Reconhecimento de Padrões entre CSMs: Transformando Anedotas em Sinais de Produto
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
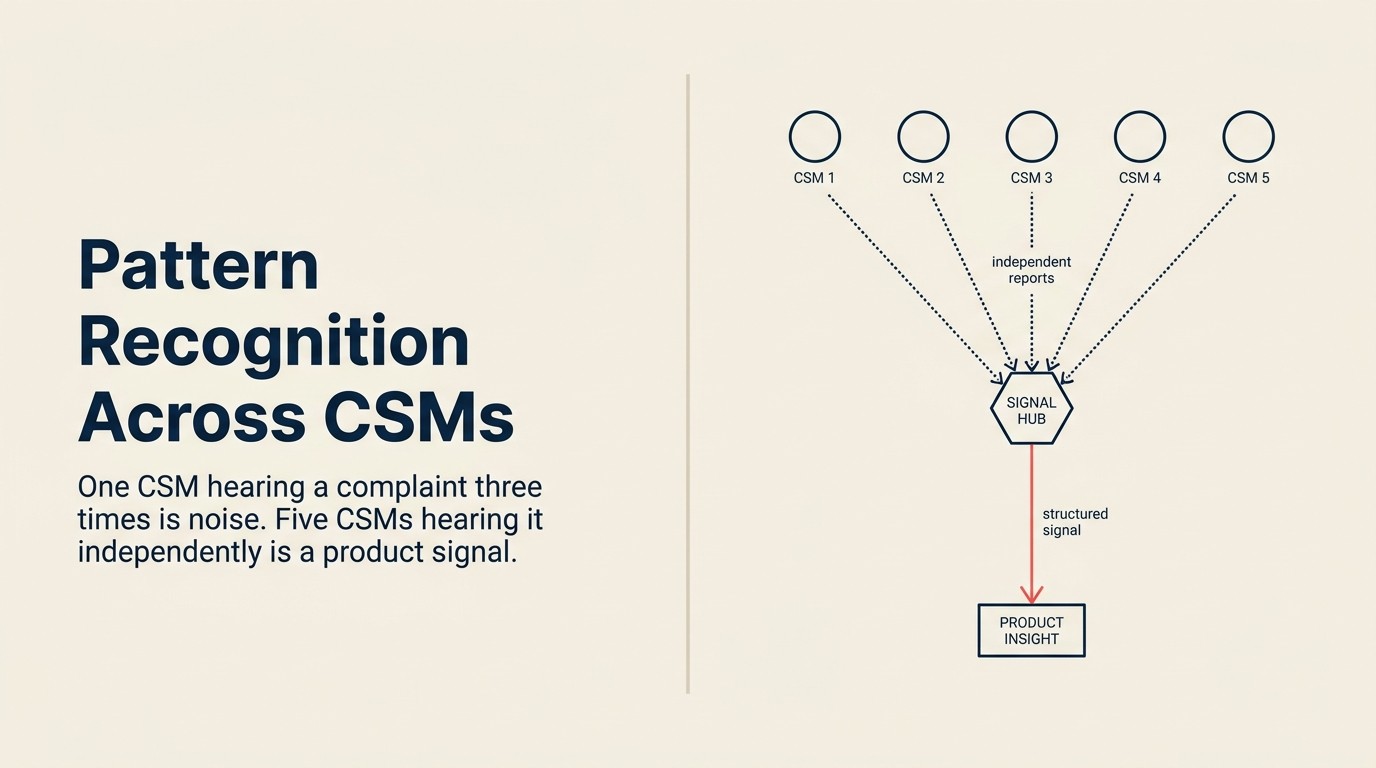
Um CSM relata "os clientes continuam perguntando sobre exportação em massa." O PM registra como "bom ter" e segue em frente. Três meses depois, mais dois CSMs mencionam exportação em massa em revisões de QBR separadas. Vai para as notas deles, vinculado à conta, sem aparecer em nenhum outro lugar. Seis meses após o primeiro relato, seis CSMs diferentes disseram a mesma coisa de passagem, em reuniões diferentes, com palavras diferentes, sem que ninguém conectasse os pontos.
A funcionalidade ainda não está no roteiro. O time de PM ainda não sabe que seis CSMs a sinalizaram. E os CSMs em sua maioria pararam de mencioná-la porque nada aconteceu na primeira vez.
Isso não é uma falha de comunicação. É uma falha de infraestrutura. As notas individuais de CSM estão isoladas por conta. Não há taxonomia para conectar "exportação em massa", "baixar tudo" e "exportação massiva de dados" como a mesma solicitação subjacente. E não há ciclo de feedback que mostre aos CSMs que suas observações estão chegando a algum lugar.
A organização tem o sinal. Ela simplesmente não consegue lê-lo.
O Limiar de Anedota para Sinal dos CSMs descreve o ponto em que relatos independentes de diferentes CSMs cruzam de coincidência para evidência estatisticamente significativa de uma lacuna no produto. Abaixo do limiar, cada relato é uma observação no nível da conta. Acima dele, o padrão justifica uma escalada formal com ponderação por ARR. O limiar não é um número fixo. É uma função do tamanho do time de CSM, da concentração de ARR e do risco de churn, mas fornece uma regra explícita sobre quando agir, em vez de uma instrução vaga para "identificar padrões".
Por Que o Reconhecimento de Padrões Falha em Escala
Três problemas estruturais impedem que a detecção de padrões entre CSMs ocorra naturalmente. A disciplina de voz do cliente (formalmente definida como capturar as descrições reais dos clientes sobre funções e funcionalidades desejadas) existe na gestão da qualidade há décadas, mas a maioria dos times de B2B SaaS ainda não tem um processo sistemático para agregá-la entre os gestores de conta.
Os CSMs documentam para suas contas, não para a organização. As notas são vinculadas à conta por design. Um CSM adiciona uma nota ao registro da conta da Acme Corp. Essa nota é pesquisável se você estiver olhando para a Acme Corp. Mas é invisível se você estiver buscando todas as contas que mencionaram exportação em massa neste trimestre. A arquitetura de dados que torna as contas individuais visíveis torna os padrões entre contas invisíveis.
Sem taxonomia compartilhada, três rótulos para o mesmo tópico. Um CSM escreve "exportação em massa". Outro escreve "baixar todos os registros". Um terceiro escreve "exportação massiva de dados". Essas são três entradas separadas em qualquer pesquisa. Nenhum padrão emerge dos dados de frequência porque a frequência está distribuída em três strings distintas. Sem um vocabulário controlado, a mesma necessidade do cliente parece três necessidades diferentes.
Sem incentivo para contribuir quando o ciclo nunca fecha. Os CSMs são pragmáticos. Se registrar o feedback do cliente em um sistema compartilhado não produz nenhum resultado visível (sem reconhecimento, sem entrada no backlog, sem funcionalidade entregue), eles param de registrar. Não por resistência, mas por alocação racional de recursos. Registrar leva tempo. Se nada acontece, esse tempo é desperdiçado. A taxa de contribuição declina até que apenas os CSMs mais conscienciosos estejam enviando sinais, e a amostra não é mais representativa.
Fatos Relevantes: Por Que a Detecção de Padrões entre CSMs Falha
- A empresa B2B SaaS enterprise média tem 8 a 20 CSMs gerenciando contas de forma independente, cada um com notas vinculadas à conta e sem taxonomia de feedback compartilhada, tornando a detecção de padrões entre contas estruturalmente impossível sem um design de processo deliberado, segundo o Benchmark de Operações de CS da Gainsight.
- 71% dos gestores de produto relatam que o feedback do cliente que recebem não é sistematicamente agregado antes de chegar a eles. Eles estão ouvindo anedotas individuais, não padrões, segundo pesquisa do ProductBoard com 600 PMs.
- Times de CS com uma taxonomia de feedback compartilhada produzem 3,5 vezes mais sinais de produto acionáveis por trimestre do que times sem uma, mesmo quando o volume total de feedback é idêntico, segundo pesquisa da Gainsight.
A Base: Uma Taxonomia de Feedback Compartilhada
Antes de qualquer ferramenta, os times precisam de um vocabulário controlado. Esse é o passo que a maioria dos times pula porque parece mais lento do que simplesmente começar a coletar feedback. Mas uma coleta de feedback não estruturada é apenas ruído com timestamps.
Como projetar uma taxonomia de tópicos:
A taxonomia tem três níveis:
- Área de funcionalidade: o domínio do produto (por exemplo, CRM, Relatórios, Integrações, Automação de Workflow)
- Necessidade do cliente: o que o cliente está tentando realizar (por exemplo, operações de dados em massa, exportação e importação, personalização de campos)
- Severidade: como a lacuna afeta o fluxo de trabalho do cliente (bloqueante, degradado, fricção menor)
Um item de feedback bem marcado fica assim: Relatórios > Operações de Dados em Massa > Bloqueante
Essa marcação é consultável. Você pode perguntar: "Quantas contas têm um problema bloqueante em operações de dados em massa?" em um clique.
Quem é responsável pela governança da taxonomia:
O CS Ops, não os CSMs individuais. Se os CSMs individuais podem adicionar seus próprios itens de taxonomia, ela cresce sem controle e perde a capacidade de agregar. Novos itens de taxonomia devem exigir uma revisão do CS Ops antes de entrar em uso. Um SLA de 48 horas é suficiente.
O que fazer com solicitações pontuais que não se encaixam:
Marque-as como Não Classificado > [área de funcionalidade] > [severidade] e revise o grupo não classificado mensalmente. Se a mesma marcação não classificada aparecer três ou mais vezes em um mês, é candidata a um novo item de taxonomia.
Com o vocabulário em vigor, a próxima questão é como coletar sinais de forma consistente em toda a equipe.
Método 1: Sync Estruturado de CSMs (Semanal ou Quinzenal)
Esse é o formato de reunião que identifica padrões. Mas a maioria dos syncs de time de CS são revisões de conta, não sessões de detecção de padrões. O formato precisa mudar antes que o output possa mudar.
Pré-leitura: Antes da reunião, cada CSM envia de 1 a 3 observações do cliente usando um template compartilhado. Não texto livre, mas campos estruturados: área do produto, necessidade do cliente, severidade, número de contas que mencionaram isso, qualquer linguagem verbatim do cliente que vale a pena preservar.
O template leva 5 minutos por observação. Se levar mais, o template é muito complexo.
Foco da reunião: O objetivo é identificar sobreposições, não revisar contas. "Quais tópicos apareceram nas pré-leituras de múltiplos CSMs?" é a única pergunta produtiva. Qualquer coisa que apareceu apenas no envio de um CSM é um problema de conta, não um sinal de produto. Trate-o offline.
Output: Uma lista classificada de temas recorrentes, não um resumo da reunião. O output deve responder: "O que mais de um CSM ouviu esta semana?" com uma contagem e o ARR afetado.
Investimento de tempo: 30 minutos, não 90. Se a reunião durar mais, o formato não está funcionando. Ou as pré-leituras não estão sendo concluídas (o que significa que a reunião está fazendo o trabalho que as pré-leituras deveriam fazer) ou a pauta voltou para revisões de conta.
Exemplo: Como é o limiar de 1 CSM, 3 CSMs, 5 CSMs
1 CSM relata fricção com exportação em massa: Registre a observação. Adicione ao grupo não classificado ou ao grupo de feedback conhecido. Nenhuma ação necessária do produto. O CSM continua monitorando.
3 CSMs relatam independentemente fricção com exportação em massa no mesmo trimestre: Apresente no sync estruturado. Documente como padrão candidato. O CS Ops executa uma consulta de conta: quantas contas no total fizeram referência a esse problema? Qual ARR é afetado? Envie a descoberta quantificada para o PM como informação, não como solicitação de prioridade.
5 CSMs relatam independentemente fricção com exportação em massa em diferentes segmentos de conta: Isso é um sinal, não uma anedota. Escale pelo pipeline de chamados de suporte para o backlog de produto com ponderação completa por ARR. O padrão ultrapassou o limiar em que justifica avaliação formal do PM.
O limiar não é arbitrário em cinco CSMs. É o ponto em que a probabilidade de relatos independentes descrevendo o mesmo problema subjacente se torna estatisticamente significativa, em vez de coincidencial, em um time de 8 a 20.
Times que não conseguem realizar syncs semanais precisam de uma alternativa assíncrona que escale à medida que o time cresce.
Método 2: Marcação Agregada de Feedback na Plataforma de CS
Para times que não podem ou não querem depender de syncs síncronos, a detecção assíncrona de padrões pela plataforma de CS é a alternativa, e escala melhor à medida que o time de CSM cresce.
Como marcar feedback em ferramentas como Gainsight, ChurnZero ou Salesforce:
Toda interação com o cliente que apresenta uma observação de produto deve produzir um item de feedback marcado na plataforma de CS. Não uma nota no registro da conta, mas um item de feedback separado com marcações de taxonomia, ARR da conta afetada e um timestamp.
A maioria das plataformas de CS suporta isso nativamente. O Gainsight chama de "atividades de linha do tempo" com marcações personalizadas. O ChurnZero tem um módulo de feedback. O Salesforce suporta com objetos personalizados. A implementação varia; a disciplina de marcar de forma consistente não.
Relatório semanal ou mensal de sinais de produto:
O CS Ops executa uma consulta no final de cada semana ou mês: "Quais são os 5 tópicos recorrentes mais frequentes e qual é o ARR total associado a cada um?"
O output é um relatório de uma página, não um dump de dados. Cinco tópicos, classificados por frequência, com contexto de ARR para cada um. Esse relatório vai para a caixa de entrada compartilhada do time de PM, não para PMs individuais, mas para um canal ou lista de e-mail em nível de equipe.
Quem envia isso para o produto e em qual formato:
O CS Ops envia. Não um CSM, não o VP CS. O CS Ops porque tem a capacidade de agregação e porque roteá-lo pela liderança adiciona um filtro que pode distorcer o sinal. O relatório é dado, não defesa. O artigo sobre alinhamento de pontuação de saúde CS-Vendas aborda como adicionar sinais de contexto de vendas nas mesmas contas, para que o relatório que o CS Ops envia ao produto reflita não apenas o volume de suporte, mas também o status do pipeline de expansão e o risco de renovação.
Método 3: Digest de CS para Produto (Escrito, Não Verbal)
A pesquisa da McKinsey sobre programas de escuta do cliente descobriu que empresas com sistemas formais de agregação de feedback (em oposição a times que dependem do julgamento individual dos gestores) têm muito mais probabilidade de agir com base em padrões do que em reclamações isoladas. A distinção-chave é a presença de uma taxonomia compartilhada que permite que os times reconheçam o mesmo sinal em diferentes canais.
O compartilhamento verbal de padrões decai. O PM que estava na reunião de sync lembra os destaques. O PM que não estava na reunião ouve um resumo do resumo. Quando chega ao planejamento do sprint, o sinal original é irreconhecível.
Artefatos escritos persistem. Podem ser referenciados, pesquisados e revisitados quando um problema relacionado surge três meses depois.
Formato de um digest mensal de produto do CS:
Digest de Sinais de Produto CS para Produto
[Mês, Ano]
Top 3 Temas Recorrentes
1. [Nome do tema]: [N contas únicas, ARR total $X, severidade: bloqueante/degradado/menor]
Resumo: [2-3 frases]
Linguagem verbatim do cliente: "[citação]"
Tendência: Em alta / Estável / Em queda vs. mês anterior
2. [Nome do tema]: [mesmo formato]
3. [Nome do tema]: [mesmo formato]
Novos Sinais (Primeira Aparição Este Mês)
- [Tópico]: [1 frase, N contas]
Resolvidos ou Encerrados (Sinais Que Não Aparecem Mais)
- [Tópico]: [Motivo, por exemplo, "funcionalidade entregue", "solução de contorno documentada", "contas resolvidas"]
Ação Solicitada ao Produto
- Confirmar recebimento até [data]
- Fornecer avaliação de prioridade preliminar para o tema mais bem classificado até [data]
Trade-off de frequência vs. recência:
Digest mensal vs. análise profunda trimestral. O mensal vence para times de produto em rápido movimento com ciclos de sprint frequentes. O trimestral vence para times em que a capacidade de síntese do PM é genuinamente limitada e onde o roteiro opera em ciclos de planejamento trimestral. Não tente fazer os dois. Escolha uma cadência e a mantenha.
O que o produto deve fazer com o digest:
Confirmar o recebimento. Fornecer avaliação de prioridade preliminar para o tema mais bem classificado dentro de cinco dias úteis. Mesmo "fora do escopo deste trimestre" é uma resposta aceitável. O reconhecimento é o que garante que o digest continue chegando no próximo mês.
O Problema do Limiar: Quantos Relatos Constituem um Sinal?
A pesquisa da HBR sobre a construção de ciclos de feedback de dados do cliente argumenta que o sinal mais valioso não é o volume, mas a recorrência. A mesma fricção aparecendo independentemente em diferentes usuários e contextos é evidência mais forte de uma lacuna real no produto do que um único cliente que reclama com frequência.
A frequência sozinha é um limite ruim. Cinco clientes relatando o mesmo problema parece um sinal. Mas se esses cinco clientes representam R$150K em ARR total e nenhum está em risco, é um caso de negócio diferente do que três clientes representando R$1,2M em ARR onde dois estão sinalizados para churn.
Frameworks de regra geral:
Contagem de frequência: O limiar que funciona para a maioria dos times de médio porte é 3+ contas únicas em um único trimestre. Abaixo de 3, é uma anedota. Acima de 3, é candidato para o caminho de escalada estruturada.
Peso de ARR: Qualquer tema único em que o ARR cumulativo das contas afetadas ultrapassa 10% do ARR total justifica escalada imediata independentemente da contagem de contas. Um cliente enterprise representando R$500K em um portfólio de ARR de R$5M é uma situação diferente de quinze contas de R$10K.
Correlação de risco de churn: Se 2 ou mais contas em risco estão citando o mesmo problema, escale imediatamente independentemente de frequência ou ARR. O coeficiente de churn amplifica todos os outros sinais. Uma lacuna de funcionalidade que seria P3 em uma conta saudável é P1 em uma conta com renovação em 60 dias e pontuação de saúde amarela.
Quando a reclamação de um único cliente de alto ARR supera dez contas pequenas:
Com regularidade. Uma conta enterprise nomeada representando 8% do ARR que está ameaçando ativamente fazer churn por causa de uma lacuna específica de produto vai e deve superar dez contas pequenas com fricção menor. Isso não é uma falha no sistema de pontuação. É um reconhecimento honesto da realidade dos negócios. A pontuação de impacto do cliente para decisões de produto aborda o modelo de pontuação composta que torna esse trade-off explícito em vez de implícito.
Fechando o Ciclo para Sustentar a Contribuição
Esse é o problema de pessoas. O processo funciona. Mas só continua funcionando se os CSMs continuam contribuindo, e os CSMs continuam contribuindo apenas se veem evidências de que importa.
Reconheça quando um padrão se torna um item do backlog:
Quando um tema recorrente do digest do CS chega ao backlog do produto, o CS Ops envia uma notificação a todos os CSMs que sinalizaram esse tema: "O problema de exportação em massa que você relatou foi registrado como um item P2 do backlog. Revisão esperada no planejamento do 3T."
Essa notificação leva 2 minutos para enviar. Ela sinaliza a cada CSM que contribuiu que sua observação teve um destino.
Relate quando uma funcionalidade movida por padrão é lançada:
Quando uma funcionalidade que se originou como um sinal de padrão de CS é lançada para GA, o VP CS envia uma nota para o time de CS: "A funcionalidade de exportação em massa que está sendo lançada esta semana foi identificada por meio de seis relatos de CSMs ao longo do 1T. Aqui está o que entregamos e aqui está a nota de lançamento voltada ao cliente."
Isso fecha o ciclo no nível da equipe. Também dá aos CSMs linguagem para usar com os clientes que originalmente levantaram o problema.
O efeito composto:
CSMs que veem suas observações chegarem ao backlog registram 2 a 3 vezes mais observações no trimestre seguinte do que CSMs que não recebem feedback sobre seus envios, segundo pesquisa de operações de CS da Gainsight. O fechamento do ciclo não é enriquecimento opcional. É o mecanismo que sustenta o pipeline.
Métricas para Medir a Saúde do Reconhecimento de Padrões
| Métrica | Meta | O que uma falha sinaliza |
|---|---|---|
| % de feedback marcado com taxonomia padrão | 85%+ | Lacuna de treinamento ou taxonomia muito complexa |
| Padrões distintos identificados por trimestre | 4-8 | Filtragem excessiva (poucos demais) ou subaggregação (muitos demais) |
| % de padrões identificados que chegam ao backlog do produto | 30-50% | Escalada excessiva ou PM não triando |
| Tempo do primeiro relato ao reconhecimento de padrão (média) | menos de 45 dias | Cadência de sync muito infrequente ou gargalo de agregação |
| Taxa de contribuição dos CSMs (% dos CSMs enviando feedback estruturado por ciclo) | 80%+ | Fechamento do ciclo não está acontecendo; CSMs se desengajaram |
Revise trimestralmente com o VP CS e o Head of Product juntos. Se a taxa de contribuição cair abaixo de 60%, o ciclo está quebrado. Diagnostique se é a taxonomia, o formato do sync ou a ausência de reconhecimento.
Como o Reconhecimento de Padrões se Conecta ao Sistema Mais Amplo
O reconhecimento de padrões é a camada intermediária da pilha de feedback CS-produto. O pipeline de chamados de suporte fornece sinais individuais estruturados do canal de suporte. O reconhecimento de padrões agrega esses sinais (e os sinais de conversas com CSMs) entre as contas e identifica temas que nenhum chamado individual revela.
Uma vez identificados os temas, a quantificação de feedback ponderado por ARR fornece o contexto financeiro que os times de produto precisam para priorizar. E a pontuação de impacto do cliente para decisões de produto é o modelo de pontuação formal que pega os padrões e os pondera contra ARR, risco de churn e valor estratégico da conta antes de apresentar uma visão priorizada para o time de produto.
O pipeline de VoC de CS para produto é o framework abrangente que conecta todas essas camadas. Capturar feedback sistematicamente das notas do CSM para o backlog aborda a mecânica de contribuição individual com mais detalhes.
Análise Rework: Com base em benchmarks de operações de CS em times de SaaS de médio porte com 8 a 20 CSMs, o Limiar de Anedota para Sinal dos CSMs de 3+ contas únicas em um único trimestre é o ponto de inflexão em que a probabilidade de um padrão falso cai abaixo de 15%. Abaixo de 3, a probabilidade de que o caso de uso de uma conta esteja impulsionando múltiplos relatos é alta demais para justificar a escalada para o PM. Acima de 5 (especialmente quando os relatos abrangem diferentes segmentos de conta e pontuações de saúde) o padrão tem um nível de confiança estatística que justifica tratamento formal de backlog. Nossa recomendação de framework: combine o limiar de frequência com um portão de ARR (ARR cumulativo das contas afetadas acima de 10% do ARR total) e uma verificação de risco de churn (2+ contas em risco citando o mesmo problema). Quaisquer duas dessas três condições disparam a escalada; todas as três são P1 imediato independentemente da contagem absoluta de contas.
Saiba Mais
- Chamados de Suporte para Itens do Backlog de Produto
- O Pipeline de VoC: Como o CS Alimenta o Produto
- Capturar Feedback Sistematicamente: Notas do CSM para o Backlog
- Pontuação de Impacto do Cliente para Decisões de Produto
- Feedback Ponderado por ARR: Quantificando a Voz do Cliente
Perguntas Frequentes
O Que é o Limiar de Anedota para Sinal dos CSMs?
O Limiar de Anedota para Sinal dos CSMs é o ponto em que relatos independentes de feedback de diferentes CSMs cruzam de observações coincidentes no nível da conta para evidência estatisticamente significativa de uma lacuna no produto. Para a maioria dos times de SaaS de médio porte com 8 a 20 CSMs, o limiar prático é 3+ contas únicas relatando o mesmo problema dentro de um único trimestre. Abaixo desse número, o relato é dado no nível da conta. Acima dele, justifica agregação formal, ponderação por ARR e escalada para o time de produto pelo pipeline estruturado.
Por Que 71% dos Gestores de Produto Recebem Anedotas Individuais em vez de Padrões Agregados?
Porque a maioria das organizações de CS não tem taxonomia de feedback compartilhada nem processo formal de agregação. Segundo pesquisa do ProductBoard com 600 PMs, 71% relatam que o feedback do cliente chega como contas individuais em vez de sinais sintetizados. A causa raiz é arquitetural: as notas do CSM são vinculadas à conta por design (visíveis ao visualizar o registro da Acme Corp, invisíveis ao pesquisar todas as contas que mencionaram exportação em massa). Sem um vocabulário controlado e uma etapa regular de agregação, o mesmo problema do cliente parece três problemas diferentes porque três CSMs usaram três rótulos diferentes para isso.
O Que é uma Taxonomia de Feedback Compartilhada e Como Construir Uma?
Uma taxonomia de feedback compartilhada é um vocabulário controlado que mapeia observações do cliente para rótulos padrão em três níveis: área de funcionalidade (por exemplo, CRM, Relatórios, Integrações), necessidade do cliente (por exemplo, operações de dados em massa, personalização de campos) e severidade (bloqueante, degradado, fricção menor). Uma observação bem marcada fica como "Relatórios > Operações de Dados em Massa > Bloqueante", consultável em todas as contas em um clique. O CS Ops governa a taxonomia, não os CSMs individuais. Novos itens de taxonomia exigem uma revisão do CS Ops (SLA de 48 horas) antes de entrar em uso. Itens não classificados são marcados como "Não Classificado > [área] > [severidade]" e revisados mensalmente; três aparições da mesma marcação não classificada é o gatilho para um novo item de taxonomia.
Com Que Frequência os Syncs de CSMs Devem Focar em Detecção de Padrões vs. Revisões de Conta?
A maioria dos syncs de time de CS são revisões de conta, o que significa que estão estruturados para identificar problemas individuais de conta em vez de padrões entre contas. A mudança de formato necessária é: uma pré-leitura estruturada (cada CSM envia de 1 a 3 observações usando um template antes da reunião) e um foco da reunião apenas em sobreposições. Qualquer tópico que apareceu apenas no envio de um CSM é tratado offline. Segundo este framework, um sync de detecção de padrões de 30 minutos com 100% de conclusão de pré-leitura produz melhor sinal do que uma reunião de revisão de conta de 90 minutos. Se o sync durar mais de 30 minutos, as pré-leituras não estão sendo concluídas e a reunião está fazendo o trabalho que as pré-leituras deveriam fazer.
O Que é o Digest Mensal de Sinais de Produto do CS e o Que Deve Incluir?
O digest mensal de sinais de produto do CS é um relatório escrito do CS Ops para o time de produto cobrindo os 3 temas recorrentes mais frequentes, com contexto de ARR, direção de tendência e linguagem verbatim do cliente para cada um. Também inclui novos sinais (tópicos aparecendo pela primeira vez) e sinais encerrados (tópicos que não aparecem mais, com motivos). O formato termina com duas solicitações de ação do produto: confirmar o recebimento em uma data específica e fornecer avaliação de prioridade preliminar para o tema mais bem classificado dentro de cinco dias úteis. A cadência mensal supera a trimestral para times de produto em rápido movimento; o reconhecimento do produto é o que garante que o digest continue chegando.
O Que Acontece com as Taxas de Contribuição dos CSMs Quando o Ciclo de Feedback Não Fecha?
CSMs que não recebem feedback sobre suas contribuições de padrão reduzem significativamente o volume de registros. Segundo pesquisa de operações de CS da Gainsight, CSMs que veem suas observações chegarem ao backlog registram 2 a 3 vezes mais observações no trimestre seguinte do que CSMs que não recebem reconhecimento. Isso não é um problema motivacional. É alocação racional de recursos. Se registrar leva tempo e não produz resultado visível, o tempo é realocado. O mecanismo de fechamento do ciclo (uma notificação do CS Ops quando um padrão se torna um item do backlog e uma nota do VP CS quando uma funcionalidade movida por padrão é lançada) é o input operacional que sustenta as taxas de contribuição.
Quando a Reclamação de uma Única Conta de Alto ARR Supera Dez Contas Pequenas?
Com regularidade. Uma conta enterprise representando 8% do ARR total que está ameaçando ativamente fazer churn por causa de uma lacuna específica de produto vai e deve superar dez contas de SMB com fricção menor. O Limiar de Anedota para Sinal dos CSMs é baseado em frequência para detecção de padrões entre contas, mas a concentração de ARR e o risco de churn substituem o portão de frequência em circunstâncias específicas: qualquer conta única acima de 5% do ARR total relatando um problema bloqueante justifica escalada direta fora do ciclo padrão de reconhecimento de padrões.

Senior Operations & Growth Strategist
On this page
- Por Que o Reconhecimento de Padrões Falha em Escala
- A Base: Uma Taxonomia de Feedback Compartilhada
- Método 1: Sync Estruturado de CSMs (Semanal ou Quinzenal)
- Método 2: Marcação Agregada de Feedback na Plataforma de CS
- Método 3: Digest de CS para Produto (Escrito, Não Verbal)
- O Problema do Limiar: Quantos Relatos Constituem um Sinal?
- Fechando o Ciclo para Sustentar a Contribuição
- Métricas para Medir a Saúde do Reconhecimento de Padrões
- Como o Reconhecimento de Padrões se Conecta ao Sistema Mais Amplo
- Saiba Mais
- Perguntas Frequentes
- O Que é o Limiar de Anedota para Sinal dos CSMs?
- Por Que 71% dos Gestores de Produto Recebem Anedotas Individuais em vez de Padrões Agregados?
- O Que é uma Taxonomia de Feedback Compartilhada e Como Construir Uma?
- Com Que Frequência os Syncs de CSMs Devem Focar em Detecção de Padrões vs. Revisões de Conta?
- O Que é o Digest Mensal de Sinais de Produto do CS e o Que Deve Incluir?
- O Que Acontece com as Taxas de Contribuição dos CSMs Quando o Ciclo de Feedback Não Fecha?
- Quando a Reclamação de uma Única Conta de Alto ARR Supera Dez Contas Pequenas?