AI Sales Opsのガバナンスと監査証跡

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ACE FrameworkはGenerateとExecuteの間に明確な境界線を引いています。GenerateとExecuteの境界の記事では、この区別が安全なAI展開の基盤となぜ重要かを説明しています。Generateはレビュー待ちの下書きを生成します。Executeは世界の状態を変えます。メールを送信し、CRMレコードを更新し、リードをルーティングします。この境界が重要なのは、Executeにはきれいに元に戻せない結果があるからです。
AI Sales Opsでは、Executeのアクションが毎日人間の目を経ずに何十回も発生します。リードルーティングの割り当て、CRMフィールドの自動更新、どのリードが優先されるかを決めるスコアリング決定、コールトランスクリプトによってトリガーされた自動フォローアップシーケンス。ほとんどの場合、これらの決定は正しいです。そうでない場合、企業は何が起きたか、なぜ起きたか、誰がアカウンタビリティを持っていたかを知る必要があります。
AI Sales Opsにおけるガバナンスは官僚主義ではありません。これが組織がAIを十分に信頼して時間とともにより多くの自律性を与える理由です。なぜリードが特定の担当者にルーティングされたかを説明できないチームは、最終的にそのルーティングが報酬の問題、バイアス監査、またはコンプライアンスレビューで問われることになります。意思決定ログ、モデルバージョン、入力データの状態を示せるチームには立脚する根拠があります。
4パターンスタックでガバナンスが必要なもの
Key Facts: 2026年のAIガバナンスリスクとコンプライアンス
- GDPR罰金は累計€71億を超え、2025年だけで€12億が課されました。AI採用が増えるにつれて執行が加速していることを反映し、総額の60%以上が2023年1月以降に課されています。(Kiteworks、2026年)
- 取締役会の54%がAIガバナンスに積極的に関与しておらず、個人データに影響を与えるAI Sales Ops展開に対する組織の重大なリスクを生み出しています。(Improvado、2025年)
- SOC 2 Type II認証は今や$50,000を超えるAIプラットフォーム契約の事実上の要件となっており、監査されていないAIツールが調達の遅延とコンプライアンスリスクを生み出しています。(MindStudio、2025年)
すべてのAIアクションが同じリスクを持つわけではありません。担当者が読んで破棄するメール下書きの提案生成は低リスクです。担当者のレビューなしに見込み客にフォローアップメールを自動送信することは高リスクです。ガバナンスモデルはこれらを区別する必要があります。
各パターンが生成するものでガバナンスが必要になり得るものを示します。
Scoring and Routing(Pattern 1):
- リードスコア:優先順位付けを決定する数値アウトプット(例:87/100)
- ルーティング割り当て:どの担当者またはチームがリードを受け取るか
- 優先度下げの決定:Nurtureにルーティングされるほど低スコアのリードと対応されるリードの判定
ルーティング決定は、チームがテリトリーベースまたはリードボリュームベースの報酬構造を使用している場合、担当者の報酬に直接影響します。スコアリングがスコアリング対象の個人の個人データを含む場合、GDPR第22条に関連する潜在的な影響もあります。パターン別ガバナンス要件の記事では、ScoringとRoutingだけでなく、全10パターンにわたってこれらの義務をマッピングしています。
Meeting Intelligence(Pattern 2):
- 録音同意のログ:同意はどのメカニズムで、いつ取得されたか?
- CRM自動書き込み:どのトランスクリプトデータがどのフィールドに自動的に書き込まれたか?
- コーチングデータアクセス:どのマネージャーがどの担当者のコール録音にアクセスしたか?
同意なしの録音は複数の管轄地域で法律違反です。同意ログはただの運用記録ではなく、コンプライアンスの証拠物件です。
Generative Research(Pattern 3):
- リサーチブリーフのソース帰属:ブリーフを生成するのにどのデータソースが使われたか?
- データライセンスコンプライアンス:ソースプロバイダーの利用規約は遵守されたか?
リサーチブリーフは通常、自動化されたものをトリガーするのではなく人間の決定に情報を提供するため、Executeアクションのリスクは低いです。ガバナンス要件は軽めですが、ブリーフが営業判断に影響する誤情報を含む場合はソース帰属が重要です。
Workflow Copilot(Pattern 4):
- 担当者に表示されたNBAの提案:何が提案されたか、実行されたか?
- 自動下書きメール:プロンプトの入力は何か、何が生成されたか、担当者が何を変更したか、何が送信されたか?
- CRM衛生の自動更新:どのフィールドが自動的に変更されたか、どの値からどの値に?
- Pipelineレビューデータ:リスクフラグはどのように生成されたか、何のデータ入力がトリガーしたか?
3つのガバナンスモデル
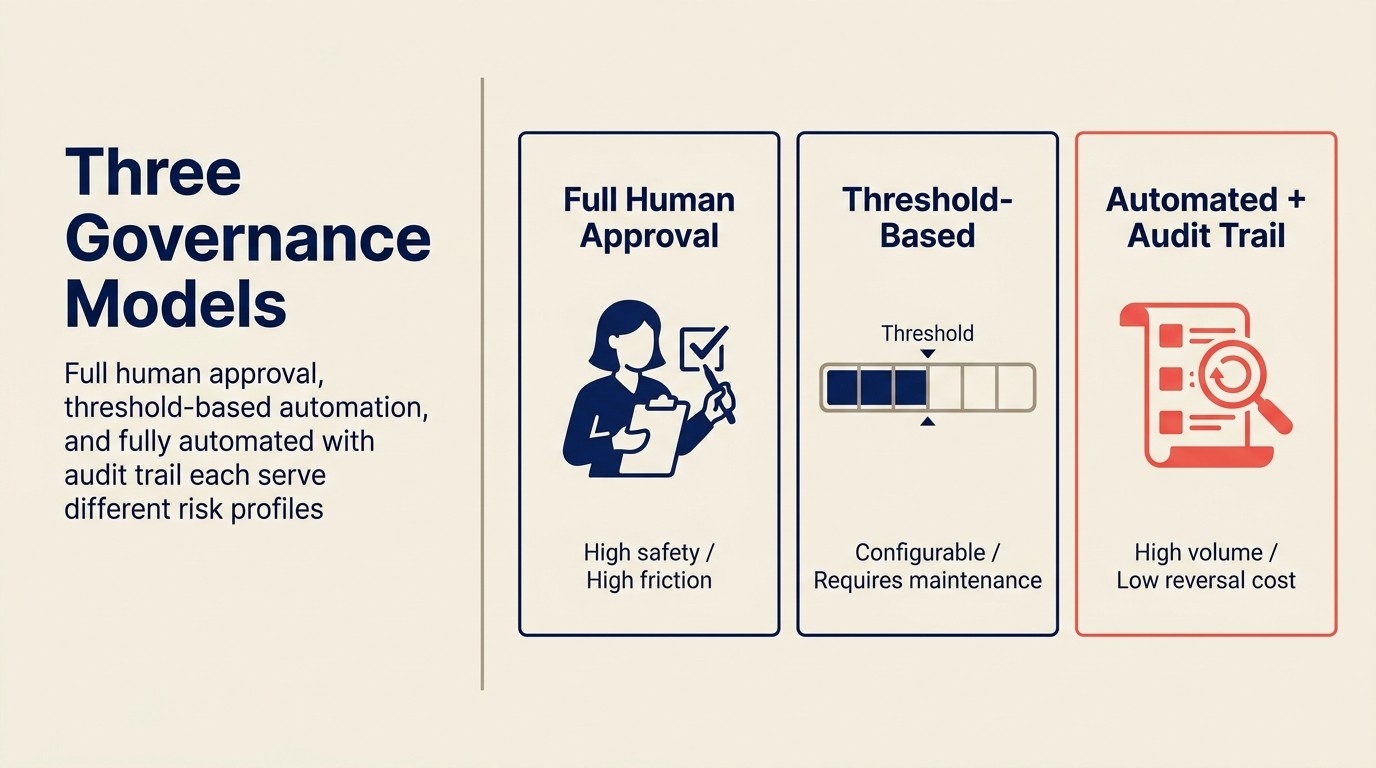
AIスタックの各Executeアクションについて、3つのガバナンスモデルのいずれかを選択する必要があります。
完全な人間の承認
すべてのAI生成アクションは実行前に明示的な人間の承認が必要です。
いつ使うか: 高リスクのアクション(エンタープライズ見込み客へのメール、報酬に影響するルーティング決定)、法的に敏感なコンテキスト、モデルへの信頼を構築している初期のAI展開段階。
トレードオフ: 高い安全性、高い摩擦。担当者がボトルネックになります。AIの時間節約が承認の負担で部分的に相殺されます。1日20通のメール下書きを生成するCopilotで完全承認を必須にすると、時間節約ツールが認知的負担になります。
実践的なセットアップ: CRMまたはメールツールの承認キュー。AIが生成し、人間がレビューし、クリックで送信/確定。生成されたアクションが陳腐化するまでキューに留まらないよう、承認に24時間のSLAを設定してください。
閾値ベースの自動化
信頼度閾値(またはリスク閾値)以下のアクションは自動実行されます。閾値を超えるアクションは人間の承認が必要です。
いつ使うか: ほとんどの成熟したAI Sales Opsスタック。閾値のキャリブレーションが重要な変数です。
例: リードルーティング。スコアが80以上かつ単一の明確なテリトリールールに一致:自動ルーティング。スコアが40〜80または共有テリトリールールが関与:Sales Opsレビューのためにキュー。スコアが40未満:Nurtureに自動ルーティング。これにより、明確な決定は自動化され、曖昧なものは人間の判断を得ます。
トレードオフ: 継続的な閾値メンテナンスが必要です。モデルの精度が向上するにつれて自動実行の閾値を上げられます。ビジネスが変化する(新しいテリトリー、新製品)と、閾値を見直す必要があります。誰かがこれを担当する必要があります。
実践的なセットアップ: AIプラットフォームでの閾値設定。承認キューのボリュームを示すモニタリングDashboard(キューが常に大きい場合は閾値が保守的すぎる。承認の質が低下している場合は閾値が積極的すぎる)。
監査証跡付きの完全自動化
アクションが自動的に実行されます。すべてがログに記録されます。人間のレビューは事後に、アクションごとの承認ではなく定期的な監査を通じて行われます。
いつ使うか: 高信頼度、大量、低逆転コストのアクション。トランスクリプトからのCRMフィールド入力。リードソースのタグ付け。「最終連絡日」のタイムスタンプ更新。間違いのコストが低く、手動レビューが価値より負担を生み出すアクション。
適切でない場合: 報酬に影響するアクション、規制対象の個人データ決定を含むアクション、顧客向けコミュニケーション。
実践的なセットアップ: Sales Ops Managerによる週次レビューを伴う包括的な監査ログ。異常パターンのアラートルール(例:1週間に自動ルーティングされたリードの5%以上が手動再割り当てされている場合、モデルがドリフトしているシグナル)。
GDPRのAIドリブン自動決定に対する執行が加速しています。ベルリンのある銀行は、自動化された信用申請却下の理由を申請者に透明に通知しなかったとして2023年に€300,000の罰金を受けました。スコアリングに基づいてリードを自動ルーティングしながら説明ドキュメントがないB2B Sales Opsチームは構造的に類似しています。
4パターン監査ログ標準
4パターン監査ログ標準は、4つのAI Sales OpsパターンそれぞれについてDeHの監査証跡に必要な最小フィールドセットを規定します。Scoring and Routing用:タイムスタンプ、アクションタイプ、リードID、モデルバージョン、値付きの入力特徴量、アウトプットスコア、割り当てられた担当者、検討された代替案、オーバーライドフラグ。Meeting Intelligence用:録音タイムスタンプ、同意方法とタイムスタンプ、書き込まれたCRMフィールド、変更前後の値、担当者アクセスログ。Generative Research用:ブリーフ生成タイムスタンプ、使用されたデータソース、ブリーフコンテンツのハッシュ、配信チャネル。Workflow Copilot用:提案タイプ、トリガー条件、入力状態、生成されたコンテンツ、担当者のアクション(受け入れ/却下/変更)、最終結果。これら4つの監査ログを持つ企業はどんなルーティング異議申し立て、コンプライアンス照会、またはモデル精度レビューにも、記憶から決定を再構築せずに対応できます。
監査証跡フィールド仕様
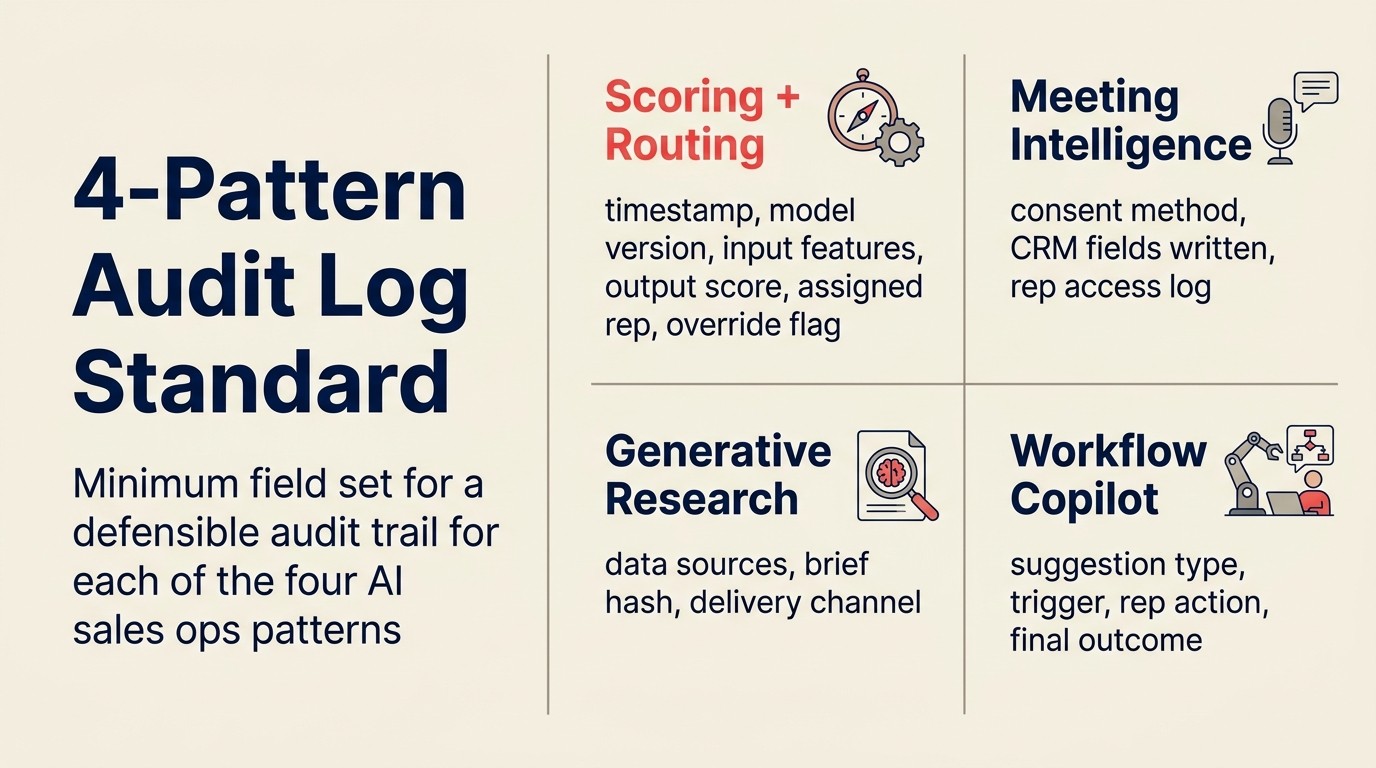
AI Sales Opsアクションの適切な監査証跡には以下のフィールドが含まれます。これは防御可能なガバナンスの最小要件です。エンタープライズコンプライアンスでは追加フィールドが必要な場合があります。
リードスコアリング決定の場合:
timestamp: 2026-05-19T09:23:14Z
action_type: lead_score
lead_id: CRM-1234567
model_id: scoring-model-v2.3
model_version_date: 2026-03-01
input_features: {
company_size: "50-200",
industry: "SaaS",
title: "VP of Operations",
intent_score: 72,
website_visits_30d: 4,
email_opens_30d: 3
}
output_score: 87
confidence: 0.91
action_taken: routed_to_rep_sarah_jones
alternatives_considered: [rep_alex_chen (score 0.87), rep_michael_kim (score 0.84)]
human_reviewer: null
override: false
自動下書きメールの場合:
timestamp: 2026-05-19T14:11:02Z
action_type: email_draft
deal_id: CRM-DEAL-98765
prompt_inputs: {
contact_name: "Jennifer Wu",
last_call_summary: "discussed budget approval timeline",
days_since_last_contact: 5,
deal_stage: "Proposal Sent"
}
generated_text: "[完全な下書きテキスト]"
rep_edits: "[担当者が送信前に変更した内容]"
final_sent_text: "[実際に送信されたテキスト]"
rep_id: REP-44
sent: true
sent_timestamp: 2026-05-19T14:38:22Z
ルーティング割り当ての場合:
timestamp: 2026-05-19T10:05:33Z
action_type: lead_route
lead_id: CRM-9876543
routing_rule_applied: "territory_rule_northeast_enterprise"
input_state: {
lead_location: "Boston, MA",
company_size: "500-1000",
lead_score: 87,
product_interest: ["Sales Ops", "Work Ops"]
}
assigned_to: REP-12 (Sarah Jones)
alternatives_evaluated: [REP-15, REP-22]
reason: "territory match + highest capacity score"
human_override: false
override_by: null
これらのレコードは専用のシステムに保存する必要はありません。ほとんどのCRMプラットフォームはカスタムログレコードを保存できます。Salesforceの専用監査テーブルまたはWebhook→ログサービスアーキテクチャは、ほとんどのミッドマーケットチームで機能します。
モデルバージョン管理と変更管理
スコアリングモデルを再トレーニングまたは更新する場合、監査証跡はどのモデルバージョンがどの決定を行ったかを追跡する必要があります。これはオプションではありません。
理由を説明します。2026年3月のスコアリングモデル(v2.1)が後にCompany Sizeに過学習し、インテントシグナルを軽視していたことが判明したとします。2026年5月に修正された特徴重みで再トレーニング(v2.3)します。担当者が2026年4月のリードルーティング決定を異議申し立てした場合、どのモデルがその決定を行ったか、特徴重みは何だったか、その時点で入手可能な情報を考えると決定は防御可能だったかを示せる必要があります。
監査ログにモデルバージョン管理がなければ、その質問に答えられません。変更されている可能性がある現在のモデルのロジックしか示せません。
モデルガバナンスの最小要件:
- すべてのモデル展開にバージョン識別子と展開日を付与
- すべてのスコアリング決定をそれを生成したモデルバージョンとともに記録
- バージョン間で何が変更されたかとその理由を文書化したモデル変更ログ
- ホールドアウト商談でのモデルバージョンパフォーマンスを比較する四半期精度レビュー
ルーティング異議申し立てプロセス
担当者がリードを誤って割り当てられた(または割り当てられなかった)と信じる場合、定義されたプロセスが必要です。なければ、異議申し立てが非公式で追跡されず、エスカレーションしやすくなります。
実用的な3ステップのルーティング異議申し立てプロセス:
ステップ1:担当者がルーティング異議申し立てを提出する。 CRMの構造化フォーム:リードID、ルーティング決定の日付、異議の理由(テリトリーの不一致、キャパシティの不均衡、選好ベースの主張)。選好ベースの主張(「あのリードが欲しかった」)は弱い異議です。テリトリーの不一致の主張(「Q1テリトリーマップによると、このリードは私のテリトリーにある」)は強い異議です。
ステップ2:Sales Ops Managerがレビューする。 48時間以内。監査ログをレビューします。どのルールがルーティングをトリガーしたか、どの入力が使われたか、ルールが正しく適用されたか。ルールが正しく適用され、テリトリーマップが正確であれば、異議申し立ては担当者に不利な形で解決されます。ルールの曖昧さまたはテリトリーマップの不一致がある場合、異議申し立ては認められることがあります。
ステップ3:決定を記録する。 認められるか却下されるかに関わらず、結果は元のルーティングイベントにリンクされた形で監査ログに入ります。認められた場合、モデル入力はレビューのためにフラグを立てます(これはモデルが異なる方法で処理すべきエッジケースか?)。有効なルールの異議で却下された場合(例:テリトリーマップが曖昧だった)、テリトリーマップが再発を防ぐために更新されます。
このプロセスは企業と担当者の両方を保護します。ルーティング決定に対するアカウンタビリティを作り、有効な異議申し立てのための正当なチャンネルを担当者に提供し、不正利用の余地を開かずに済みます。
AI Sales Opsにおけるデータプライバシー
3つのコンプライアンスフレームワークがほとんどのミッドマーケットB2B企業のAI Sales Opsに適用されます。展開前にどれが適用されるかを確認してください。
GDPR第22条(EU居住者): AIシステムが個人に重大な影響を与える自動化された決定を行い、それらの個人がEU居住者である場合、第22条が適用される可能性があります。自動スコアリングに基づくリードルーティング決定は、決定が個人に重大な影響(例:サービスへのアクセスやビジネスによる扱いに影響する)を与える場合にスコープに入る可能性があります。関連する義務には、人間のレビューの権利、決定ロジックの説明、決定に異議を申し立てる権利が含まれます。GDPR第22条の自動意思決定は法務チームと確認すべき具体的な条文です。多くのB2B Sales Opsチームはリードルーティングが第22条の「重大な影響」の閾値を満たさないと主張します。法務レビューが必要であり、仮定ではありません。
SOX(サーベンス・オクスリー法、米国上場企業向け): AIドリブンのフォーキャスティングまたはPipeline管理が重要な収益認識決定に影響する場合、SOXの内部統制が適用される可能性があります。特にSection 302(開示統制)とSection 404(財務報告に対する内部統制)は、管理職が財務報告に対する統制の有効性を評価し、証明することを要求します。適切な文書化と統制のテストなしに収益予測データに影響を与えるAIシステムは潜在的なSOXリスクです。AIフォーキャスティングを展開する上場企業は、早い段階で内部監査と外部監査チームを関与させるべきです。
EU AI Act(すべてのEU市場企業、2026〜2027年): 規制(EU)2024/1689、EU AI Actは2024年8月に施行され、2027年まで段階的なコンプライアンス期限が適用されます。採用・従業員管理・サービスへのアクセスに使用されるAIシステムは、適合性評価と文書化要件を必要とする高リスクカテゴリーに入ります。EU市場で事業を行うB2B Sales Opsチームは、2026年8月のコンプライアンス期限前にAIスコアリングとルーティングシステムにどの条項が適用されるかを評価すべきです。
MAR / MiFID II(EU金融サービス): AI Sales Opsを使用する金融サービス企業では、市場濫用規制とMiFID IIがコミュニケーションのアーカイブ要件、適合性評価の文書化要件、ベストエクゼキューション監査証跡を追加します。金融サービスにおけるコール録音は単なるコーチングツールではありません。規制上のアーカイブです。保持期間(通常5〜7年)とアクセス制御要件は標準的なSales Opsガバナンスより厳格です。
規制を受けていないほとんどのミッドマーケットB2B企業では、GDPR第22条がリードスコアリングとルーティングのための主要な関連フレームワークであり、法務レビューが必要ですが、必ずしもコンプライアンスプログラムの構築が必要なわけではありません。重要なアクション:法務チームがAIスコアリングのユースケースをレビューし、第22条の「重大な影響」の閾値を満たすかどうかを結論付けたことを文書化し、その文書を保持してください。
ガバナンス成熟度レベル
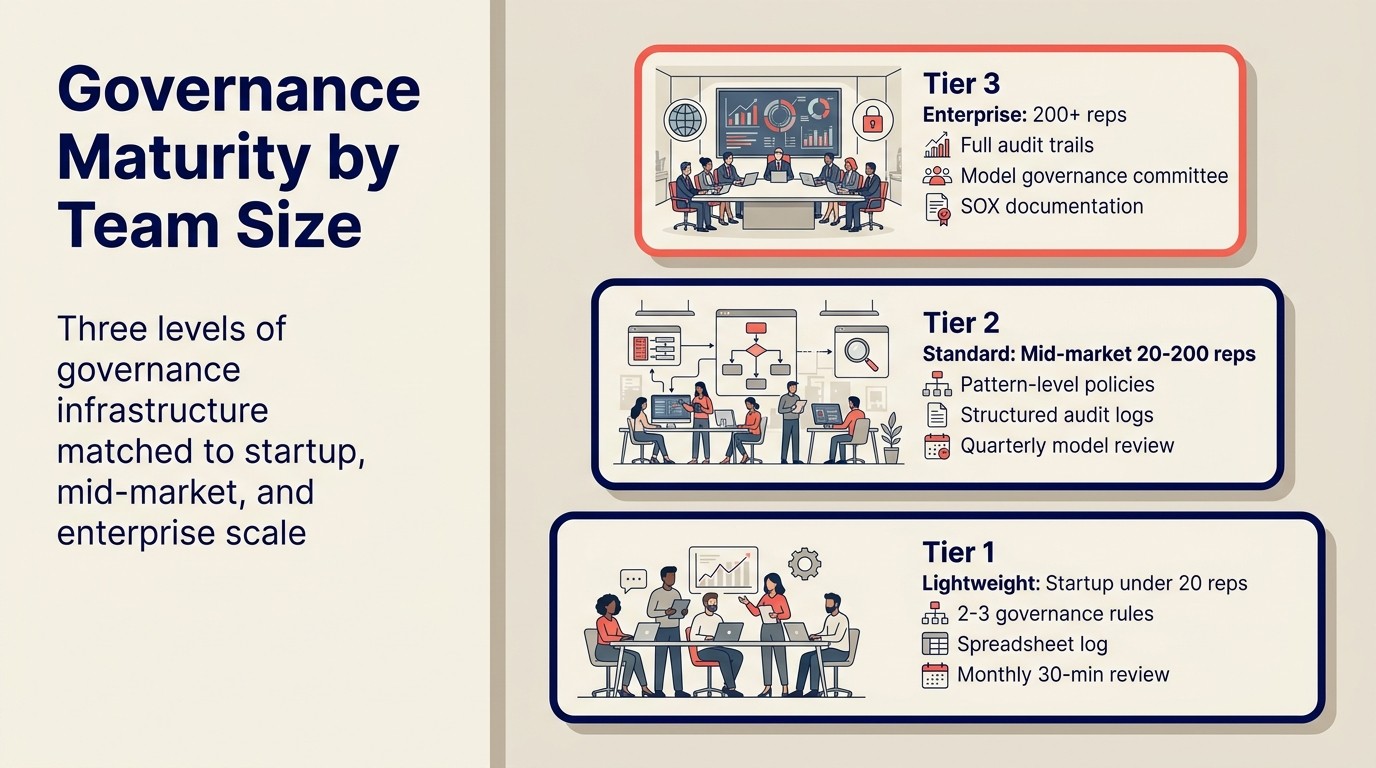
ガバナンス要件は企業規模、複雑さ、規制リスクに応じてスケールします。10名の営業チームのためにエンタープライズガバナンスインフラを構築しないでください。
軽量(スタートアップ、担当者20名未満):
- 2〜3つのガバナンスルール:録音同意プロセス、ルーティング異議申し立てパス、エンタープライズアカウントのメール承認
- CRMカスタムフィールドまたは共有スプレッドシートの監査ログ
- Sales Opsリードによる月次30分レビュー
- 専用のガバナンスツールは不要
標準(ミッドマーケット、担当者20〜200名):
- AIツールごとにパターンレベルのポリシーを文書化
- CRMまたは専用ログテーブルの構造化監査ログ
- スコアリングモデルの四半期精度レビュー
- SLAが定義されたルーティング異議申し立てプロセス
- GDPRの法務レビューが完了し文書化済み
- 年次ベンダーセキュリティレビュー(SOC 2レポート、データ処理契約が最新)
エンタープライズ(担当者200名以上、または規制対象産業):
- 商談と担当者でリンクされた全4パターンにわたる完全な監査証跡
- モデルガバナンス委員会(RevOpsリード、法務、データエンジニアリング)
- 四半期モデル精度とバイアスレビュー
- VP RevOpsへのエスカレーションパスを持つルーティング異議申し立てプロセス
- 上場企業のSOX内部統制文書化
- 事業管轄区域ごとのデータ居住確認
- AIデータパイプラインの年次ペネトレーションテスト
ガバナンスと信頼:本当の意義
ガバナンスの実務的な議論はコンプライアンスと異議申し立ての解決です。しかし戦略的な議論は信頼です。
説明なし、ログなし、異議申し立てのパスなしで目に見えない決定を行うAIシステムは、最終的にそのアウトプットとともに生活している担当者の信頼を失います。ルーティングモデルを信頼しない担当者はその割り当てを無視します。スコアリングモデルを信頼しない担当者は、モデルが推奨するリードではなく、自分が対応したいリードに取り組みます。
ここに文書化されているすべてのガバナンスメカニズム(監査ログ、異議申し立てプロセス、承認ゲート)は信頼メカニズムでもあります。これは担当者に言っています。「このシステムがあなたに影響を与える決定を下していることを知っています。それらの決定の記録があります。決定が間違っていると思ったら、異議を申し立てる方法があります。」それは官僚主義ではありません。それはAI Sales Opsが実際に使われるようになる運用契約です。
ガバナンスをスキップしたときに何が起こるかについては失敗モード:AI Sales Opsが裏目に出るときを、適切なレビューゲートでCRM自動書き込みを設定する方法についてはコールからCRM自動更新へをご覧ください。
Rework分析: 最も一貫して見られるガバナンスのギャップはGDPR第22条の分析(ほとんどのチームはこれを行います)ではなく、モデルバージョン管理にあります。チームは通常、現在のルーティングルールを説明できます。しかし4ヶ月前のルーティング決定は説明できません。その後2回スコアリングモデルを更新していて、どのバージョンがどの決定を行ったかを記録していなかったからです。監査ログにおけるモデルバージョン管理は、基本的なログ記録は持っているがデータが蓄積されるにつれてモデルを再トレーニングし始めているミッドマーケットチームにとって、単一の最高価値のガバナンス改善です。
次に読む記事
- GenerateとExecuteの境界:ガードレールが重要な理由:すべてのガバナンス設計の背後にある基盤的なACE原則
- パターン別ガバナンス要件:全10のAIパターンにわたるパターンレベルのガバナンス義務
- AI Sales Ops実装ロードマップ:ガバナンスが段階的な展開計画にどう組み込まれるか
- 失敗モード:AI Sales Opsが裏目に出るとき:ガバナンスをオプション扱いにしたときに何が起こるか
