More in
Notícias de AI no Trabalho
A OpenAI Abriu a Publicidade no ChatGPT para Pequenas Empresas com Qualquer Orçamento
jun 6, 2026
AI Está em Todo Lugar no Trabalho. Apenas 1 em 10 Diz que Transformou o Emprego
jun 6, 2026
O Momento de US$ 10,5B do Vibe Coding: AI Agora Inicia a Maioria dos Novos Projetos de Software
jun 6, 2026
Agentes de AI Agora Têm Mais Acesso ao Sistema do que Seus Funcionários. Poucos Estão Protegidos
jun 5, 2026
Você Deve Construir Sua AI ou Comprá-la? Observe o que os Gigantes Compraram.
jun 5, 2026
A Uber Limitou os Gastos de AI por Funcionário a US$ 1.500 por Assento Após um Estouro de Orçamento
jun 5, 2026
O Decreto Executivo de AI de Trump é Desregulamentador. Seu Risco de Conformidade Não Mudou
jun 4, 2026
A AI Empurrou 220 Unicórnios Abaixo de US$ 1B. Empresas Pré-ChatGPT Enfrentam um Acerto de Contas
jun 4, 2026
Os Preços de Token Caíram 67% Este Ano. Sua Conta de AI Está Aumentando de Qualquer Forma
jun 3, 2026
Pequenas Empresas que Usam AI Relatam Maior Receita e Jornadas de Trabalho Mais Curtas
jun 3, 2026
O Dia 1 do Snowflake Summit 26 Acabou de Colapsar a Decisão de Stack de AI: Gravidade de Dados Vence a Gravidade de Modelos Agora

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dois anúncios. Uma plataforma. As duas principais famílias de modelos frontier.
O Snowflake Summit 26 abriu hoje em São Francisco com uma série de novidades de produto que a empresa vinha preparando desde fevereiro. De acordo com o comunicado à imprensa da Snowflake, o conjunto de produtos do primeiro dia inclui o Cortex AISQL em preview público, o Snowflake Intelligence em disponibilidade geral, Adaptive Compute, Openflow, produtos agentic no Snowflake Marketplace e o SnowConvert AI para migrações de sistemas legados.
O keynote de abertura coloca o CEO da Snowflake, Sridhar Ramaswamy, ao lado de Daniela Amodei, presidente da Anthropic. No início deste ano, a Snowflake divulgou uma parceria de US$ 200 milhões com a OpenAI que trouxe o GPT-5.2 para dentro do perímetro Snowflake, disponível nativamente para as Cortex AI Functions e a Cortex REST API. Duas famílias de modelos frontier. O mesmo perímetro de dados. O mesmo plano de governança.
Essa combinação muda a pergunta de arquitetura para CTOs. A pergunta antiga era "qual modelo vamos licenciar?" A nova pergunta é "dentro de qual gravidade de dados vamos executar a inferência?"
O Que o Primeiro Dia de Fato Entregou
Três dos itens do primeiro dia merecem atenção séria de CTOs.
Fatos Relevantes
- US$ 200 milhões: o compromisso de parceria plurianual da Snowflake com a OpenAI, trazendo o GPT-5.2 nativamente para dentro do Cortex AI (anúncio conjunto Snowflake-OpenAI, 2 de fevereiro de 2026)
- 20.000+: participantes esperados no Snowflake Summit 26 entre 1 e 4 de junho (comunicações oficiais do Snowflake Summit 26)
- 2: famílias de modelos frontier (OpenAI GPT-5.2 e Anthropic Claude) agora chamáveis nativamente dentro do perímetro de governança da Snowflake
Cortex AISQL. AI generativa chamável diretamente de queries SQL, inclusive sobre dados não estruturados: texto, imagens e áudio em suas tabelas e stages. Isso não é uma nova categoria de produto, mas a superfície dentro do SQL é o que importa. Analistas de dados podem promtar um modelo sem sair do fluxo de trabalho. Não há uma plataforma separada de AI/ML para provisionar, nenhuma infraestrutura de serving de modelos para gerenciar e nenhum evento de egresso de dados ao executar a inferência. A chamada inteira acontece dentro do seu perímetro governado.
Snowflake Intelligence (GA). A camada de interface agentic no data cloud. Em vez de construir agents sobre uma plataforma separada que depois se comunica com seus dados, o runtime de agents fica dentro do mesmo perímetro que os dados. O raciocínio acontece onde os registros vivem. Isso resolve as questões de residência de dados e governança que atrasaram as implantações de agents empresariais nos últimos 12 meses.
Adaptive Compute e Openflow. Menos chamativas nas manchetes, mas críticas operacionalmente. O Adaptive Compute escala cargas de trabalho de forma independente, o que importa porque cargas de trabalho de AI não se comportam como cargas de trabalho analíticas. São intermitentes, demandam GPU e imprevisíveis. O Openflow é a camada de movimentação de dados que coloca seus dados operacionais dentro do perímetro sem pipelines sob medida. Ambos reduzem o atrito de executar AI dentro da Snowflake versus chamá-la de fora.
Por Que "Gravidade de Dados Vence Gravidade de Modelos" É a Leitura Correta
A parceria Snowflake-OpenAI é o que inclina o enquadramento.
Até fevereiro deste ano, a conversa de CTO sobre arquitetura de AI soava assim: "Precisamos escolher um modelo primário. OpenAI para inteligência geral, Anthropic para análise de contexto longo, talvez Gemini para multimodal. Então construímos uma camada de serving que chama eles. Depois gerenciamos a movimentação de dados entre nossos sistemas e os deles." O modelo era o centro gravitacional. Todo o resto era encanamento de integração.
Esse modelo está se desfazendo. A Microsoft colocou a OpenAI dentro do Azure. A Anthropic está agora nativamente dentro do AWS Bedrock e da Snowflake. O Google colocou seus próprios modelos dentro de seus produtos de dados e analytics. A Databricks entrega sua própria camada de modelos em sua plataforma de dados. Os modelos frontier não são mais escassos ou diferenciados o suficiente para conduzir a arquitetura. Estão se tornando cada vez mais intercambiáveis no nível da carga de trabalho.
O que NÃO é intercambiável são seus dados. Seus registros de clientes, seus tickets de suporte, seu histórico de transações, seus contratos. Esses dados ficam em algum lugar. São caros (juridicamente, operacionalmente, politicamente) de mover. Portanto, o lugar onde os dados já vivem está se tornando o lugar onde o trabalho de AI tem que acontecer.
Chamamos isso de Teste de Gravidade de Dados. Para qualquer carga de trabalho de AI, pergunte: onde os dados já vivem e qual é o custo de movê-los para outro lugar para executar a inferência? Se a resposta for "eles vivem na Snowflake e mover custa US$ X milhões em trabalho de pipeline, US$ Y em taxas de egresso, mais revisão de governança", então o local correto de inferência é o que minimiza a movimentação. Hoje, para muitas empresas, esse lugar é a própria Snowflake.
Esse não é um ponto específico da Snowflake. É um ponto posicional. A mesma lógica favorece o Microsoft Fabric para organizações com a maioria dos dados na Microsoft, e a Databricks para organizações com a maioria dos dados lá. A plataforma que possui os dados obtém o runtime de agents.
As Três Perguntas que Todo CTO Deve Responder Esta Semana
O Snowflake Summit vai produzir uma enxurrada de tabelas de preços, estudos de caso de parceiros e comparações de funcionalidades nas próximas 72 horas. Nada disso importa até você responder a três perguntas.
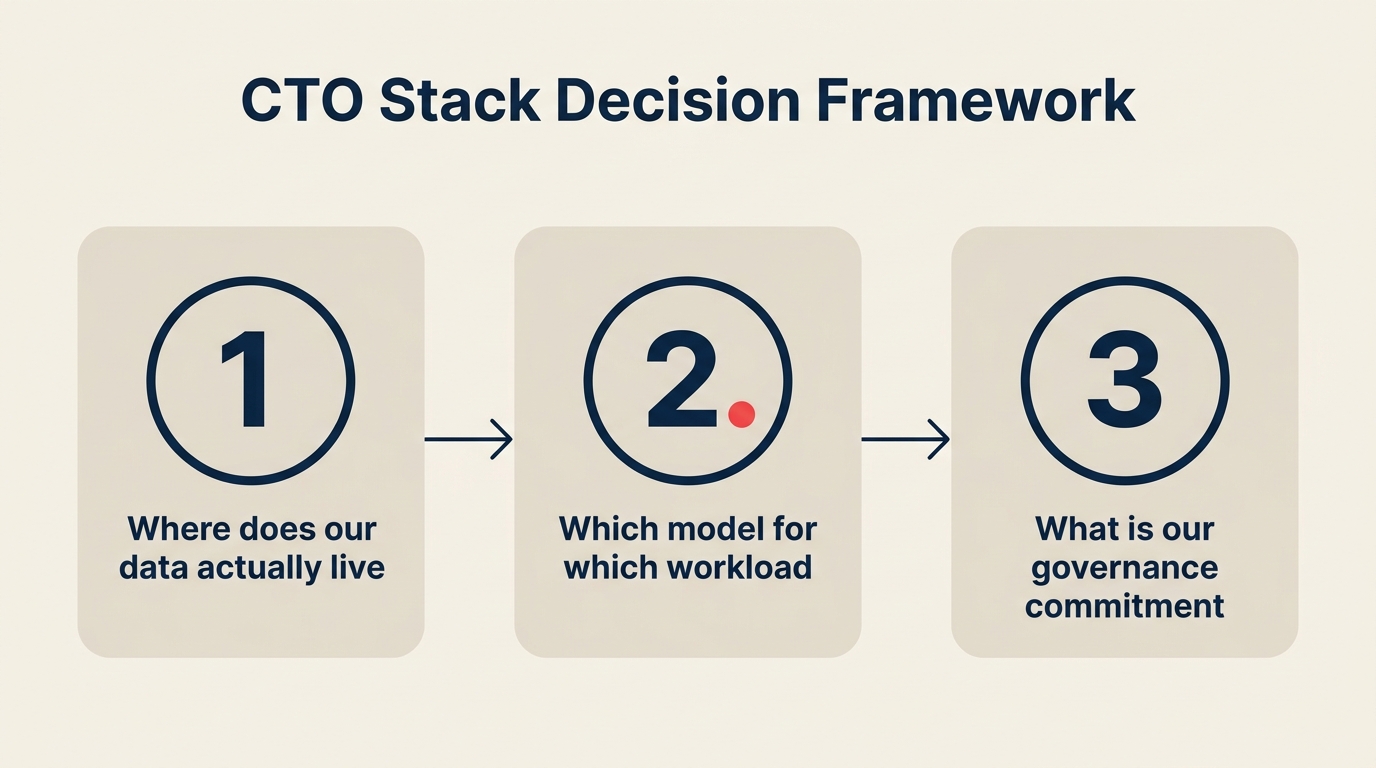
Pergunta 1: Onde seus dados operacionais de fato vivem hoje? Seja honesto. Não "onde queremos que estejam." Onde eles estão? Se 70% dos dados de clientes, histórico de transações e telemetria de produtos já estão na Snowflake, a nova superfície agentic vai ganhar cargas de trabalho de AI operacional independentemente de qual modelo é tecnicamente melhor num benchmark público. Se seus dados estão espalhados entre S3, réplicas de Postgres e uma instância do Salesforce sem camada intermediária de warehouse, você ainda não está numa decisão orientada por gravidade de dados. Você está primeiro numa decisão de consolidação de dados.
Pergunta 2: De qual modelo você realmente precisa para as próximas três cargas de trabalho no seu roadmap de AI? Não escolha um modelo. Escolha os requisitos da carga de trabalho. Se a Carga de Trabalho A precisa de análise de documentos de contexto longo, isso é território do Claude. Se a Carga de Trabalho B precisa de geração de código e uso de ferramentas agentic, o GPT-5.2 ou o Claude funcionam. Se a Carga de Trabalho C precisa de classificação de alto volume e baixo custo, tanto um modelo frontier menor quanto um modelo de peso aberto na sua plataforma funcionam. Combine carga de trabalho com modelo primeiro, depois verifique se sua plataforma de dados suporta a chamada nativamente. Se sim, ótimo. Se não, a pergunta se torna: você traz o modelo para os dados (via Cortex, Bedrock, Azure AI Foundry) ou move os dados para o modelo (mais egresso, mais trabalho de pipeline, mais revisão de governança)?
Pergunta 3: Qual é o seu compromisso de governança para um ano? A decisão que você toma em 2026 sobre qual perímetro de dados hospeda suas cargas de trabalho de inferência é persistente. Você não vai reconstruir o runtime em 2027 só porque um fornecedor diferente entregou uma funcionalidade melhor. Escolha a plataforma com a qual você consegue conviver por pelo menos 18 meses de escalonamento operacional. Isso significa residência de dados, trilhas de auditoria, controles de acesso, rollback de modelos e um roadmap credível para a próxima geração de modelos aparecer dentro daquele perímetro.
Um CTO de uma empresa SaaS de 1.500 funcionários com a maioria dos dados operacionais na Snowflake deveria estar executando o match carga de trabalho-modelo esta semana, não no próximo trimestre. O Marketplace agentic dentro do Cortex já está entregando agents construídos por parceiros que competem com soluções pontuais que você atualmente compra como assinaturas independentes.
Como Isso Se Mapeia Contra o Microsoft Build e a Databricks
A Snowflake não está anunciando para um vácuo. O Microsoft Build roda de 2 a 3 de junho com seu próprio impulso de plataforma de agents (Windows Agent Framework, Windows Agent Store, expansão do Azure AI Foundry). O Databricks Data + AI Summit chega em meados de junho com sua própria camada de modelos e impulso de agents.
As três posições estão convergindo para uma arquitetura similar, mas partindo de centros de gravidade de dados diferentes.
A aposta da Snowflake: data warehouse como runtime de agents. Mais forte se seus dados operacionais e analíticos vivem na Snowflake. Melhor para organizações cujo trabalho de AI é pesado em dados estruturados mais ativos empresariais não estruturados gerenciados.
A aposta da Microsoft: Windows e Azure como plataforma de agents. Mais forte se seus funcionários vivem no Microsoft 365 e suas ferramentas de desenvolvedor rodam no Azure. Melhor para organizações cujo trabalho de AI é pesado em trabalho de conhecimento, documentos e fluxos de trabalho de desenvolvedores.
A aposta da Databricks: lakehouse mais model serving como base de agents. Mais forte se sua engenharia de dados é madura e seu trabalho de AI é pesado em implantação de modelos de ML, não apenas AI generativa.
A maioria das empresas não vai escolher apenas um. Vão terminar com perímetros primários e secundários. Um padrão razoável como ponto de partida: escolha o perímetro onde os dados voltados ao cliente já vivem como o primário, depois aceite que você vai executar algumas cargas de trabalho de agents em seu perímetro de produtividade de funcionários (provavelmente Microsoft) de qualquer forma. Essa postura dupla é aceitável. O que não é aceitável é fazer quatro apostas primárias simultaneamente e terminar sem uma propriedade clara do runtime.
Para frameworks de decisão executiva sobre investimento em força de trabalho de AI, o teste de gravidade de dados fica ao lado do teste de habilidades da força de trabalho. Ambas as perguntas convergem para a mesma resposta: como você evita investimentos estagnados?
O Que Informar ao Seu Conselho Neste Trimestre
As novidades do Summit vão chegar ao seu conselho pela cobertura da imprensa nas próximas duas semanas. Saia na frente.
Uma apresentação de quatro slides cobre o terreno. Slide um: onde nossos dados operacionais vivem atualmente (a resposta honesta). Slide dois: as três cargas de trabalho no nosso roadmap de AI de 18 meses e os requisitos de modelo para cada uma. Slide três: o perímetro de dados que estamos comprometendo como primário e por quê, com a postura de governança de um ano. Slide quatro: o perímetro secundário que aceitamos que vai existir (provavelmente Microsoft para produtividade) e a abordagem de integração.
O que você quer evitar: um membro do conselho lendo um resumo do Summit e perguntando "por que não estamos usando o Snowflake Intelligence?" quando a resposta é "porque nossos dados operacionais não ficam lá". Ou pior: "estamos migrando porque o comunicado parecia impressionante". Torne a realidade da gravidade de dados explícita para que as perguntas do conselho caiam no eixo correto.
Para mais informações sobre a mudança operacional para AI agents no pipeline de vendas, a mesma lógica de gravidade de dados se aplica dentro do stack de vendas. A plataforma que possui o registro de cliente vai possuir o runtime do agent de vendas.
A semana do Summit vai produzir muito ruído sobre quem entregou qual funcionalidade. O sinal é estrutural. Modelos frontier são agora commodities hospedadas. Plataformas de dados são agora runtimes de agents. Essa é a pergunta de arquitetura que todo CTO vai estar respondendo nos próximos 18 meses.
Saiba Mais
- A lacuna de governança que líderes erram sobre AI no trabalho
- AI copilots versus AI agents
- Medindo ROI de AI
- Roadmap de força de trabalho de AI de 12 meses para uma empresa de 200 pessoas
FAQ
Isso significa que devemos migrar nossos dados para a Snowflake?
Não necessariamente. A gravidade de dados vence a gravidade de modelos, mas onde seus dados já estão é uma posição estabelecida. Se 70% dos seus dados operacionais já estão na Snowflake, a superfície agentic lá vai ganhar cargas de trabalho por padrão. Se seus dados estão no Microsoft Fabric, na Databricks ou na AWS, a resposta certa é usar o runtime de agents nativo daquele perímetro. A migração entre plataformas raramente se justifica só por funcionalidades de AI. O custo de mover terabytes de dados de clientes governados é quase sempre maior do que o diferencial de qualidade de modelo entre plataformas nos próximos 18 meses.
O GPT-5.2 dentro da Snowflake é o mesmo que o GPT-5.2 diretamente da OpenAI?
Funcionalmente, sim para a maioria dos casos de uso. Operacionalmente, não. Dentro da Snowflake, a chamada acontece dentro do seu perímetro de governança, então os dados dos clientes nunca saem do seu limite. O custo de tokens é cobrado em créditos Snowflake em vez de um contrato de API da OpenAI. Os limites de taxa e cotas funcionam de forma diferente. Para cargas de trabalho reguladas (saúde, serviços financeiros, qualquer coisa sob regras de residência de dados), a versão dentro do perímetro é materialmente mais fácil de defender em uma auditoria. Para experimentação em estágio inicial, a API direta da OpenAI costuma ser mais simples.
E quanto a executar nossos próprios modelos em nossa própria infraestrutura?
Ainda viável para cargas de trabalho específicas onde a economia de custos, a latência ou a sensibilidade dos dados o afastam de um modelo frontier hospedado. O trade-off mudou, porém. Com tanto a OpenAI quanto a Anthropic agora nativamente dentro das principais plataformas de dados, o caso operacional para executar seus próprios modelos é mais restrito do que era há um ano. Os nichos restantes são classificação de altíssimo volume (modelos pequenos ajustados), requisitos estritos de on-premise e modelos verticais especializados onde um treinamento personalizado realmente supera um modelo frontier geral. Para a maioria dos trabalhos de conhecimento e AI voltada ao cliente, modelos frontier dentro do perímetro serão o padrão este ano.

Co-Founder, Rework.com