SaaSヘルプデスクにおけるマルチティアAIルーティング
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
従来のヘルプデスク割り当てモデルはラウンドロビンまたは先着順です。手が空いた担当者がキューの次のチケットを受け取ります。
結果は予測可能です。請求争いはアカウントの閲覧権限を持たない新入社員に届きます。複雑なAPIインテグレーションの質問は、一般的なサポートキューに時間を費やすべきでないシニア開発者に届きます。エンタープライズ顧客の更新に関する懸念は、アカウント履歴を知らないジュニアエージェントに届きます。そして、シンプルなハウツーの質問を処理できたはずのAIボットは、ルーティングロジックが区別できないため人間にルーティングします。
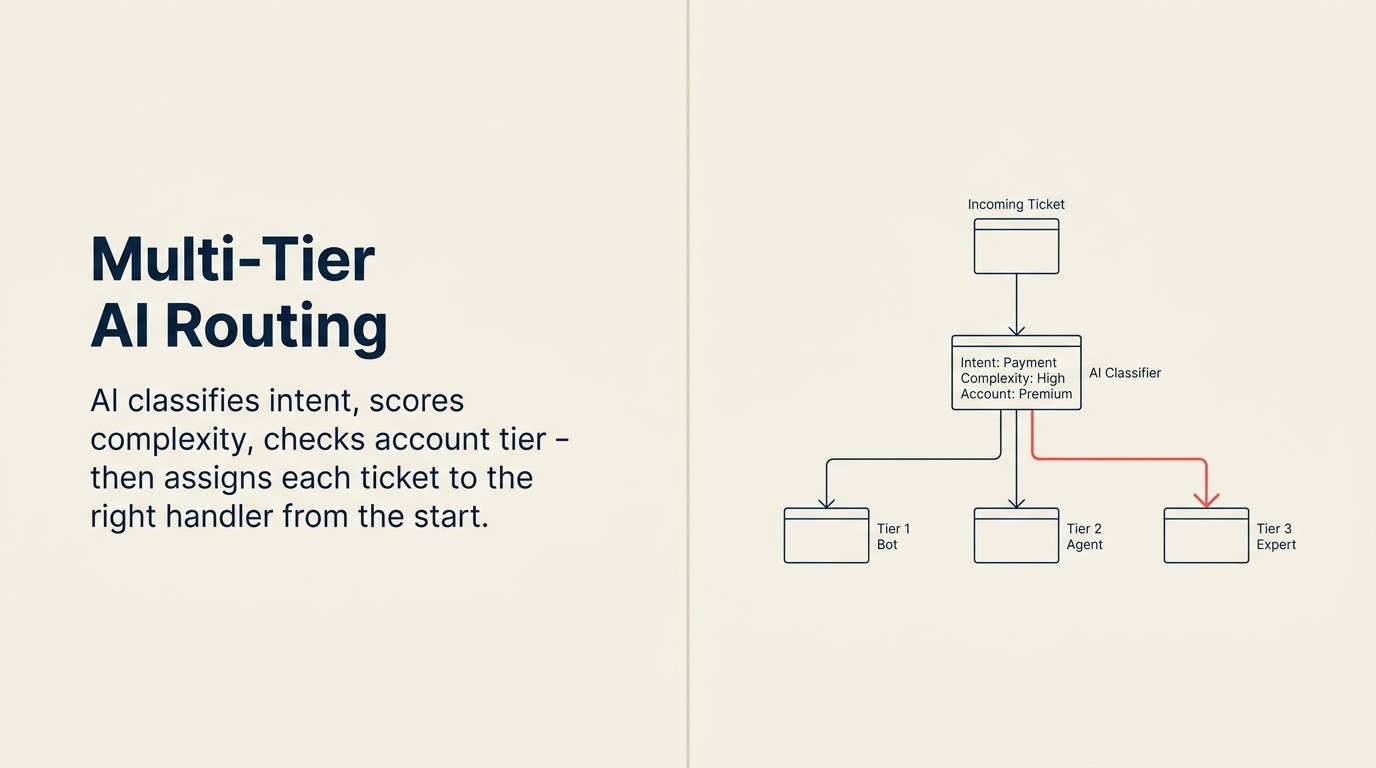
マルチティアAIルーティングがこれを解決します。AIはすべてのチケットを人間の目に触れる前に分類し、複雑さをスコアリングし、顧客のアカウントティアを確認し、適切なティアの適切な担当者に割り当てます。効率の向上は本物ですが、ルーティングの背後にある運用モデルが正しく設計されている場合に限ります。
マルチティアルーティングの意味
3ティアモデルは、AIルーティングを実行するSaaSサポート業務の標準構造です。
ティア1(L1): AIセルフサービス。RAG Assistantがチケットを完全に解決しようとします。成功した場合、チケットは人間の関与なしにクローズします。ハウツーの質問、ドキュメントの検索、既知のエラーコードの解決、プランの比較質問、インテグレーションのセットアップガイドです。L1デフレクションが報告するデフレクション率です。
ティア2(L2): AIアシストによる人間エージェント。人間がAIアシストでチケットを担当します。ナレッジベースからの提案された回答、顧客のアカウント履歴のサマリー、すでに表示された関連ドキュメントのリンクです。エージェントは確認し、必要に応じて編集し、回答します。人間の判断が必要だがAIによる準備から恩恵を受ける、中程度の複雑さの問題です。ほとんどの標準的な技術サポートの質問はここに届きます。
ティア3(L3): 専門家による人間対応。複雑、センシティブ、または高価値のチケットを処理するシニアエージェント、開発者、またはアカウントマネージャーです。エスカレーションされたアカウント問題、エンジニアリング調査が必要なバグ、データプライバシーリクエスト、請求争い、Churnの可能性がある会話です。AIセルフサービスの試みなし、完全なコンテキストを付与してスペシャリストに直接ルーティングします。
ルーティングシステムの役割は、どのティアがどのチケットを処理するかを決定し、いずれのティアでもボトルネックを作らずに適切な担当者がすべてのチケットを受け取れるほど正確に行うことです。
重要なファクト: AIルーティングの精度と効率
- 生成AIを搭載したサポートエージェントは顧客の意図理解で92%の精度を達成しており、旧来のキーワードベースのボットの65〜70%と比較して高い水準です(AI Business Weekly、2026年)
- AIを活用したルーティングは、チケットが最初の試みで適切なエージェントまたはシステムに届くことを確保することで、平均処理時間を40%削減します(Unthread、2026年)
- 成熟したAIチケット環境での分類精度は、ラウンドロビンまたは先着順の割り当てと比較してルーティングミスのエラーを50〜60%削減します(Fini Labs、2026年)
インテント・ティア・コンテキストのトリアージモデル
インテント・ティア・コンテキストのトリアージモデルは、SaaSヘルプデスク向けの3要素ルーティング決定Frameworkです。インテントが基本ティアの割り当てを決定します。ハウツーの質問はL1 AIにルーティング、バグ報告はL2に、セキュリティの懸念は即座にL3にルーティングします。ティアはアカウントレベルの上書きを適用します。エンタープライズ顧客のハウツーの質問は、インテント分類に関係なく最低L2にルーティングします。コンテキストは動的な調整を適用します。ヘルススコアが低下し60日間の更新ウィンドウにある顧客からのチケットは、提示された問題タイプに関係なくアカウントマネージャーキューにルーティングします。3つの要素は順番に実行され、各層が前の割り当てを上書きできます。
スコアリングおよびルーティングパターンの適用
ACE FrameworkのScoring and Routing Patternがこの仕組みを正確に説明しています。受信チケットを取り込み(Ingest)、その特徴(インテント、複雑さ、顧客データ)を分析し(Analyze)、適切なティアを予測し(Predict)、ルーティング割り当てを実行します(Execute)。
インテント分類が主要なインプットです。AIはチケットのテキストを読み、いくつかのインテントカテゴリのいずれかに分類します。ハウツーリクエスト、バグ報告、請求の質問、機能リクエスト、エスカレーションまたは苦情、セキュリティの懸念、APIまたは開発者の質問、Onboardingの支援です。各カテゴリにはデフォルトのティア割り当てがあり、複雑さと顧客ティアに基づいて調整されます。
複雑さのスコアリングがインテント分類に細かさを加えます。3日間回答を待っているエンタープライズ顧客からのマルチステップの技術Workflowに関するハウツーの質問は、基本設定についてSMBトライアルユーザーからのハウツーの質問と同じチケットではありません。インテントは同じことを言いますが、複雑さのスコアリングは異なるルーティングをします。
インテント、複雑さ、顧客ティアの組み合わせがルーティングを単純なカテゴリ分けではなく知的なものにします。システムが分類を行い始めると、精度が次の課題になります。
インテント分類の実際
Zendesk AIは、履歴チケットデータでトレーニングされたモデルを使用して受信チケットをインテントバケットに分類します。カテゴリを提供すれば、モデルは過去に人間エージェントが分類したチケットから学習します。トレーニングデータは自社のチケット履歴であるため、モデルはチームが過去にどのようにチケットをルーティングしてきたかの反映においてますます精度が高まります。
Freshdesk Freddyも同様に機能します。履歴上の分類に基づくインテント分類で、チケットのプロパティ(件名、本文テキスト、添付ファイルの有無)を特徴として使用します。両システムとも信頼度のしきい値を定義できます。分類の信頼度が設定レベルを下回る場合、チケットは自動的に割り当てられるのではなく、人間のレビューキューにルーティングされます。
Intercom Finはインテントの上にあるConversation Routingロジックを使用します。対象チケットタイプについてAIによる解決を最初に試み、AIが解決できない場合は完全なコンテキストとともに人間エージェントに引き継ぎます。
初期のトレーニングパスは通常90日間の履歴チケットで実行されます。ほとんどのチームは、6〜12ヶ月の履歴データを使用した最初のデプロイでインテント分類精度が80〜85%に達し、誤分類が修正されてモデルにフィードバックされる3〜4ヶ月間の本番ルーティングの後に90%以上に向上することを発見しています。Gartnerはカスタマーサービスの中核的なAI価値ドライバーとしてトリアージ精度の改善と専門家の特定を特定しており、これは目指しているルーティング分類品質に直接マッピングされます。
アカウントティアのルーティングルール
顧客ティアは、差別化された顧客ティアを持つSaaSビジネスにとって、インテントベースのルーティングで最も重要な上書き要素です。
ルールはシンプルで、学習されるのではなくハードコーディングされるべきです。エンタープライズ顧客は、自発的にオプトインしない限り、最初のタッチポイントとしてL1 AIセルフサービスを経由しません。最低L2にルーティングし、チケットタイプに基づいてL3も利用可能です。
理由はテクニカルではなく商業的なものです。エンタープライズ顧客は高いサービスレベルのために相当な年間定期収益(ARR)を支払っています。サポートチケットを送信してAIチャットボットの応答を受け取るエンタープライズ顧客は、SMBトライアルユーザーとは異なるサービス期待を持っています。その期待に応えることが、高ティアアカウントにとっての製品の一部です。
SMBトライアルユーザーと低ARRの月次顧客が正しいL1 AIセルフサービスのターゲットです。彼らは24/7の迅速なAI応答から恩恵を受け、AIではなく人間エージェントでチケットを処理する経済性は有利です。しかし、$200,000のエンタープライズ顧客にAIセルフサービスを適用すると、AIが正しく答えたかどうかに関係なく、ポジショニングの間違いをしたことになります。
ルーティングロジックでこれらのルールを明示的に設定してください。Zendesk AIは顧客ティアベースのルーティングルールを許可します。Intercomは顧客属性に基づくConversation Routingの条件でこれをサポートします。Freshdeskはセグメントベースの割り当てルールを使用します。ルーティングツールは詳細です。ルール自体は、アルゴリズムの推論に任せるのではなく、サポートリーダーシップによって行われるポリシー決定であるべきです。
SaaS固有のルーティングシグナル
インテントと顧客ティアの他に、特定のチケットの特性は他の要因に関係なく即座なルーティング決定のトリガーとなるべきです。
API認証エラーは開発者サポートまたは開発者適格の人間エージェントにルーティングします。これらは一般的なサポートの質問ではありません。OAuthトークンの問題、APIキーの設定、インテグレーション固有のデバッグを調査できる人が必要です。API認証エラーを一般的なサポートエージェントにルーティングすると、全員の時間を無駄にし、解決時間を大幅に増加させます。
更新ウィンドウ中の請求の質問。 アカウントが60日間の更新ウィンドウにある場合、請求の質問は一般的な請求サポートではなくアカウント管理にルーティングします。アカウントマネージャーには可視性が必要であり、会話は請求の問い合わせと同様に維持の会話でもあります。サブスクリプションモデルにおけるAI Churn予測では、ヘルススコアデータがこの更新ウィンドウのルーティングロジックに情報を提供する方法を解説しています。
セキュリティ関連のキーワード。 不正アクセス、データ侵害の疑い、アカウント侵害、または異常なログインアクティビティに関連する用語を含むチケットは、L3に直接ルーティングし即座にアラートを生成します。AIセルフサービスの試みなし、L2での保留なし。セキュリティの懸念は即座にシニアの人間に届きます。
明示的な「キャンセル」またはChurnのシグナル。 キャンセル、競合他社との比較検討、または著しい不満の表明に関する言語を含むチケットは、一般的なサポートではなく、CSコンテキストが表示された人間にルーティングします。会話はサポートから維持へと移行しました。
これらのシグナルベースの上書きは学習された動作としてではなく、ルーティングルールとして設定されます。決定論的であるべきです。チケットにセキュリティ関連のキーワードが含まれている場合、常にL3にルーティングします。
エスカレーション品質: コンテキストの引き継ぎ
ルーティングはチケットがどこに届くかを決定します。しかし、コンテキストなしのルーティングはコンテキストありのルーティングより悪い体験を生み出します。
AIが人間エージェントに引き継ぐとき、エージェントは以下を受け取るべきです。顧客の完全な会話履歴、AIが試みたこと(応答を試みた場合)、AIが解決できなかった理由(低信頼度、フラグが立てられたキーワード、顧客ティア)、顧客のアカウントデータ(在籍期間、ARR、ヘルススコア、最近のサポート履歴)、RAG検索で提案された関連ドキュメントのリンクです。
コールドハンドオフとは、エージェントがAIとのインタラクションのコンテキストを持っていないため、顧客が人間エージェントに全問題を繰り返さなければならないときです。コールドハンドオフはCSATを大幅に低下させます。顧客の体験は「ボットに説明したのに、今また人間に説明しなければならない」というものです。これはシームレスな体験ではありません。2つの別々の、断絶した会話です。
Intercom Finは引き継ぎを通じて会話コンテキストを明示的に保持します。人間エージェントはフルスレッド、Finが試みたこと、会話が届いた理由を確認します。Zendesk AIはチケットとともに会話コンテキストを渡します。これが適切に実装されたルーティングシステムの最低要件です。引き継ぎはコンテキストが転送されるため、顧客には見えないものでなければなりません。
エスカレーションのボトルネックを防ぐ
調整が不十分なルーティングの失敗モードはエスカレーションのボトルネックです。ルーティングモデルが保守的すぎると、AIまたはジュニアL2エージェントが処理すべきチケットがL2またはL3に多く割り当てられます。シニアエンジニアが自分の専門知識を必要としないチケットに時間を費やします。全体的に解決時間が増加します。
これがルーティングの最適化がワンタイムの設定ではなく、継続的な運用タスクである理由です。
月次のルーティング監査を実施してください。過去1ヶ月のL3チケットを取得します。それらのうち何%が正しくL3に分類されましたか?L2で処理できたものはなぜエスカレーションされましたか?誤って分類されたインテントですか?過度に保守的な複雑さのしきい値ですか?広すぎるアカウントティアルールですか?
同様に、エスカレーションされたL1 AIデフレクションの試みを監査してください。そのうち、AIの回答が誤っていると顧客が示したためにエスカレーションされたものと、AI品質に関係なく顧客が人間を望んだためにエスカレーションされたものは何%ですか?前者はドキュメントのギャップです。後者は許容されるエスカレーション行動です。
L2のキャパシティをプロアクティブに構築してください。最も一般的なエスカレーションのボトルネックはL2キャパシティの不足です。AIデフレクションが機能している場合(例えばチケットの40%がL1でデフレクション)、残りのチケットは複雑さの点で偏ります。平均的なL2チケットは、AIルーティング以前の平均チケットより難しいです。なぜなら、簡単なものが今はデフレクションされているからです。AI導入以前と同じレベルでL2をスタッフィングすると、エージェントは同じ量の中でより難しいチケットを処理し、より早く燃え尽きます。
これを計画してください。AIルーティングはL1の効率を高めます。L2とL3で複雑さを集中させます。人員計画と専門化計画はそれに応じて調整する必要があります。Gartnerは、カスタマーサービスリーダーの91%が、効率だけでなく満足度を向上させるためのAI実装について経営幹部から圧力を受けていると報告しており、キャパシティ計画の決定はAIルーティングがリーダーシップにとって成功と見られるか負債と見られるかに直接影響します。AIがSaaSオペレーティングモデルをどのように再形成するかでは、このロールの集中がスケールでのチーム構造に何を意味するかを解説しています。
「6〜12ヶ月の履歴チケットデータでトレーニングされたAIルーティングシステムは、最初のデプロイで80〜85%のインテント分類精度に達します。モデルにフィードバックされた3〜4ヶ月の本番修正後、精度は90%以上に向上します。改善は自動的ではありません。誤分類されたチケットにラベルを付けてトレーニングに再提出する月次ルーティング監査が必要です。」(Zendesk AI分類ドキュメント、2025年)
「AIルーティングはデフレクション後にL2とL3で複雑さを集中させます。L1デフレクションが40%で機能している場合、平均的なL2チケットはAIルーティングのデプロイ前の平均チケットより難しいです。なぜなら、簡単なものが今はデフレクションされているからです。AI以前のレベルでL2をスタッフィングしながらAI後のデフレクション率を期待することは、L2の燃え尽きとCSATの崩壊への最速の道です。」(Rework Analysis、GartnerのカスタマーサービスAI研究に基づく、2025年)
ルーティングパフォーマンスベンチマーク
| ルーティング指標 | 目標 | 警告しきい値 | 対応 |
|---|---|---|---|
| インテント分類精度 | 85〜92% | 80%未満 | 修正された誤分類で再トレーニング |
| L1の誤ルーティング率(即座の再エスカレーション) | 12%未満 | 15%以上 | L1適格基準を厳しくする |
| L2での最初の応答時間対AI前のベースライン | 速い | 遅い | L2スタッフィングとAIアシストの採用を確認 |
| 正しく分類されたL3チケット | 90%以上 | 85%未満 | L2-L3エスカレーショントリガールールを監査 |
出典: Zendesk AIチケット分類ドキュメント2025、Gartner Customer Service AIベンチマーク2025、Fini Labsルーティング分析2026
Rework分析: ルーティングモデルの精度の数字(85〜92%)は多くの場合、結果指標として扱われます。そうではありません。ルーティングは、システムが正しく分類しただけでなく、最初の割り当てで適切なスペシャリストがチケットを受け取ったときに正しいのです。「請求」として正しく分類されたが、アカウントコンテキストなしでジュニア請求エージェントにルーティングされた請求争いは、技術的には正しく分類されていますが、運用的には間違っています。真の測定値は初回割り当て解決率です。再エスカレーションなしに最初に受け取った人間によって解決されたチケットの割合です。ティアとチケットタイプ別に追跡されるその数字が、ルーティングが運用的に機能しているのか、それとも単にカテゴリ的に機能しているのかを教えてくれます。
ルーティング品質の指標
ルーティングモデルが機能しているかどうかを示す4つの指標があります。
ティア別の最初の応答時間。 L1 AIの応答はほぼ即座(数秒)であるべきです。L2の人間アシストは、エージェントがゼロから始めないためにアシストなしのベースラインより速くなるべきです。L3はキューへの時間ではなく、専門家への時間を反映すべきです。L2の応答時間がAI前のベースラインより悪い場合、ルーティングは効率ではなく摩擦を生み出しています。
ティア別の解決率。 L1チケットのうち、エスカレーションなしにクローズするものは何%ですか?L2チケットのうち、L3エスカレーションなしにクローズするものは何%ですか?あるティアでの解決率の低下は、ルーティングが処理すべきでないチケットをそのティアに送っていることを示しています。
誤ルーティング率。 L1に割り当てられ、その後即座にL2またはL3にエスカレーションされたチケット、またはL2に割り当てられ、ジュニアエージェントが解決を試みずに即座にエスカレーションしたチケットです。これらがルーティングのミスです。L1またはL2での誤ルーティング率が15%を超える場合、ルーティングモデルの再トレーニングが必要です。
エスカレーション率対デフレクション率の比。 デフレクション率が増加するにつれて、残りのチケットプールのエスカレーション率も自然に増加します(残りのチケットがより難しいため)。エスカレーションがデフレクション率より速く増加している場合、ルーティングモデルは適切なティアで複雑さを抑制できていません。
サポートAIスタックとの接続
マルチティアルーティングは、AIデフレクションのスケールを可能にする運用モデルです。それなしでは、ルーティングが不十分なヘルプデスクにAIセルフサービスを追加すると、効率ではなくエスカレーションの山積みを生み出します。AIが処理できないチケットは、コンテキストなし、優先順位付けなし、適切なスペシャリストが適切なチケットを受け取ることなく人間エージェントに積み重なります。
AI Support Agent for SaaS Self-Serviceでは、L1 AIレイヤーについて詳しく説明しています。RAGが適切に処理するチケットタイプと即座にエスカレーションすべき場所です。
Ticket Deflection with RAG in SaaS Supportでは、デフレクション品質の観点として、デフレクションされたチケットが実際に満足のいく方法で解決されているかどうかを測定する方法を解説しています。
AI Knowledge Base Maintenance for SaaS Docsでは、ナレッジベースを最新の状態に保つことを解説しています。これはL1 AIがルーティングされたチケットを実際に処理できるかどうかを決定します。
マルチティアAIルーティングは、サポート業務を改善するAIセルフサービスと新しい問題を生み出すAIセルフサービスの違いです。ルーティングロジックは単純です。背後にある組織設計、キャパシティ計画、エスカレーションポリシー、継続的なチューニングが本当の仕事です。ルーティングモデルを適切に行えば、製品の成長に合わせてAIデフレクションがスケールします。
よくある質問
SaaSヘルプデスクにおけるマルチティアAIルーティングとは何ですか?
マルチティアAIルーティングは、すべての受信サポートチケットを担当者に割り当てる前にインテント、複雑さ、顧客アカウントティアで分類するシステムです。L1 AIセルフサービスはシンプルでドキュメント化可能なリクエストを処理します。L2 AIアシストによる人間エージェントは中程度の複雑さの問題を処理します。L3スペシャリストは複雑、センシティブ、または高価値のチケットを処理します。ルーティング決定はミリ秒で行われ、ラウンドロビンまたは先着順の割り当てをインテリジェントなマッチングに置き換えます。
AIインテント分類はどの程度の精度を期待できますか?
インテント分類精度は、6〜12ヶ月の履歴チケットデータを使用した最初のデプロイで80〜85%に達します。3〜4ヶ月の本番修正サイクル後、精度は90%以上に向上します。改善は自動的ではありません。誤分類されたチケットにラベルを付けてトレーニングに再提出する月次ルーティング監査が必要です。
エンタープライズ顧客をL1 AIセルフサービスに通すべきでないのはなぜですか?
エンタープライズ顧客は契約上のサービスレベルの期待を持っています。サポートチケットを送信してAIチャットボットの応答を受け取るエンタープライズ顧客は、サービスレベルの不一致を体験します。解決策は明確なルーティングルールです。エンタープライズアカウント(または定義されたARRしきい値以上)は、インテント分類に関係なく最低L2にルーティングします。このルールは明示的に設定されるべきで、アルゴリズムに任せてはなりません。
コールドハンドオフとは何ですか?なぜCSATを低下させるのですか?
コールドハンドオフとは、AIが会話コンテキストを人間に渡さなかったため、顧客が人間エージェントに問題を再説明しなければならないときです。顧客の体験は2つの断絶した会話です。1つはボットとの、もう1つはボットが学んだことを何も知らない人間とのものです。コールドハンドオフのCSATスコアは、完全なコンテキストが転送されるウォームハンドオフより一貫して15〜25%低くなります。
AIルーティングのデプロイ後、エスカレーションのボトルネックをどのように防ぐのですか?
AIルーティングはL1デフレクションを増加させ、より難しいチケットをL2とL3に集中させます。AI以前のレベルでL2をスタッフィングすると、エージェントは同じ量の中でより難しいチケットに直面します。L2キャパシティをプロアクティブに計画してください。40%のL1デフレクション率は残りのチケットプールが平均的に難しいことを意味します。AI以前の人員モデルではなく、そのシフトに合わせてL2スタッフと専門化を構築してください。
インテント分類に関係なく即座にL3ルーティングのトリガーとなるシグナルは何ですか?
4つのシグナルタイプが決定論的なL3ルーティングを必要とします。セキュリティ関連のキーワード(不正アクセス、データ侵害、アカウント侵害)、明示的なキャンセルまたはChurnの言語、更新ウィンドウ中(更新前60日間)の請求争い、そして重大なリスクヘルススコアのアカウントです。これらはポリシールールであり、学習された動作ではありません。明示的に設定されなければならず、他のすべてのルーティングロジックを上書きしなければなりません。
関連リンク:
- Scoring and Routing Pattern: ルーティングインテリジェンスの背後にあるACE Frameworkパターン
- RAG Assistant Pattern: ルーティングが供給するL1セルフサービス層
- AI Support Agent for SaaS Self-Service: SaaSサポートAIの完全なティア構造
- Ticket Deflection with RAG in SaaS Support: ルーティングされたチケットのデフレクション品質指標
- AI Churn Prediction in Subscription Models: 更新ウィンドウのヘルスデータがルーティングルールに情報を提供する方法
- AI Knowledge Base Maintenance for SaaS Docs: L1解決のためのナレッジベースを最新の状態に保つ方法
