance rate tăng hay giảm. Modification rate theo suggestion type. Outcome correlation nào đang di chuyển. Prompt được điều chỉnh dựa trên signal. Version mới được ship.
GitHub Copilot engineering team publish bài định kỳ về cách họ dùng acceptance data và edit distance metric để evaluate model change. Linear changelog cho thấy AI priority scoring improvement trong hầu hết monthly release, được thúc đẩy bởi cách engineer thực sự respond với suggestion. Những điều này không phải ngẫu nhiên. Chúng là loop.
Với team của bạn, minimum viable telemetry loop là:
- Event
suggestion_shown,suggestion_accepted,suggestion_modifiedtrong Segment hoặc Amplitude - Weekly dashboard với acceptance rate và modification rate theo feature
- Biweekly prompt review meeting nơi ai đó thực sự đọc data
- Cam kết prompt change cải thiện weakest-performing suggestion type
Đó là tất cả. Đó là loop. Không cần ML engineering. Đó là product discipline.
Company sẽ own AI feature quality năm 2027 và 2028 không phải là company chọn best model năm 2025. Họ là company build loop năm 2025 và để nó chạy.
Câu Hỏi Thường Gặp
Telemetry loop cho in-product AI là gì?
Telemetry loop là structured system capture những gì AI feature gợi ý, user làm gì tiếp theo, và outcome theo sau, sau đó route các signal đó về model hoặc prompt improvement. Ba giai đoạn là Capture (structured event collection), Measure (quality metric từ aggregated signal), và Improve (prompt engineering, retrieval adjustment, hoặc training data). Không có cả ba giai đoạn, bạn có archive, không phải loop.
Tại sao implicit feedback có giá trị hơn explicit rating trong AI telemetry?
Explicit rating (thumbs up/down) được đưa ra bởi 2-3% user và không phản ánh chính xác preference. User không self-report nhất quán. Implicit signal (accept, modify hoặc ignore suggestion) được tạo ra bởi 100% interaction và phản ánh honest behavior. Ratio là khoảng 50-to-1. Optimize chỉ cho explicit feedback bỏ qua 98% signal có sẵn.
Hai key implicit metric trong AI telemetry là gì?
Suggestion acceptance rate (bao nhiêu phần trăm AI suggestion user dùng không sửa đổi?) và modification rate (trong số suggestion user accept, bao nhiêu người edit trước khi finalize?). Modification rate cao nghĩa là hướng AI đúng nhưng specifics sai. Acceptance rate thấp với manual completion cao nghĩa là trigger point hoặc quality threshold sai. Metric khác nhau, fix khác nhau.
Telemetry loop tạo competitive moat như thế nào?
Sau 12 tháng chạy telemetry loop thực sự, AI feature của bạn train trên actual behavior của actual user của bạn làm actual use case. Competitor launch cùng feature với cùng underlying model bắt đầu từ zero. Họ có cùng API access bạn có khi launch nhưng không có 12 tháng behavioral data của user bạn. Họ không thể mua nó. Họ phải kiếm nó bằng cách chạy loop riêng 12 tháng.
Minimum viable telemetry loop là gì?
Bốn thành phần: event suggestion_shown, suggestion_accepted và suggestion_modified track trong Segment hoặc Amplitude; weekly dashboard với acceptance rate và modification rate theo feature; biweekly prompt review meeting nơi ai đó đọc data; và cam kết ship prompt change cho weakest-performing suggestion type. Không cần ML engineering ở giai đoạn này. Pure product discipline.
Compliance requirement nào áp dụng cho behavioral telemetry để train AI?
GDPR Article 22 và CCPA đều có yêu cầu về automated decision-making và data use. Terms of service và privacy policy phải nêu rõ ràng rằng bạn collect product usage data để improve AI feature, với clear opt-out path. Đừng dùng customer-specific content để improve AI cho customer khác mà không có explicit consent. Aggregate behavioral pattern (acceptance rate, modification rate) thường ổn. Specific user-generated content làm training example đòi hỏi stronger consent architecture.
Tìm Hiểu Thêm:
- Khả Năng AI Ingest là Gì: ACE Ingest layer mà telemetry loop build trên
- Cách AI Pattern Kết Hợp Khả Năng: cách telemetry data compound trên nhiều AI pattern
- AI Feature như Sản Phẩm: Nơi Thêm Chúng: cách xác định feature đáng build telemetry loop xung quanh
- AI Copilot Nhúng trong SaaS Product UI: embedded AI feature tạo ra telemetry signal phong phú nhất
- Các Giai Đoạn Trưởng Thành AI trong SaaS: cách cross-function telemetry integration phát triển qua maturity stage
- Lợi Thế Product Telemetry trong SaaS AI: cách SaaS telemetry tạo structural moat so với pure-AI competitor

Co-Founder, Rework.com
On this page
- Chu Kỳ Cải Tiến AI Vòng Kín
- Telemetry loop thực sự là gì
- Ba loại tín hiệu từ in-product AI
- Tại sao implicit feedback vượt trội explicit
- So Sánh Chất Lượng và Khối Lượng Signal
- Schema design cho AI telemetry
- Dùng loop để cải tiến mô hình
- Data moat tích lũy
- Yêu cầu về privacy và consent
- Anti-pattern: AI feature không bao giờ học
- "Loop đã đóng" trông như thế nào trong thực tế