More in
AI bei der Arbeit: Neuigkeiten
OpenAI hat ChatGPT-Werbung für kleine Unternehmen ohne Mindestbudget geöffnet
Juni 6, 2026
AI ist überall im Arbeitsalltag. Nur 1 von 10 sagt, sie hat den Job grundlegend verändert
Juni 6, 2026
Vibe Codings 10,5-Mrd.-USD-Moment: AI startet jetzt die meisten neuen Software-Projekte
Juni 6, 2026
AI Agents haben jetzt mehr Systemzugriff als Ihre Mitarbeiter. Die wenigsten sind abgesichert
Juni 5, 2026
Selbst bauen oder kaufen? Beobachten Sie, was die Branchenriesen erworben haben.
Juni 5, 2026
Uber begrenzt die AI-Ausgaben pro Mitarbeiter auf 1.500 USD nach einem Budget-Überschuss
Juni 5, 2026
Trumps AI-Dekret ist deregulatorisch. Ihr Compliance-Risiko hat sich nicht verändert
Juni 4, 2026
AI hat 220 Einhörner unter 1 Mrd. USD gedrückt. Unternehmen aus der Vor-ChatGPT-Ära stehen vor einer Abrechnung
Juni 4, 2026
Token-Preise fielen in diesem Jahr um 67 %. Ihre AI-Rechnung steigt trotzdem
Juni 3, 2026
Kleine Unternehmen, die AI einsetzen, berichten von höheren Umsätzen und kürzeren Arbeitstagen
Juni 3, 2026
Alle vier Big-Four-Firmen haben in 18 Tagen einen AI-Stack gewählt. Hier ist das CIO-Beschaffungsmuster
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
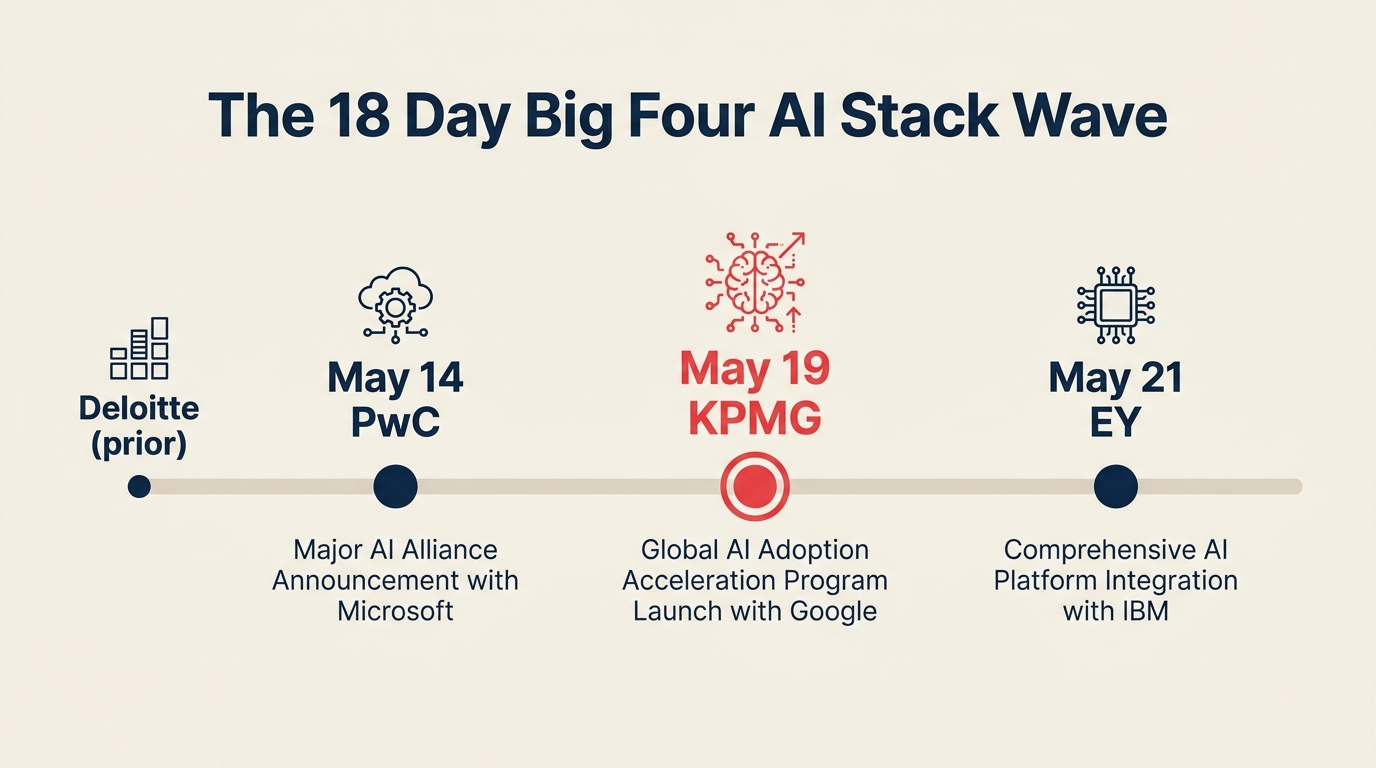
Das Zeitfenster des „Abwartens" bei der Enterprise-AI-Anbieterauswahl hat sich gerade geschlossen. Zwischen dem 14. und 21. Mai 2026 unterzeichneten drei der vier Big-Four-Wirtschaftsprüfungsgesellschaften primäre AI-Partnerschaften mit Anthropic, während die vierte Microsoft festlegte. Alle vier Firmen haben ihre Entscheidungen innerhalb von 18 Tagen getroffen.
Das ist kein Zufall. Es ist ein Beschaffungsmuster. Und wenn Sie als Chief Information Officer (CIO) in den nächsten 12 Monaten in eine Anbieterverlängerung gehen, verändert das Ihre Kalkulation auf eine Weise, die die meisten AI-Beschaffungsframeworks noch nicht berücksichtigt haben.
Laut Fortunes Berichterstattung über den KPMG-Anthropic-Deal ist die Big-Four-Konsolidierung Teil einer breiteren Welle der Festlegung auf Enterprise-AI-Stacks, die sich Anfang Mai zu beschleunigen begann. Die Firmen, die Ihren Aufsichtsrat beraten, Ihre Prüfungen durchführen und Ihre Transformationsprogramme liefern, haben alle Seiten gewählt. Diese Verschiebung hat nachgelagerte Konsequenzen, die Ihr nächstes Steuerungskomitee wahrscheinlich noch nicht besprochen hat.
Was jede Firma tatsächlich gewählt hat
Die Abfolge ging schnell. Hier ist, was jede Firma angekündigt hat und was es abdeckt:
| Datum | Firma | Anbieter | Umfang |
|---|---|---|---|
| Vor Mai 2026 | Deloitte | Anthropic Claude | Erweiterter Enterprise-Deal über Kundenlieferung |
| 14. Mai 2026 | PwC | Anthropic Claude | Schulung und Zertifizierung von 30.000 US-Fachleuten auf Claude |
| 19. Mai 2026 | KPMG | Anthropic Claude | Vollständige Belegschaftslizenzen (ca. 276.000 Mitarbeitende); Bereitstellung über Microsoft Azure bis September 2026; Einführung beginnend mit Steuer und Recht, dann Beratung |
| 21. Mai 2026 | EY | Microsoft 365 Copilot | Initiative von mehr als 1 Mrd. USD, die Copilot auf mehr als 400.000 EY-Mitarbeitende ausweitet |
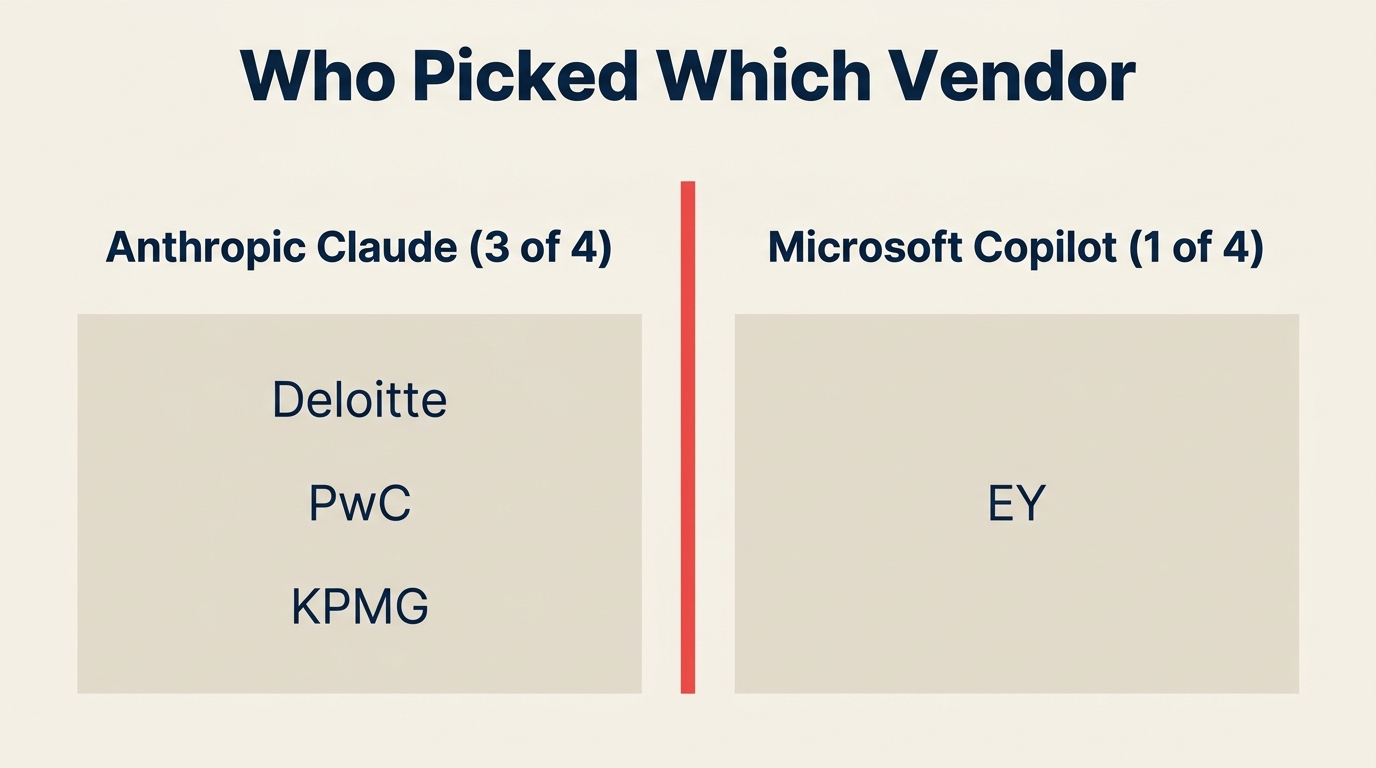
Die Aufteilung ergibt 3:1 zugunsten von Anthropic. Bis September 2026 werden etwa 1,1 Millionen Big-Four-Fachleute bei Deloitte, PwC und KPMG täglich mit Claude arbeiten. EY behielt Microsoft durch direkte Copilot-Bereitstellung bei, statt der Anthropic-Welle beizutreten.
Key Facts
- Etwa 1,1 Millionen Big-Four-Fachleute werden bis September 2026 Anthropic Claude nutzen (Deloitte + PwC + KPMG zusammen). (Fortune, Mai 2026)
- KPMGs Deal umfasst die gesamte Belegschaft von etwa 276.000 Mitarbeitenden, mit auf Azure gehosteter Bereitstellung für Q3 2026. (ResultSense, Mai 2026)
- EYs Microsoft Copilot-Initiative übersteigt 1 Mrd. USD und umfasst mehr als 400.000 Mitarbeitende. (Fortune, Mai 2026)
Dieselbe Woche sah auch Anthropic und Blackstone eine gemeinsame Unternehmung (JV) über 1,5 Mrd. USD am 4. Mai ankündigen und OpenAI am 11. Mai eine Bereitstellungsgesellschaft mit etwa 150 vorwärts eingesetzten Engineers lancieren. Der AI-Stack für Professional Services ist jetzt institutionell, nicht mehr experimentell.
Warum das das „Abwarten"-Zeitfenster für CIOs schließt
Das Argument der technischen Inkompatibilität hatte nie viel Überzeugungskraft. Claude und Copilot können in den meisten Enterprise-Umgebungen koexistieren. Der eigentliche Druck ist nicht technischer Natur. Er ist beweisbasierter Natur.
Wenn Ihr Wirtschaftsprüfer, Ihr Strategieberater und Ihr Transformationspartner alle denselben AI-Stack nutzen, akkumuliert dieser Stack etwas Dauerhafteres als Marktanteile: er akkumuliert Nachweise. Governance-Vorlagen, Prüfungsbereitschafts-Playbooks, Risikoklassifizierungs-Voreinstellungen, Partner-Bereitstellungsmaterialien und Steuerungskomitee-Briefingpakete. In den nächsten 18 Monaten werden die Best-Practice-Bibliotheken in diesen Bereichen von und für Claude-Nutzer (und auf der EY-Seite Copilot-Nutzer) aufgebaut werden. Unternehmen auf einem anderen Stack werden nicht ausgesperrt sein, aber sie werden sich in einem permanenten Übersetzungslayer befinden.
Die Kosten sind keine Wechselkosten im klassischen Sinne. Es sind die stilleren, sich ansammelnden Kosten, bei jedem Beratungsauftrag einen Schritt hinter der Referenzarchitektur anzukommen, die Ihre Berater voraussetzen.
Das schlägt sich bereits in der Entstehung von Governance-Lücken auf der Beratungsebene nieder. Wenn die Big-Four-Firma, die Ihre nächste AI-Governance-Überprüfung durchführt, über eigene interne Claude-Playbooks verfügt, werden die Benchmarks, die sie in Ihre Organisation bringt, das widerspiegeln. Ihr CIO-Team muss entweder mit diesen Playbooks vertraut sein oder die Lücke explizit benennen.
Der Parallelkontext ist hier ebenfalls relevant. Das ACE-Framework (Ingest, Analyze, Predict, Generate, Execute) zeigt auf, wo Enterprise-AI über fünf Fähigkeitsstufen Wert schafft. Die Big-Four-Entscheidungen decken nicht alle fünf Stufen für jeden Kunden ab, aber sie legen die Standard-Linse für Beratungsarbeit auf den obersten drei Stufen fest. Wenn Ihre internen AI-Programme einer anderen Taxonomie zugeordnet sind, wird sich Ihre nächste Prüfung wie ein Übersetzungsproblem anfühlen.
Für CIOs, die 2025 und Anfang 2026 damit verbracht haben, ehrliche Kostenmodelle für AI-Transformation aufzubauen, fügt die Big-Four-Welle einen neuen Kostenfaktor hinzu: Berater-Stack-Ausrichtung. Das ist kein Budgetkiller, aber auch nicht kostenlos.
Der Big-Four-Stack-Test: 5 Fragen für Ihre nächste CIO-Anbieterbewertung
Das ist ein Framework, das Sie an einem Nachmittag durchführen können. Bevor Sie Ihre nächste AI-Anbieterverlängerung oder Ihren Budgetzyklus angehen, besorgen Sie sich Antworten auf diese fünf Fragen:
1. Welche Big-Four-Firma prüft oder berät uns, und auf welchen AI-Stack richtet sie ihre Leistungserbringung aus? Gehen Sie nicht davon aus. Fragen Sie Ihren Prüfungspartner oder Transformationsleiter direkt, auf welcher AI-Plattform ihre internen Lieferteams geschult sind. Wenn es Claude ist, finden Sie heraus, wie ihre Liefergegenstände auf Claude-Fähigkeiten Bezug nehmen. Wenn es Copilot ist (EY-ausgerichtet), gilt dieselbe Frage von der Microsoft-Seite.
2. Sind unsere internen AI-Governance-Richtlinien generisch formuliert, oder sind sie bereits implizit auf die Sicherheitsdokumentation eines bestimmten Anbieters ausgerichtet? Die meisten Governance-Vorlagen übernehmen Formulierungen aus den veröffentlichten Sicherheitsdokumenten des Anbieters. Wenn Ihr Richtlinienteam Anthropics Constitutional-AI-Grundsätze oder Microsofts Responsible-AI-Standards verwendet hat, hat Ihr Framework bereits eine implizite Ausrichtung. Kennen Sie diese, bevor Ihr nächster Berater mit seiner auftaucht.
3. Verfügt unser aktueller AI-Anbieter über eine veröffentlichte Interoperabilitätsstrategie mit den Bereitstellungs-Playbooks der Big-Four-Firmen? Die Kaufen-oder-selbst-entwickeln-Entscheidung nach Muster ändert sich, wenn eine dritte Partei (Ihr Berater) effektiv ein Bereitstellungsakteur in Ihrer Transformation ist. Fragen Sie Ihre Anbieter direkt: Wie sieht Ihre Big-Four-Partnerschaft aus, und welche Referenzarchitekturen teilen Sie mit ihnen?
4. Was sind die Wechselkosten, um den bevorzugten Stack der Big Four als sekundäre Fähigkeit hinzuzufügen (nicht zu ersetzen)? Die meisten CIOs formulieren das als Ersetzen-oder-Bleiben. Das ist der falsche Rahmen. Die günstigere Frage lautet: Was kostet es, eine Claude- (oder Copilot-) Umgebung für Beratungsaufträge verfügbar zu haben, ohne Ihren primären Stack zu stören? Das autonome Agent-Muster läuft insbesondere als sekundäre Fähigkeit in den meisten Multi-Cloud-Umgebungen problemlos.
5. Verfolgen wir „Berater-Stack-Ausrichtung" als Beschaffungskriterium, und wenn nicht, wann fügen wir es hinzu? Das ist das Kriterium, das derzeit in den meisten Enterprise-AI-Beschaffungs-Scorecards fehlt. Anbieterleistung, Sicherheitsstatus, Kosten pro Lizenz und Integrationstiefe sind Standard. Berater-Stack-Ausrichtung ist neu. AI-Genehmigungsstufen und Anbieterbewertungsprozesse sind der richtige Ort, um dies in Ihrem nächsten Zyklus als Bewertungsdimension hinzuzufügen.
Was Sie diese Woche tun sollten
Diese Woche:
- Fragen Sie Ihren primären Big-Four-Kontakt (Prüfung, Beratung oder Transformation), welche AI-Plattform seine Lieferteams intern verwenden. Eine E-Mail, eine Frage.
- Ziehen Sie Ihre aktuelle AI-Governance-Richtlinie heran und ermitteln Sie, woher die Formulierungen des Sicherheitsframeworks stammen. Notieren Sie, ob sie anbieterneutral oder implizit ausgerichtet sind.
- Prüfen Sie, ob Ihr aktueller AI-Anbieter veröffentlichte Partnerschafts- oder Interoperabilitätsinhalte mit KPMG, PwC, Deloitte oder EY hat. Das ist in der Regel öffentlich zugänglich.
- Informieren Sie Ihren CFO darüber, was Berater-Stack-Ausrichtung für Ihr AI-Budget bedeutet, bevor es als Kostenfaktor in einem Steuerungskomitee auftaucht, auf das er nicht vorbereitet war.
In den nächsten 30 Tagen:
- Fügen Sie „Berater-Stack-Ausrichtung" als Kriterium zu Ihrer AI-Anbieter-Scorecard hinzu. Selbst eine einfache Rot/Gelb/Grün-Bewertung erzwingt das Gespräch.
- Wenn Ihr primärer Stack von dem Ihrer Berater abweicht, führen Sie eine Umfangsübung durch: Was würde eine sekundäre Claude- oder Copilot-Umgebung kosten, und welche Beratungsaufträge würden davon profitieren?
- Ordnen Sie Ihre bestehenden AI-Initiativen der Beratungsebene zu, die sie in den nächsten 12 Monaten überprüfen wird. Wo sind die Übersetzungslücken?
- Überprüfen Sie, wie AI-ROI gemessen wird bei Ihrem aktuellen Anbieter gegenüber den Benchmarks, die Ihre Berater wahrscheinlich mitbringen werden. Schließen Sie die Lücke vor der Prüfung, nicht danach.
- Überarbeiten Sie Ihr Kaufen-vs.-Selbstentwickeln-vs.-Partnerschafts-Framework mit dem Big-Four-Stack-Kontext. Die „Partner"-Option hat jetzt eine klarere Definition davon, was „partner-ready" bedeutet.
Häufig gestellte Fragen
Bedeutet das, dass wir unseren AI-Anbieter wechseln müssen, weil die Big Four Claude oder Copilot gewählt haben?
Nein. Die Big-Four-Entscheidungen betreffen deren interne Lieferkapazität, kein Mandat für ihre Kunden. Die praktische Auswirkung ist jedoch, dass die Beweisbasis, Governance-Vorlagen und Beratungs-Playbooks, die in den nächsten 18 Monaten aus den Big Four kommen, auf Claude und Copilot aufgebaut sein werden. Sie müssen nicht wechseln, aber Sie sollten verstehen, wo Ihr Stack vom Standard abweicht, und einen Überbrückungsplan für Beratungsaufträge bereithalten.
EY hat Microsoft gewählt, während die anderen drei Anthropic gewählt haben. Spielt das eine Rolle?
Es spielt eine Rolle dafür, welche Beratungs-Playbooks zu Ihnen kommen. Wenn EY Ihr Unternehmen prüft oder Ihre Transformation leitet, wird die Copilot-Referenzarchitektur stärker in Ihren Liefergegenständen präsent sein als Claudes. Wenn eine der anderen drei Firmen Sie berät, werden Claudes Frameworks dominieren. CIOs, die mit Firmen aus beiden Lagern arbeiten (was bei größeren Unternehmen häufig ist), sollten beide Stacks verfolgen statt von einer Standardlösung auszugehen.
Wie lange hält dieser Vorteil der „Berater-Stack-Ausrichtung" an, bevor er zur Handelsware wird?
Der Beweisvorteil ist für ungefähr 18 bis 24 Monate dauerhaft. Danach werden Best Practices veröffentlicht, Frameworks standardisiert und die Ausrichtungslücke schrumpft. Aber jetzt befinden Sie sich in der frühen Akkumulationsphase. Unternehmen, die Beratungspraxen auf einem Stack aufbauen, erstellen Artefakte (Prüfvorlagen, Risikorubrics, Bereitstellungs-Playbooks), deren Umschreiben Zeit kostet. Das Zeitfenster für proaktives Engagement ist jetzt, nicht 2028.
Mehr erfahren
