More in
Berita AI di Tempat Kerja
OpenAI Membuka Iklan ChatGPT untuk Bisnis Kecil dengan Anggaran Berapa Pun
Jun 6, 2026
AI Ada di Mana-mana di Tempat Kerja. Hanya 1 dari 10 yang Menyatakan AI Benar-benar Mengubah Pekerjaan Mereka
Jun 6, 2026
Momen $10,5 Miliar Vibe Coding: AI Kini Memulai Sebagian Besar Pembangunan Perangkat Lunak Baru
Jun 6, 2026
AI Agent Kini Memiliki Akses Sistem Lebih Besar dari Karyawan Anda. Sedikit yang Sudah Diamankan
Jun 5, 2026
Bangun atau Beli AI Anda? Perhatikan Apa yang Dibeli Para Raksasa.
Jun 5, 2026
Uber Membatasi Pengeluaran AI Karyawan di $1.500 per Kursi Setelah Anggaran Jebol
Jun 5, 2026
Perintah Eksekutif AI Trump Bersifat Deregulasi. Risiko Kepatuhan Anda Tidak Berubah
Jun 4, 2026
AI Mendorong 220 Unicorn Turun di Bawah $1 Miliar. Perusahaan Pra-ChatGPT Menghadapi Tantangan Besar
Jun 4, 2026
Harga Token Turun 67% Tahun Ini. Tagihan AI Anda Tetap Naik
Jun 3, 2026
Bisnis Kecil yang Menggunakan AI Melaporkan Pendapatan Lebih Tinggi dan Jam Kerja Lebih Singkat
Jun 3, 2026
Bahasa Indonesia
Keempat Big Four Memilih Tumpukan AI dalam 18 Hari. Inilah Pola Pengadaan CIO
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
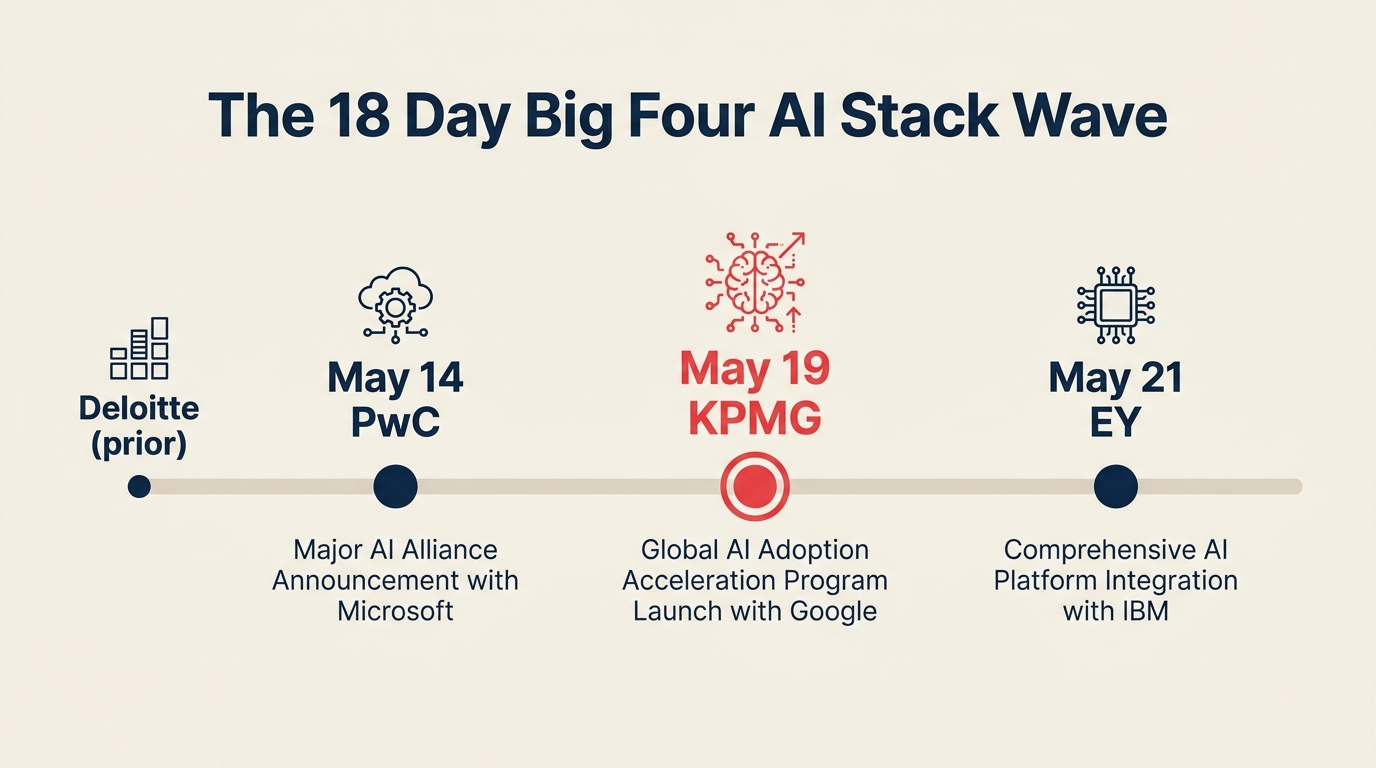
Jendela "tunggu dan lihat" untuk pemilihan vendor AI enterprise baru saja tertutup. Antara 14 dan 21 Mei 2026, tiga dari empat firma jasa profesional Big Four menandatangani kemitraan AI utama dengan Anthropic, sementara satu lagi mengunci Microsoft. Keempat firma membuat keputusan mereka dalam 18 hari.
Ini bukan kebetulan. Ini adalah pola pengadaan. Dan jika Anda seorang Chief Information Officer (CIO) yang akan memasuki pembaruan vendor dalam 12 bulan ke depan, ini mengubah perhitungan Anda dengan cara yang belum diikuti oleh kebanyakan kerangka pengadaan AI.
Menurut laporan Fortune tentang kesepakatan KPMG-Anthropic, konsolidasi Big Four adalah bagian dari gelombang lebih luas penguncian tumpukan AI enterprise yang mulai berakselerasi pada awal Mei. Firma-firma yang menasihati dewan Anda, menjalankan audit Anda, dan mengirimkan program transformasi Anda semuanya telah memilih pihak. Pergeseran itu memiliki konsekuensi hilir yang mungkin belum dibahas oleh komite pengarah Anda berikutnya.
Apa yang Sebenarnya Dipilih Setiap Firma
Urutannya bergerak cepat. Inilah yang diumumkan setiap firma dan cakupannya:
| Tanggal | Firma | Vendor | Cakupan |
|---|---|---|---|
| Sebelum Mei 2026 | Deloitte | Anthropic Claude | Kesepakatan enterprise yang diperluas di seluruh pengiriman klien |
| 14 Mei 2026 | PwC | Anthropic Claude | Melatih dan mensertifikasi 30.000 profesional AS pada Claude |
| 19 Mei 2026 | KPMG | Anthropic Claude | Lisensi seluruh tenaga kerja (~276.000 karyawan); penerapan melalui Microsoft Azure pada September 2026; peluncuran dimulai dengan Tax dan Legal, kemudian advisory |
| 21 Mei 2026 | EY | Microsoft 365 Copilot | Inisiatif senilai lebih dari $1 miliar yang memperluas Copilot ke lebih dari 400.000 staf EY |
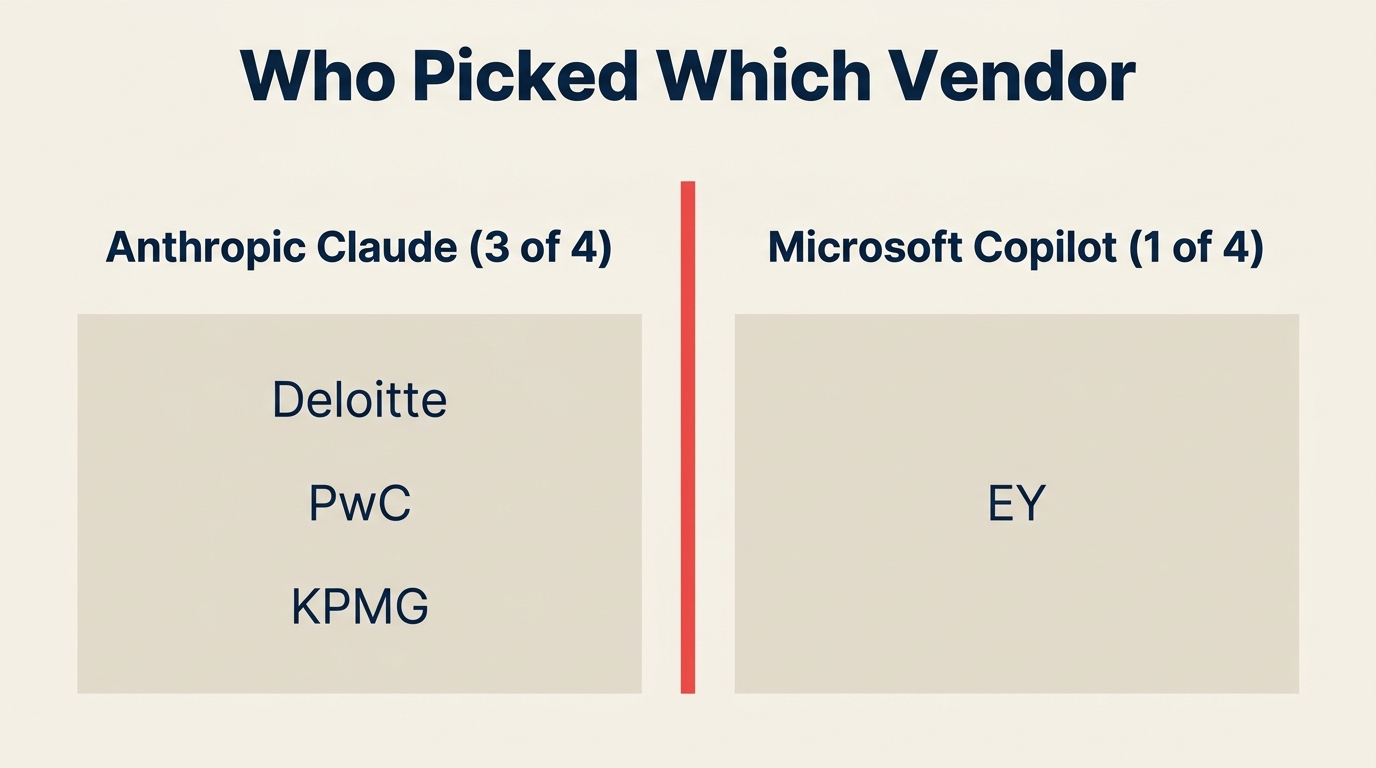
Pembagiannya 3 berbanding 1 mendukung Anthropic. Pada September 2026, sekitar 1,1 juta profesional Big Four di Deloitte, PwC, dan KPMG akan bekerja sehari-hari di dalam Claude. EY mempertahankan Microsoft melalui penerapan Copilot langsung, bukan bergabung dengan gelombang Anthropic.
Fakta Utama
- Sekitar 1,1 juta profesional Big Four akan menggunakan Anthropic Claude pada September 2026 (gabungan Deloitte + PwC + KPMG). (Fortune, Mei 2026)
- Kesepakatan KPMG mencakup seluruh tenaga kerjanya sekitar 276.000 karyawan, dengan penerapan berbasis Azure yang direncanakan untuk Q3 2026. (ResultSense, Mei 2026)
- Inisiatif Microsoft Copilot EY melebihi $1 miliar dan mencakup lebih dari 400.000 staf. (Fortune, Mei 2026)
Minggu yang sama juga melihat Anthropic dan Blackstone mengumumkan joint venture senilai $1,5 miliar pada 4 Mei dan OpenAI meluncurkan perusahaan penerapan senilai $4 miliar dengan sekitar 150 forward-deployed engineer pada 11 Mei. Tumpukan AI jasa profesional kini bersifat institusional, bukan eksperimental.
Mengapa Ini Menutup Jendela "Tunggu dan Lihat" bagi CIO
Argumen inkompatibilitas teknologi tidak pernah memiliki kekuatan besar. Claude dan Copilot dapat hidup berdampingan di sebagian besar lingkungan enterprise. Tekanan nyatanya bukan teknis. Ini bersifat pembuktian.
Ketika auditor Anda, penasihat strategi Anda, dan mitra transformasi Anda semuanya menjalankan tumpukan AI yang sama, tumpukan itu mengakumulasikan sesuatu yang lebih tahan lama dari pangsa pasar: ia mengakumulasikan bukti. Template tata kelola, playbook kesiapan audit, default klasifikasi risiko, materi kesiapan mitra, dan paket penjelasan komite pengarah. Selama 18 bulan ke depan, perpustakaan praktik terbaik di domain tersebut akan dibangun oleh dan untuk pengguna Claude (dan, di sisi EY, pengguna Copilot). Firma pada tumpukan yang berbeda tidak akan terkunci, tetapi mereka akan berada dalam lapisan terjemahan yang permanen.
Biayanya bukan biaya peralihan dalam arti klasik. Ini adalah biaya yang lebih tenang dan terus bertambah dari tiba di setiap keterlibatan advisory selangkah di belakang arsitektur referensi yang diasumsikan penasihat Anda sudah Anda jalankan.
Ini sudah terlihat dalam bagaimana kesenjangan tata kelola berkembang di lapisan advisory. Ketika firma Big Four yang melakukan tinjauan tata kelola AI Anda berikutnya memiliki playbook Claude internal sendiri, tolok ukur yang dibawanya ke organisasi Anda akan mencerminkan itu. Tim CIO Anda perlu fasih dalam playbook tersebut atau eksplisit tentang kesenjangan.
Konteks paralel juga penting di sini. ACE Framework (Ingest, Analyze, Predict, Generate, Execute) memetakan di mana AI enterprise menciptakan nilai di lima tingkat kemampuan. Pilihan Big Four tidak mencakup semua lima tingkat untuk setiap klien, tetapi mereka menetapkan lensa default untuk pekerjaan advisory di tiga tingkat teratas. Jika program AI internal Anda dipetakan ke taksonomi yang berbeda, audit Anda berikutnya akan terasa seperti masalah terjemahan.
Bagi CIO yang telah menghabiskan 2025 dan awal 2026 membangun model biaya yang jujur untuk transformasi AI, gelombang Big Four menambahkan item baris baru: keselarasan tumpukan advisor. Ini bukan pembunuh anggaran, tetapi juga tidak gratis.
Uji Tumpukan Big Four: 5 Pertanyaan untuk Tinjauan Vendor CIO Berikutnya
Ini adalah kerangka yang bisa Anda jalankan dalam satu hari. Sebelum pembaruan vendor AI atau siklus anggaran berikutnya, dapatkan jawaban atas lima pertanyaan ini:
1. Firma Big Four mana yang mengaudit atau menasihati kami, dan ke tumpukan AI apa mereka menyelaraskan pengiriman mereka? Jangan berasumsi. Tanya langsung mitra audit atau lead transformasi Anda platform AI mana yang dilatih tim pengiriman internal mereka. Jika Claude, cari tahu bagaimana hasil kerja mereka merujuk kemampuan Claude. Jika Copilot (selaras EY), pertanyaan yang sama berlaku dari sisi Microsoft.
2. Apakah kebijakan tata kelola AI internal kami ditulis secara generik, atau sudah bias ke dokumentasi keamanan vendor tertentu? Sebagian besar template tata kelola mengambil bahasa dari dokumen keamanan yang diterbitkan vendor. Jika tim kebijakan Anda mengambil dari prinsip Constitutional AI Anthropic atau standar Responsible AI Microsoft, kerangka Anda sudah memiliki keselarasan implisit. Ketahui mana sebelum penasihat Anda datang membawa milik mereka.
3. Apakah vendor AI kami saat ini memiliki cerita interoperabilitas yang diterbitkan dengan playbook penerapan firma Big Four? Keputusan beli atau bangun berdasarkan pola berubah ketika pihak ketiga (penasihat Anda) secara efektif menjadi aktor penerapan dalam transformasi Anda. Tanya vendor Anda langsung: seperti apa kemitraan Big Four Anda, dan arsitektur referensi apa yang Anda bagikan dengan mereka?
4. Berapa biaya peralihan untuk menambahkan (bukan mengganti) tumpukan pilihan Big Four sebagai kemampuan sekunder? Kebanyakan CIO membingkai ini sebagai ganti-atau-tetap. Itu bukan kerangka yang tepat. Pertanyaan yang lebih murah adalah: berapa biayanya untuk memiliki lingkungan Claude (atau Copilot) tersedia untuk keterlibatan advisory, tanpa mengganggu tumpukan utama Anda? Pola agen otonom khususnya berjalan dengan bersih sebagai kemampuan sekunder di sebagian besar lingkungan multi-cloud.
5. Apakah kami melacak "keselarasan tumpukan advisor" sebagai kriteria pengadaan, dan jika tidak, kapan kami menambahkannya? Ini adalah kriteria yang hilang dari sebagian besar scorecard pengadaan AI enterprise saat ini. Kinerja vendor, posisi keamanan, biaya per kursi, dan kedalaman integrasi adalah standar. Keselarasan tumpukan advisor itu baru. Proses gerbang persetujuan AI dan tinjauan vendor adalah tempat yang tepat untuk menambahkan ini sebagai dimensi evaluasi dalam siklus berikutnya.
Yang Harus Dilakukan Minggu Ini
Minggu ini:
- Tanya kontak Big Four utama Anda (audit, advisory, atau transformasi) platform AI mana yang digunakan tim pengiriman mereka secara internal. Satu email, satu pertanyaan.
- Tarik kebijakan tata kelola AI Anda saat ini dan identifikasi dari mana bahasa kerangka keamanannya berasal. Catat apakah itu netral vendor atau selaras secara implisit.
- Periksa apakah vendor AI Anda saat ini memiliki konten kemitraan atau interoperabilitas yang diterbitkan dengan KPMG, PwC, Deloitte, atau EY. Ini biasanya publik.
- Informasikan CFO Anda tentang arti keselarasan tumpukan advisor untuk anggaran AI Anda sebelum itu muncul sebagai item baris dalam komite pengarah yang tidak mereka siapkan.
30 hari ke depan:
- Tambahkan "keselarasan tumpukan advisor" sebagai kriteria ke scorecard vendor AI Anda. Bahkan penilaian merah/kuning/hijau sederhana memaksa percakapan.
- Jika tumpukan utama Anda berbeda dari tumpukan advisor Anda, jalankan latihan pelingkupan: berapa biaya lingkungan Claude atau Copilot sekunder, dan keterlibatan advisory mana yang akan mendapat manfaat dari itu?
- Petakan inisiatif AI Anda yang ada terhadap lapisan advisory yang akan meninjaunya dalam 12 bulan ke depan. Di mana kesenjangan terjemahan?
- Tinjau cara mengukur AI ROI dengan vendor Anda saat ini terhadap tolok ukur yang kemungkinan akan dibawa advisor Anda. Tutup kesenjangan sebelum tinjauan, bukan setelahnya.
- Revisit kerangka bangun vs. beli vs. mitra Anda dengan konteks tumpukan Big Four ditambahkan. Opsi "mitra" kini memiliki definisi yang lebih jelas tentang apa artinya "siap bermitra."
Pertanyaan yang Sering Diajukan
Apakah ini berarti kami perlu mengganti vendor AI kami karena Big Four memilih Claude atau Copilot?
Tidak. Pilihan Big Four adalah tentang kapasitas pengiriman internal mereka, bukan mandat untuk klien mereka. Namun implikasi praktisnya adalah bahwa basis bukti, template tata kelola, dan playbook advisory yang keluar dari Big Four selama 18 bulan ke depan akan dibangun di atas Claude dan Copilot. Anda tidak harus beralih, tetapi Anda harus memahami di mana tumpukan Anda berbeda dari default dan memiliki rencana penghubung yang siap untuk keterlibatan advisory.
EY memilih Microsoft sementara tiga lainnya memilih Anthropic. Apakah itu penting?
Penting untuk set playbook advisory mana yang mengalir ke Anda. Jika EY mengaudit perusahaan Anda atau memimpin transformasi Anda, arsitektur referensi Copilot akan lebih hadir dalam hasil kerja Anda daripada Claude. Jika salah satu dari tiga firma lain menasihati Anda, kerangka Claude akan mendominasi. CIO yang bekerja dengan firma dari kedua kubu (yang umum di enterprise yang lebih besar) harus melacak kedua tumpukan daripada mengasumsikan satu default.
Berapa lama keunggulan "keselarasan tumpukan advisor" ini bertahan sebelum menjadi komoditas?
Keunggulan pembuktian bertahan selama sekitar 18 hingga 24 bulan. Setelah itu, praktik terbaik dipublikasikan, kerangka distandardisasi, dan kesenjangan keselarasan menyusut. Namun saat ini Anda berada dalam fase akumulasi awal. Firma yang membangun praktik advisory pada tumpukan menciptakan artefak (template audit, rubrik risiko, playbook pengiriman) yang membutuhkan waktu untuk ditulis ulang. Jendela untuk terlibat secara proaktif adalah sekarang, bukan di tahun 2028.
Pelajari Lebih Lanjut
