Các Mode Thất Bại AI trong SaaS: Điều Thực Sự Xảy Ra và Chi Phí Thực

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hầu hết thất bại AI trong SaaS không ồn ào. Không có sự cố. Không có tiêu đề báo. Sản phẩm ra mắt, changelog đi ra, thông cáo báo chí nói "chúng tôi đang đầu tư mạnh vào AI," và sau đó không có gì rõ ràng xảy ra.
Điều thực sự xảy ra là yên lặng hơn nhiều. Log tính năng AI cho thấy 3% weekly active usage ở tháng thứ ba. CSM (Customer Success Manager) ngừng mở dashboard health score vì nó gọi quá nhiều tài khoản là "at-risk" mà thực ra không churn. Support chatbot bị enterprise customer tắt lặng lẽ sau khi một câu trả lời sai leo thang lên VP CS của bạn. Content SEO do AI tạo ra ngỡ là năng suất cao giờ đang kích hoạt bộ lọc spam của Google trên các trang từng xếp hạng tốt.
Thất bại thầm lặng là mode chủ đạo. Và nó tốn kém hơn thất bại ồn ào vì bạn không biết nó đang xảy ra cho đến khi bạn đo downstream effects, thứ mà hầu hết team không làm.
Bài này bao gồm sáu mode thất bại cụ thể trong SaaS AI, chi phí thực sự và cách ngăn chặn. Không phải AI risk framework chung chung. Dành riêng cho revenue dynamics SaaS, buyer relationships SaaS và các AI tool SaaS company thực sự deploy.
6 Mode Thất Bại AI trong SaaS
6 Mode Thất Bại AI trong SaaS là diagnostic framework ánh xạ các cách phổ biến nhất SaaS AI initiative thất bại. Mode 1 (Tính năng không ai dùng): điểm chèn sai, chất lượng dưới ngưỡng tin cậy, hoặc discovery failure. Mode 2 (Content AI làm hỏng SEO): không có original contribution layer trên content do AI tạo, thin content kích hoạt Google quality penalty. Mode 3 (Output sai dẫn đến churn): customer-facing output do AI tạo không có review gate cho high-stakes scenario. Mode 4 (Token-cost runaway): flat-price bundle không có consumption architecture, power-user tail phá hủy unit economics. Mode 5 (No-moat feature match): AI feature đối thủ sao chép được trong 4-8 tuần không có telemetry loop tạo độ bền. Mode 6 (Support burden AI): AI recommendation dưới ngưỡng precision, tạo noise mà CSM và support agent học cách bỏ qua. Sáu mode không bằng nhau về xác suất hay chi phí, nhưng tất cả đều ngăn được bằng đo lường sớm.
Mode Thất Bại 1: Tính năng AI khách hàng không dùng
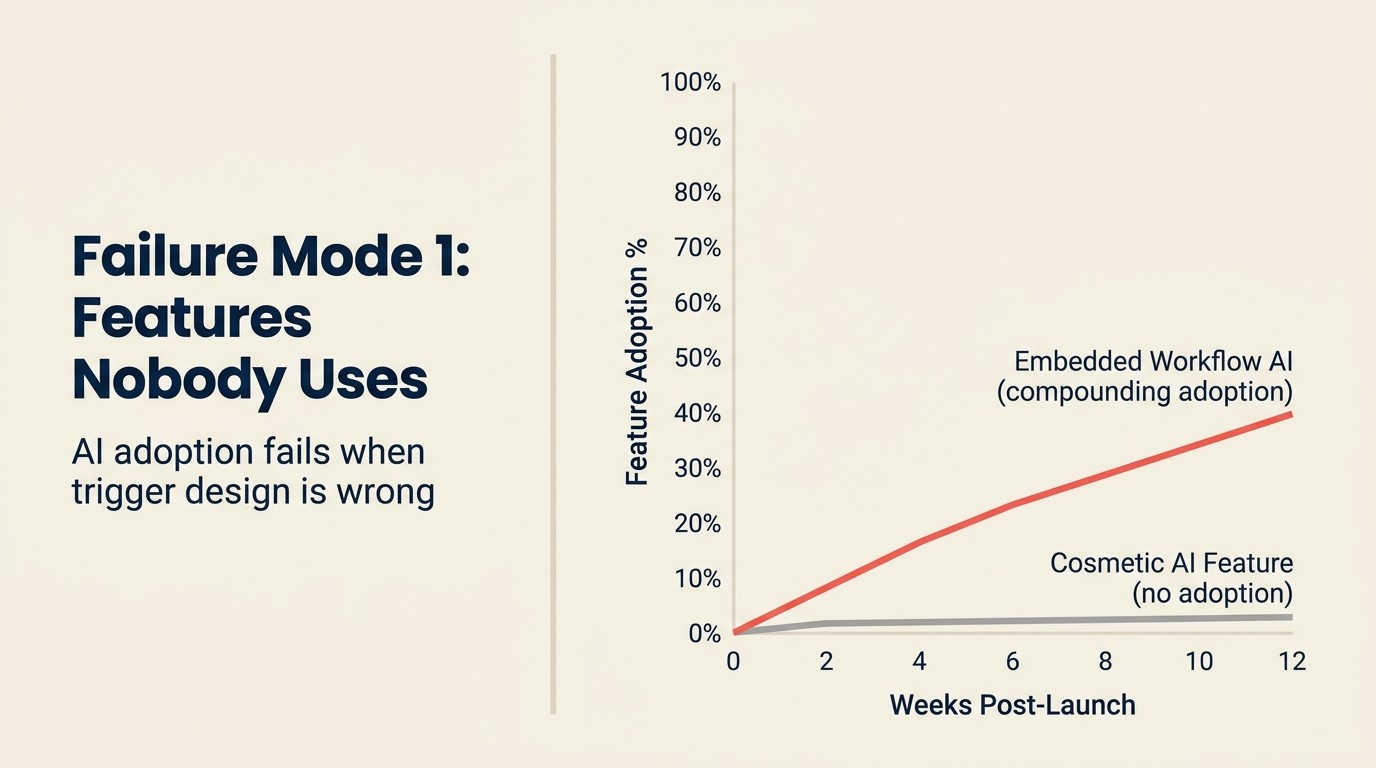
Bạn xây xong. Bạn ship. 3% người dùng đụng đến nó trong 30 ngày đầu, và bây giờ nó là một dòng trong annual report dưới "AI capabilities" mà không khách hàng trả phí nào nhắc đến.
Đây là mode thất bại AI phổ biến nhất trong SaaS và tốn kém nhất về opportunity cost. Một in-product AI copilot feature điển hình mất 3-4 tháng engineering để xây đúng: API integration, prompt design, telemetry, UI. Với blended engineering cost $250.000/năm, đó là $60.000-80.000 investment. Nếu 3% người dùng dùng nó và không ai trích dẫn nó là lý do gia hạn, bạn đốt $75.000 để thêm một dòng vào pricing page.
Nguyên nhân gốc rễ có thể chẩn đoán cụ thể. Gartner cho thấy ít nhất 50% generative AI project bị abandon sau proof of concept vì data quality kém, risk control không đủ, chi phí leo thang hoặc business value không rõ ràng. Zero-adoption feature là chuẩn ngành, không phải ngoại lệ.
Điểm chèn sai: AI xuất hiện trong phần workflow người dùng truy cập hai lần mỗi tuần, không phải mười lần mỗi ngày. AI suggestion trong workflow tần suất thấp không xây được habit cần thiết cho adoption. Điểm chèn AI có giá trị cao nhất nằm trong workflow tần suất cao nhất, không phải những cái trông ấn tượng nhất. AI features như sản phẩm: nơi thêm chúng cung cấp three-filter framework để xác định điểm chèn đúng trước khi build.
Chất lượng dưới ngưỡng tin cậy: Suggestion accuracy là 60-70% trong internal testing nhưng cảm giác như 40% với người dùng vì failure đáng nhớ hơn success. AI quality cần vượt trust threshold trước khi người dùng dựa vào nó. Dưới ngưỡng đó, người dùng thử một lần, gặp failure, và dừng. Trust threshold cao hơn hầu hết product team ước tính trong development.
Discovery failure: Người dùng không biết feature tồn tại hoặc cách access. Nghe như vấn đề marketing nhưng thực ra là product design problem. AI feature in-product yêu cầu người dùng navigate đến section riêng, hoặc chỉ xuất hiện trong settings menu, sẽ vô hình với hầu hết người dùng. Feature cần surface trong context, đúng lúc liên quan, không yêu cầu người dùng phải tìm.
Phòng ngừa: Đo ba leading indicator trước khi feature ship: expected insertion point frequency, benchmark quality threshold từ user testing (không phải internal testing), và discovery placement trong user flow. Nếu bất kỳ cái nào yếu, fix trước launch. Ship nhanh hơn không giúp gì nếu feature không bao giờ được adopt.
Key Facts: Tỷ Lệ Thất Bại AI trong SaaS
- Ít nhất 50% generative AI project bị abandon sau proof of concept vì data quality kém, risk control không đủ, chi phí leo thang hoặc business value không rõ ràng (Gartner, 2025)
- 60-70% enterprise gặp pilot failure trong AI deployment; chỉ 10-20% isolated AI experiment trong hai năm qua thực sự scale lên tạo value (MIT/McKinsey, 2025)
- Đến 2028, LLM (large language model) observability investment sẽ đạt 50% generative AI deployment vì hallucination, bias và trust failure sẽ cần monitoring infrastructure mà hầu hết SaaS company chưa build hôm nay (Gartner, 2026)
Mode Thất Bại 2: Content do AI tạo làm hỏng SEO

Một SaaS company phát hiện có thể tăng gấp 10 lần content output bằng cách để AI viết blog post, knowledge base article và landing page. Họ publish 200 bài AI-generated trong sáu tháng. Ba tháng sau, organic search traffic giảm 35%.
Chuyện này đã xảy ra. Và tiếp tục xảy ra. Chi phí không chỉ là sụt giảm traffic. Đó là recovery timeline: 12-18 tháng xây lại domain authority sau Google quality signal penalty, với điều kiện bạn đã xóa hoặc rewrite đáng kể content gây ra nó.
Cơ chế cụ thể: helpful content system của Google và manual review team gắn cờ thin, AI-generated content có ít original value. Page không thể hiện original research, specific expertise hoặc thông tin thực sự hữu ích không tồn tại ở nơi khác bị de-index hoặc bị giảm trọng số nặng. 200 bài AI-generated không có original research, không có author expertise signal, không có unique data là chính xác thứ các hệ thống này thiết kế để phạt.
Dollar impact: SaaS company $5M ARR với 30% customer acquisition qua organic search có thể đang generate $500.000-700.000/năm pipeline từ kênh đó. Organic traffic giảm 35% tương đương $175.000-245.000 pipeline impact hàng năm, cộng với chi phí content creation investment tạo ra vấn đề.
Phòng ngừa: Content do AI tạo cần editorial layer thực sự trước khi publish. Không phải grammar check. Một original contribution layer: thêm expert opinion cụ thể, include original data, hoặc ví dụ cụ thể từ customer experience thực. Content không pass được test "bài này có chứa gì đó không tồn tại trong training data không?" chưa sẵn sàng publish. Hallucination risk theo pattern bao gồm technical condition làm AI content không đáng tin và pattern nào dễ bị confident error nhất.
Với technical knowledge base content, rủi ro thấp hơn vì accuracy quan trọng hơn originality. Với top-of-funnel blog content cạnh tranh keyword, AI-generated không có editorial là liability, không phải asset.
Mode Thất Bại 3: AI-driven churn từ output sai
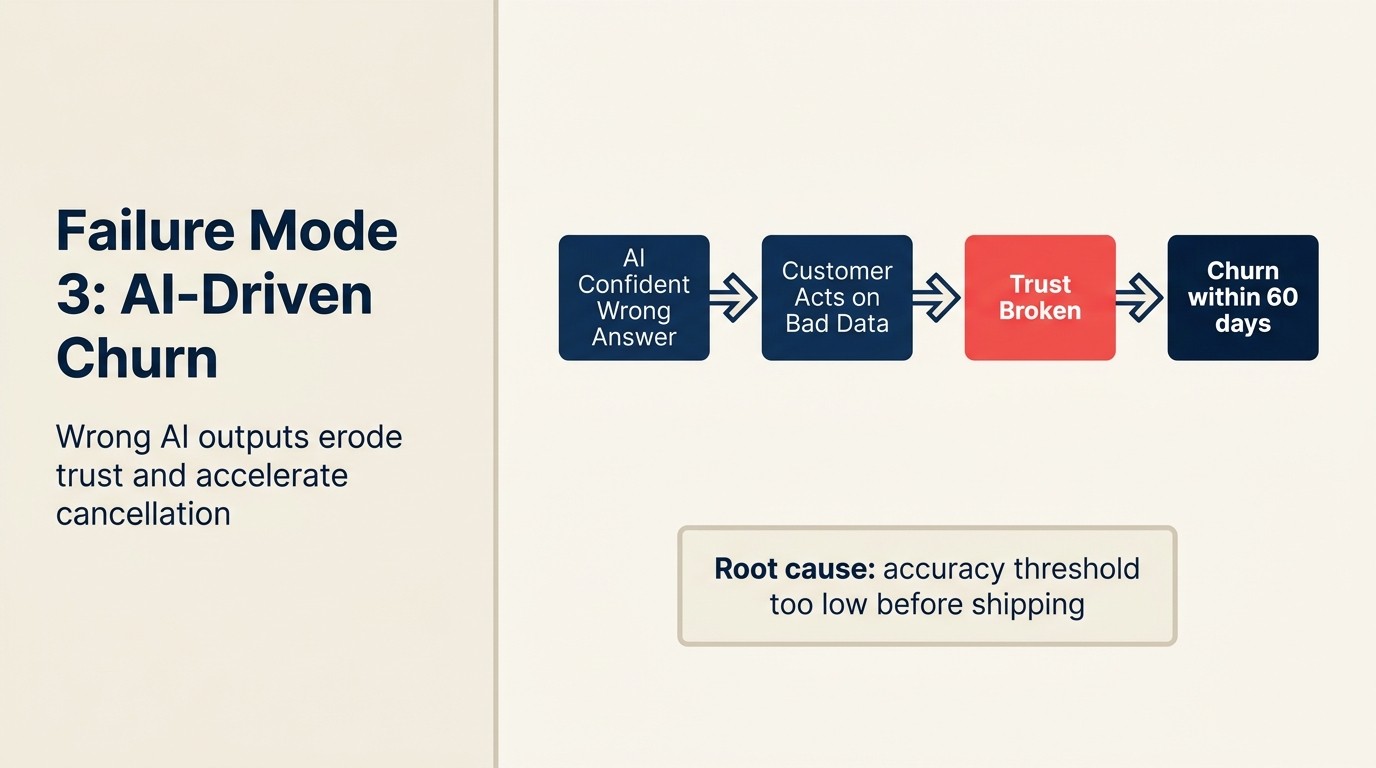
Một mid-market SaaS company deploy AI-powered onboarding flow để giảm time-to-value. AI recommend product section dựa trên use case người dùng khai khi sign up. Ba tháng đầu hoạt động tốt.
Rồi một batch enterprise signup kích hoạt bug trong segmentation logic. AI route 40 enterprise onboarding session đến workflow thiết kế cho small team. Những người dùng đó trải nghiệm onboarding không liên quan và gây nhầm lẫn. Support ticket tăng vọt. 11 trong 40 tài khoản yêu cầu refund hoặc không convert từ trial. Revenue impact: $180.000 ARR không close được.
Đây là AI-driven churn: AI output tích cực gây hại cho customer relationship thay vì giúp ích. Nó khác bug phần mềm thông thường vì harm không phải "tính năng không hoạt động." Mà là "AI đưa cho khách hàng thông tin sai hoặc experience sai, và khách hàng nghi ngờ liệu sản phẩm của bạn có hiểu use case của họ không."
Pattern thất bại lặp lại trong health scoring. CS tool AI gọi một enterprise account đang churn là "green" ba tháng. CSM tin vào score, không can thiệp với tần suất check-in thông thường. Account churn khi gia hạn. Postmortem cho thấy health score đang weight product usage cao hơn support ticket sentiment, và account vừa có usage cao vừa có frustration cao cùng lúc.
Phiên bản support chatbot: AI chatbot đưa câu trả lời sai về data export capability cho prospect trong trial, người đang evaluate product chính xác cho tính năng đó. Prospect chọn competitor. Không ai biết vì chatbot conversation không có ai review. McKinsey xác định risk concern và cost overrun là lý do chính AI initiative thất bại khi chuyển từ prototype sang production, và chỉ 10-20% isolated AI experiment trong hai năm qua thực sự scale lên tạo value.
Phòng ngừa: Mọi AI feature tạo customer-facing output đều cần human review gate cho high-stakes scenario. Không phải gate trên mọi output, mà gate xác định theo impact level. Low-stakes AI output (drafting suggestion, internal summary) có thể auto-apply. High-stakes output (onboarding routing, pricing quote, feature availability claim, health score alert kích hoạt thay đổi hành vi CSM) cần review mechanism trước khi ảnh hưởng đến khách hàng.
Xác định "high-stakes" rõ ràng trước khi deploy. Đó là product decision, không phải infrastructure decision. Generate vs. execute boundary giải thích nguyên tắc ACE Framework cho thời điểm AI output cần human approval trước khi execute.
Mode Thất Bại 4: Token-cost runaway
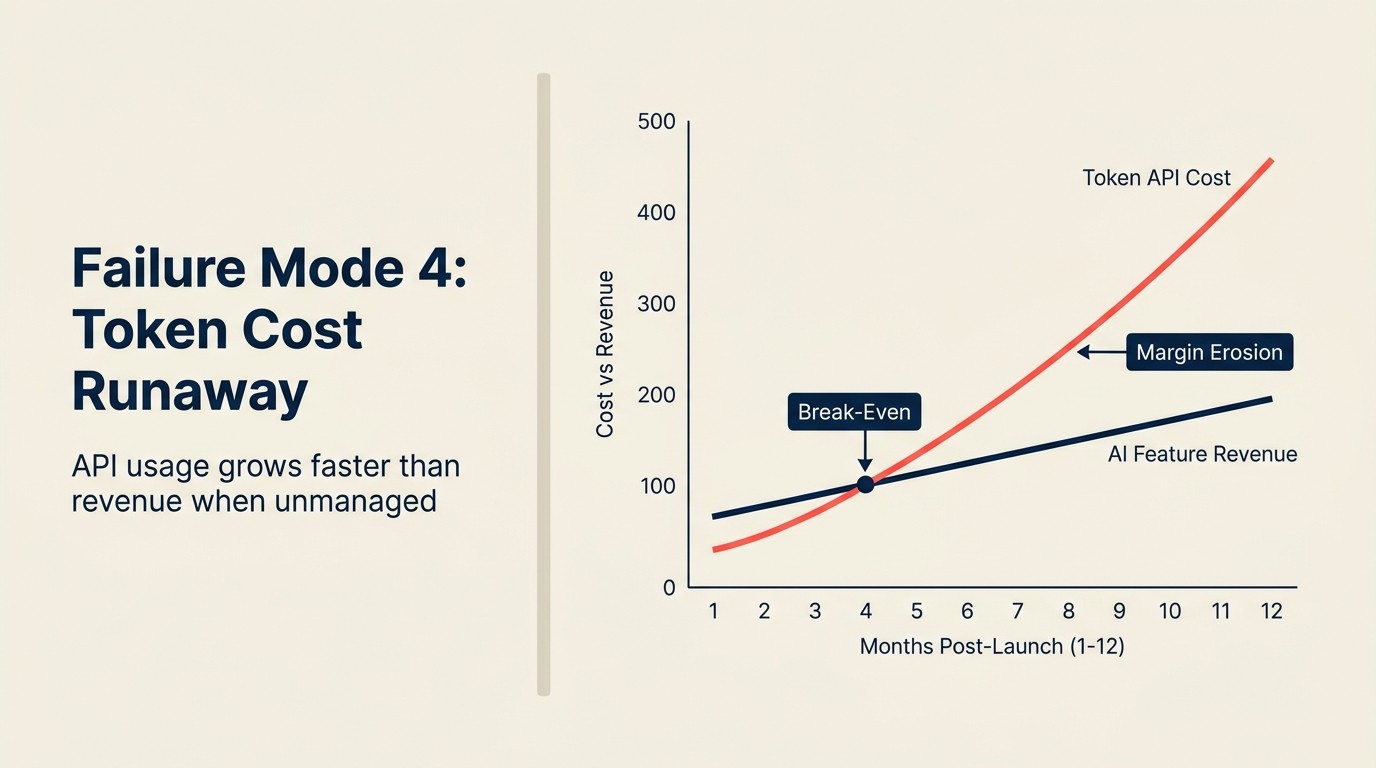
Một SaaS company ship AI writing assistant trong gói $49/tháng với AI generation không giới hạn. Internal testing cho thấy 95% người dùng generate 50-100 output mỗi tháng. Model nói API cost sẽ chạy ở $0,80-1,20 mỗi user mỗi tháng. Feature ship.
Sáu tháng sau, ba enterprise customer dùng sản phẩm cho large-scale content operation đang chạy 8.000-12.000 AI generation request mỗi tháng. Ở $0,80/request trung bình, đó là $6.400-9.600 mỗi customer mỗi tháng chi phí API, cho customer trả $49/tháng. Product team không model 99th percentile user. Họ model median user.
Tổng quarterly impact: ba customer tạo $72.000-84.000 API cost liability so với combined MRR (monthly recurring revenue) $441. Company đang trả tiền để những customer đó dùng sản phẩm.
Đây không phải giả thuyết. Pattern này xảy ra trong nhiều SaaS product trong 2023-2024 khi team price AI feature flat không có consumption architecture. Median-user model trông ổn. Power-user tail phá hủy unit economics.
Toán: OpenAI GPT-4o tính $2,50/M input token và $10/M output token. Một AI writing request với 3.000 token context và 800 token output tốn $0,0155. Rẻ mỗi request. Nhưng người dùng chạy 500 request mỗi ngày tốn $7,75/ngày, tức $232/tháng chi phí API. Nếu người dùng đó đang ở gói $99/tháng, bạn đang trả cho họ $133/tháng để dùng sản phẩm của bạn.
Phòng ngừa: Ba architecture decision bắt buộc trước khi ship bất kỳ AI feature nào trên flat-price plan:
- Per-user consumption limit theo tier: Free tier được 100 AI action/tháng. Starter được 500. Professional được 2.000. Enterprise negotiate custom. Hard limit, không phải soft limit.
- Usage monitoring với automatic alert: Khi bất kỳ account nào vượt 150% consumption đã model theo tier, hệ thống generate alert để review. Không chỉ vì lý do billing, mà vì anomalous usage pattern thường chỉ ra data quality problem hoặc user behavior dùng AI theo cách không dự định.
- Cost-based pricing cho enterprise: Enterprise customer với expected high usage nên ở consumption-based pricing hoặc tiered pricing với overage cost rõ ràng. Customer sẽ generate $2.000/tháng API cost không nên ở flat $500/tháng contract.
Mode Thất Bại 5: Tính năng AI bị đối thủ sao chép trong 30 ngày
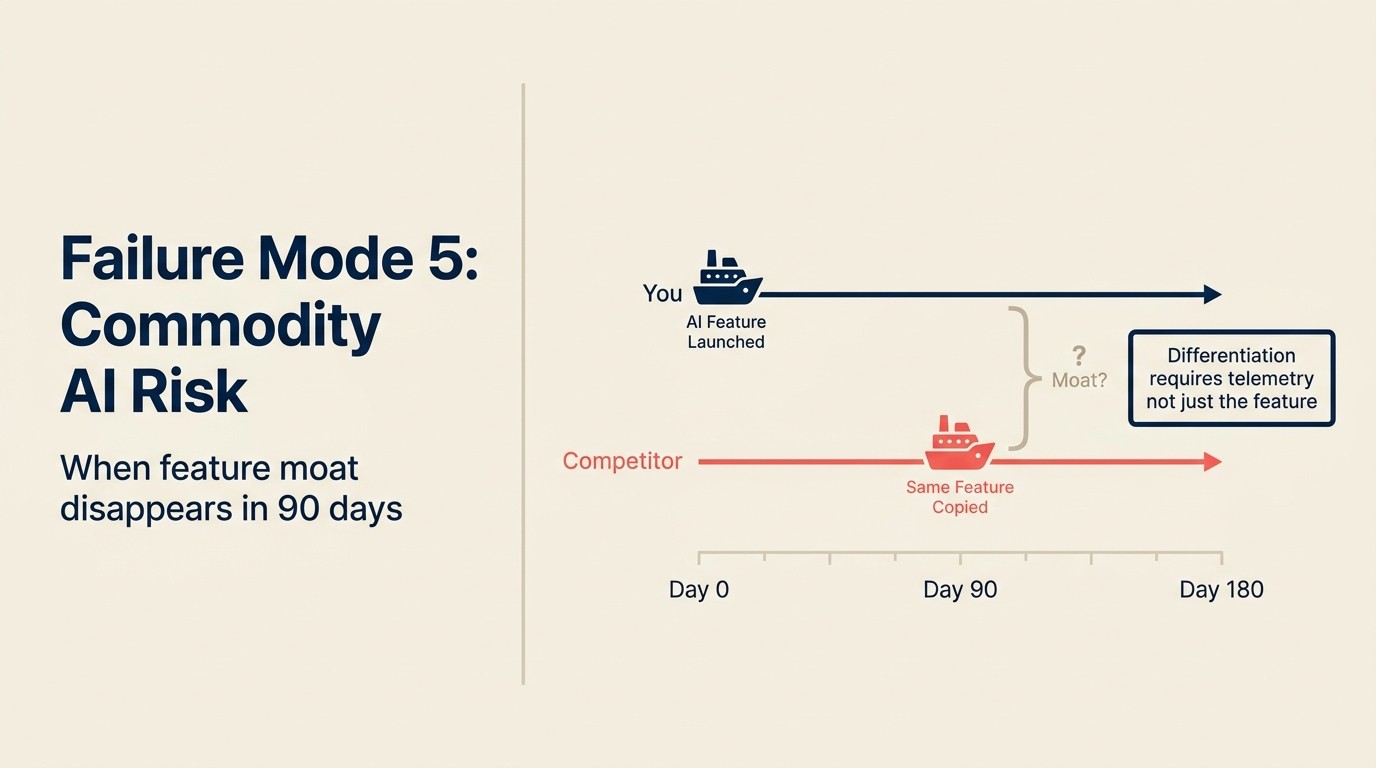
Một SaaS company ship AI contract summarization feature mà sales team dùng để tăng tốc deal review. Mất 4 tháng xây. Khi launch, đó là differentiator: không competitor nào có tính năng này in-product. Team market nó nổi bật.
Sáu tuần sau launch, hai competitor ship feature tương đương. Một wrap Claude trực tiếp. Một integrate third-party contract AI tool. Cả hai live trong 30 ngày của nhau. Competitive moat công ty xây trong 4 tháng có shelf life 8 tuần.
Đây là no-moat failure: ship AI feature tạo temporary differentiator nhưng không tạo structural advantage vì bất kỳ competitor nào có LLM API subscription và vài tuần engineering time đều có thể sao chép.
Hầu hết AI feature xây trên generic LLM API đều có thể sao chép trong 4-8 tuần bởi competing engineering team có năng lực. Sự khác biệt từ bản thân feature là thực nhưng tạm thời. Differentiation bền vững duy nhất là (a) data: phiên bản của bạn tốt hơn vì train trên actual user behavior, hoặc (b) integration depth: phiên bản của bạn nhúng sâu đến mức trong workflow rằng switching đòi hỏi relearn everything. Telemetry loop cho in-product AI giải thích cách xây data flywheel tạo option (a).
Chi phí: 4 tháng engineering để xây feature differentiate 8 tuần. Với $250.000/năm loaded engineering cost, đó là khoảng $83.000 đầu tư cho 2 tháng competitive differentiation. ROI math đòi hỏi 8 tuần differentiation đã drive win rate tốt hơn có ý nghĩa, thứ thường không đo được.
Phòng ngừa: Trước khi build bất kỳ AI feature nào mất hơn 6 tuần engineering, trả lời câu hỏi: "Trong 90 ngày, khi hai competitor đã ship equivalent functionality, điều gì làm phiên bản của chúng tôi tốt hơn có ý nghĩa?" Nếu câu trả lời không phải một trong số (data moat, integration depth, quality từ telemetry loop), bạn nên wrap feature nhanh hơn và rẻ hơn, hoặc đầu tư engineering time vào feature tạo durable moat.
Mode Thất Bại 6: Tính năng AI tạo gánh nặng support
Một SaaS company ship AI priority scoring feature cho project management tool. AI assign priority score cho task và surface top-priority item trong daily digest email. Nghe hữu ích và trong internal testing, team thích.
Trong production, 40% người dùng thấy AI priority suggestion sai cho context của họ. AI không hiểu định nghĩa priority của team, bị ảnh hưởng bởi deadline, stakeholder relationship và context không có trong task metadata. Người dùng bắt đầu tạo support ticket: "Tại sao AI nói X là high priority khi rõ ràng không phải?" Support team giờ dành thời gian giải thích AI behavior mà họ không hiểu đầy đủ.
Support ticket volume cho AI feature tháng đầu: 180 ticket. Support cost ở $12/ticket fully loaded: $2.160. Hàng tháng. Cho feature được cho là giảm cognitive load.
Thất bại compound: người dùng file AI support ticket có nhiều khả năng churn hơn người không file. Không phải vì AI feature thất bại, mà vì support interaction tạo ra narrative: "AI của sản phẩm này không hiểu context của tôi." Narrative đó gắn với sản phẩm, không chỉ feature.
Pattern tương tự xuất hiện trong CS AI tool. Health scoring system bắn 50 "at-risk" alert mỗi tuần, 60% hóa ra false positive sau CSM investigation. Sau bốn tuần, CSM bắt đầu bỏ qua alert không check. Khi real at-risk account xuất hiện trong queue, chúng bị bỏ qua cùng false positive. Bạn trả tiền cho health scoring system mà CS team đã mentally deprecated.
Phòng ngừa: Hai metric phải xanh trước khi bất kỳ AI-generated recommendation nào ship cho customer:
- Precision: Trong số các lần AI flag gì đó (at-risk, high priority, recommended action), bao nhiêu phần trăm đúng? Nếu precision dưới 70%, feature tạo nhiều noise hơn signal. Hầu hết người dùng sẽ học cách bỏ qua nó.
- Feedback loop để sửa lỗi: Người dùng cần nói được với AI nó sai, và feedback đó cần thực sự thay đổi hành vi AI. AI feature không có correction mechanism huấn luyện người dùng coi AI là black box không thể reason với. Nhận thức đó kill trust nhanh hơn bất kỳ wrong answer nào.
Phiên bản CS health scoring: đừng alert mọi account giảm xuống dưới ngưỡng. Alert account giảm unexpectedly so với recent trajectory. Ít alert hơn, precision cao hơn, CSM trust duy trì.
"Thất bại thầm lặng là mode chủ đạo trong SaaS AI. Sản phẩm ship, changelog ra, thông cáo báo chí nói 'chúng tôi đang đầu tư mạnh vào AI,' và sau đó không có gì rõ ràng xảy ra. AI feature log cho thấy 3% weekly active usage tháng thứ ba. Support chatbot bị enterprise customer tắt lặng lẽ sau khi bị wrong answer. AI health scoring system bị CSM bỏ qua vì quá nhiều false-positive alert." (Rework Analysis, 2025)
"Một in-product AI copilot feature điển hình mất 3-4 tháng engineering để xây đúng. Với blended engineering cost $250.000/năm, đó là $60.000-80.000 investment. Nếu 3% người dùng dùng nó và không ai trích dẫn nó là lý do gia hạn, team đốt $75.000 để thêm một dòng vào pricing page." (Rework Analysis, dựa trên Gartner GenAI project cost analysis, 2025)
"Support ticket volume cho AI feature dưới ngưỡng precision: 180 ticket mỗi tháng, ở $12/ticket fully loaded, là $2.160 mỗi tháng chi phí support cho feature được cho là giảm cognitive load. Thất bại compound: người dùng file AI support ticket có nhiều khả năng churn hơn, vì support interaction tạo product narrative gắn với toàn bộ sản phẩm." (Rework Analysis, 2025)
"Ba enterprise customer dùng flat-priced AI writing assistant chạy 8.000-12.000 generation request mỗi tháng, trả $49/tháng, tạo $72.000-84.000 API cost liability hàng quý so với combined MRR $441. Company đang trả tiền để những customer đó dùng sản phẩm. Đây không phải giả thuyết." (Rework Analysis, dựa trên OpenAI pricing và documented SaaS token-cost incident, 2025)
Checklist Phòng Ngừa Mode Thất Bại AI trong SaaS

| Mode Thất Bại | Early Warning Signal | Detection Window | Phòng Ngừa |
|---|---|---|---|
| Tính năng không ai dùng | 90-ngày WAU (weekly active users) dưới 10% | Ngày 30-60 | Validate insertion point trước khi build |
| Content AI làm hỏng SEO | Organic traffic giảm 3 tháng sau publish | 90-120 ngày | Original contribution layer trong mọi AI piece |
| Output sai dẫn đến churn | Support spike hoặc refund request từ AI-touched user | 30-90 ngày | Human review gate cho high-stakes AI output |
| Token-cost runaway | Monthly API cost vượt 50% plan revenue cho bất kỳ account nào | 30-60 ngày | Per-user consumption cap trước launch |
| No-moat feature match | Competitor ship equivalent trong 60 ngày | 6-12 tuần | Telemetry loop khi launch; integration depth |
| Support burden AI | Support ticket cho AI feature; CSM alert ignore rate trên 30% | 30-60 ngày | Precision threshold trên 70% trước khi ship |
Nguồn: Gartner GenAI Project Failure Analysis 2025, McKinsey AI Risk and Cost Research 2025, Gartner LLM Observability Predictions 2026
"Đến 2028, LLM observability investment sẽ đạt 50% generative AI deployment vì hallucination, bias và trust failure sẽ cần monitoring infrastructure mà hầu hết SaaS company chưa build hôm nay. Team bắt đầu instrumentation đó ngay bây giờ sẽ đi trước compliance và customer expectation curve." (Gartner, 2026)
Phân Tích Rework: Pattern qua tất cả sáu mode thất bại là measurement discipline, không phải technology sophistication. Mọi mode thất bại ở đây đều nhìn thấy trong data trước khi tốn kém, nếu bạn đang xem. Team deploy AI, tuyên bố chiến thắng dựa trên launch announcement, và không đo gì trong sáu tháng là team khám phá Mode 1 ở tháng 6 khi usage data kể câu chuyện mà changelog không nói. Failure-prevention checklist không phải optional governance. Đó là operational habit phân biệt AI investment tích lũy với AI investment giảm giá.
Phòng ngừa thất bại thực sự trông như thế nào
Pattern qua tất cả sáu mode thất bại là measurement discipline, không phải technology sophistication. Mọi mode thất bại ở đây đều nhìn thấy trong data trước khi tốn kém, nếu bạn đang xem.
Failure-prevention checklist trước khi deploy bất kỳ AI feature nào:
Baseline measurement đã có: Bạn biết metric feature này được cho là cải thiện, và bạn có pre-AI baseline được ghi lại. Nếu bạn deploy AI call coaching mà không ghi lại "good discovery quality" trông như thế nào trước AI, bạn không đo được nó có hoạt động không.
Adoption tracking đang live: Weekly active user, acceptance rate và modification rate đang trên dashboard ai đó review hàng tuần. 3% adoption ngày 30 còn phục hồi được. 3% adoption ngày 90 là feature bạn đang trả tiền để maintain.
Consumption guardrail đã build: Mọi AI feature trên flat-price plan đều có per-user limit và usage monitoring trước khi ship, không phải sau billing cycle bất thường đầu tiên.
Escalation path tồn tại: Mọi AI feature đụng đến customer-facing output đều có đường để customer escalate khi AI sai. Tốt hơn là, escalation đó được human xử lý, không phải AI khác.
Precision được đo và threshold: Với bất kỳ AI feature nào generate alert hoặc recommendation, precision được track. Feature không ship nếu không có minimum viable precision threshold được xác định và test.
Trust signal được track: Hàng tháng, kiểm tra người dùng engage với AI feature của bạn có NPS (Net Promoter Score) và churn rate cao hơn hay thấp hơn so với người không engage. Nếu AI feature engagement tương quan với churn cao hơn, bạn có trust problem, cần chẩn đoán trước khi feature scale.
SaaS AI failure sống sót được nếu phát hiện sớm. Sáu mode thất bại ở đây đều đo được trong 60-90 ngày đầu nếu bạn đang track đúng signal. Company gặp rắc rối nghiêm trọng là company deploy AI, tuyên bố chiến thắng dựa trên launch announcement, và không đo gì trong sáu tháng. Gartner dự đoán đến 2028, LLM observability investment sẽ đạt 50% generative AI deployment vì hallucination, bias và trust failure sẽ cần monitoring infrastructure mà hầu hết SaaS company chưa build hôm nay, và team bắt đầu instrumentation sớm sẽ đi trước compliance và customer expectation curve.
Đừng tuyên bố chiến thắng trước khi telemetry chứng minh.
Tìm Hiểu Thêm:
- Tại Sao Hầu Hết Chuyển Đổi AI Thất Bại: strategy-level failure pattern tạo điều kiện cho cả sáu mode
- Hallucination Risk theo Pattern: technical condition tạo ra confident AI error theo loại pattern
- Generate vs. Execute Boundary: nguyên tắc ACE Framework cho thời điểm AI cần human approval trước khi act
- AI Anti-Patterns: broader pattern-level failure catalog bổ sung cho SaaS-specific failure mode
- Telemetry Loop cho In-Product AI: measurement infrastructure phát hiện failure ngày 30, không phải tháng 6
- AI Arms Race trong SaaS: Tốc Độ Ship: competitive pressure tạo điều kiện ship không có quality gate
- Các Giai Đoạn Trưởng Thành AI trong SaaS: nơi các failure mode tập trung theo maturity stage
- Tại Sao AI Framework Thất Bại: foundational failure pattern mà SaaS AI failure thường trace về

Co-Founder, Rework.com
On this page
- 6 Mode Thất Bại AI trong SaaS
- Mode Thất Bại 1: Tính năng AI khách hàng không dùng
- Mode Thất Bại 2: Content do AI tạo làm hỏng SEO
- Mode Thất Bại 3: AI-driven churn từ output sai
- Mode Thất Bại 4: Token-cost runaway
- Mode Thất Bại 5: Tính năng AI bị đối thủ sao chép trong 30 ngày
- Mode Thất Bại 6: Tính năng AI tạo gánh nặng support
- Checklist Phòng Ngừa Mode Thất Bại AI trong SaaS
- Phòng ngừa thất bại thực sự trông như thế nào