More in
Noticias de AI en el Trabajo
OpenAI Abrio la Publicidad en ChatGPT a Pequenas Empresas con Cualquier Presupuesto
jun. 6, 2026
La AI Esta en Todas Partes en el Trabajo. Solo 1 de Cada 10 Dice que Transformo el Empleo
jun. 6, 2026
El Momento de $10.5B del Vibe Coding: AI Ahora Inicia la Mayoria de los Nuevos Desarrollos de Software
jun. 6, 2026
Los Agentes de AI Tienen Ahora Mas Acceso al Sistema que sus Empleados. Pocos Estan Asegurados
jun. 5, 2026
¿Deberia Construir su AI o Comprarla? Observe lo que Compraron los Gigantes.
jun. 5, 2026
Uber Limita el Gasto de AI por Empleado a $1,500 por Puesto Tras un Descontrol Presupuestario
jun. 5, 2026
La Orden Ejecutiva de AI de Trump es Desregulatoria. Su Riesgo de Cumplimiento No Cambio
jun. 4, 2026
La AI Empujo a 220 Unicornios por Debajo de $1B. Las Empresas Pre-ChatGPT Enfrentan un Ajuste de Cuentas
jun. 4, 2026
Los Precios por Token Cayeron un 67% Este Ano. Su Factura de AI Sigue Subiendo
jun. 3, 2026
Las Pequenas Empresas que Usan AI Reportan Mayores Ingresos y Jornadas Laborales Mas Cortas
jun. 3, 2026
Snowflake Summit 26 Día 1 Colapsó la Decisión sobre el Stack de AI: La Gravedad de los Datos Supera la Gravedad del Modelo

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dos anuncios. Una plataforma. Ambas familias de modelos frontier líderes.
Snowflake Summit 26 se inauguró hoy en San Francisco con una oleada de noticias de producto que la empresa ha ido preparando desde febrero. Según el comunicado de prensa de Snowflake, el conjunto de productos del primer día incluye Cortex AISQL en vista previa pública, Snowflake Intelligence en disponibilidad general, Adaptive Compute, Openflow, productos agénticos en el Snowflake Marketplace y SnowConvert AI para migraciones de sistemas heredados.
El keynote de apertura presenta al CEO de Snowflake, Sridhar Ramaswamy, junto a Daniela Amodei, presidenta de Anthropic. A principios de este año, Snowflake reveló una alianza de 200 millones de dólares y varios años con OpenAI que trajo GPT-5.2 dentro del perímetro de Snowflake, disponible de forma nativa para Cortex AI Functions y la Cortex REST API. Dos familias de modelos frontier. El mismo perímetro de datos. El mismo plano de gobernanza.
Esa combinación cambia la pregunta de arquitectura para el CTO. La pregunta anterior era "¿qué modelo licenciamos?" La nueva pregunta es "¿dentro de qué gravedad de datos ejecutamos la inferencia?"
Lo Que Realmente Se Lanzó el Día Uno
Tres de los elementos del primer día merecen atención seria por parte de los CTOs.
Datos Clave
- 200 millones de dólares: el compromiso de la alianza plurianual de Snowflake con OpenAI, que trae GPT-5.2 de forma nativa dentro de Cortex AI (anuncio conjunto Snowflake-OpenAI, 2 de febrero de 2026)
- Más de 20.000: asistentes esperados en Snowflake Summit 26 del 1 al 4 de junio (comunicaciones oficiales de Snowflake Summit 26)
- 2: familias de modelos frontier (OpenAI GPT-5.2 y Anthropic Claude) ahora invocables de forma nativa dentro del perímetro de gobernanza de Snowflake
Cortex AISQL. AI generativa invocable directamente desde consultas SQL, incluyendo sobre datos no estructurados: texto, imágenes y audio que residen en sus tablas y stages. No es una nueva categoría de producto, pero la superficie dentro de SQL es lo que importa. Los analistas de datos pueden consultar un modelo sin salir de su flujo de trabajo. No hay que provisionar una plataforma separada de AI/ML, no hay infraestructura de model-serving que gestionar y no hay evento de salida de datos al ejecutar la inferencia. La llamada completa ocurre dentro de su límite gobernado.
Snowflake Intelligence (GA). La capa de interfaz agéntica sobre el data cloud. En lugar de construir agentes sobre una plataforma separada que luego habla con sus datos, el runtime del agente reside dentro del mismo perímetro que los datos. El razonamiento ocurre donde viven los registros. Eso resuelve las preguntas de residencia de datos y gobernanza que han frenado los despliegues de agentes empresariales durante los últimos 12 meses.
Adaptive Compute y Openflow. Menos llamativos pero operativamente críticos. Adaptive Compute escala las cargas de trabajo de forma independiente, lo que importa porque las cargas de trabajo de AI no se comportan como las analíticas. Son intermitentes, requieren mucha GPU y son impredecibles. Openflow es la capa de movimiento de datos que lleva sus datos operativos al perímetro sin pipelines a medida. Ambos reducen la fricción de ejecutar AI dentro de Snowflake frente a llamarla desde fuera.
Por Qué "La Gravedad de los Datos Supera la Gravedad del Modelo" Es la Lectura Correcta
La alianza Snowflake-OpenAI es lo que inclina la balanza.
Hasta febrero de este año, la conversación de los CTOs sobre arquitectura de AI sonaba así: "Necesitamos elegir un modelo primario. OpenAI para inteligencia general, Anthropic para análisis de contexto largo, quizás Gemini para multimodal. Luego construimos una capa de serving que los llame. Luego gestionamos el movimiento de datos entre nuestros sistemas y los suyos." El modelo era el centro gravitacional. Todo lo demás era plomería de integración.
Ese modelo se está desmoronando. Microsoft puso a OpenAI dentro de Azure. Anthropic está ahora de forma nativa dentro de AWS Bedrock y Snowflake. Google puso sus propios modelos dentro de sus productos de datos y analítica. Databricks incorpora su propia capa de modelos en su plataforma de datos. Los modelos frontier ya no son lo suficientemente escasos ni diferenciados como para conducir la arquitectura. Son cada vez más intercambiables a nivel de carga de trabajo.
Lo que NO es intercambiable son sus datos. Sus registros de clientes, sus tickets de soporte, su historial de transacciones, sus contratos. Esos datos residen en algún lugar. Moverlos es costoso (legal, operativa y políticamente). Por eso el lugar donde ya viven los datos se está convirtiendo en el lugar donde tiene que ocurrir el trabajo de AI.
Llamamos a esto el Test de Gravedad de Datos. Para cualquier carga de trabajo de AI, pregúntese: ¿dónde viven ya los datos, y cuál es el costo de moverlos a otro lugar para ejecutar la inferencia? Si la respuesta es "viven en Snowflake y moverlos cuesta X millones de dólares en trabajo de pipeline, Y en tarifas de salida, más revisión de gobernanza", entonces la ubicación correcta para la inferencia es la que minimiza el movimiento. Hoy, para muchas empresas, esa ubicación es el propio Snowflake.
Ese no es un punto específico de Snowflake. Es un punto posicional. La misma lógica favorece a Microsoft Fabric para las organizaciones con la mayor parte de sus datos en Microsoft, y a Databricks para las que los tienen allí. La plataforma que posee los datos obtiene el runtime de los agentes.
Las Tres Preguntas Que Todo CTO Debería Responder Esta Semana
Snowflake Summit producirá un aluvión de tablas de precios, casos de estudio de partners y comparativas de funcionalidades durante las próximas 72 horas. Nada de eso importa hasta que responda tres preguntas.
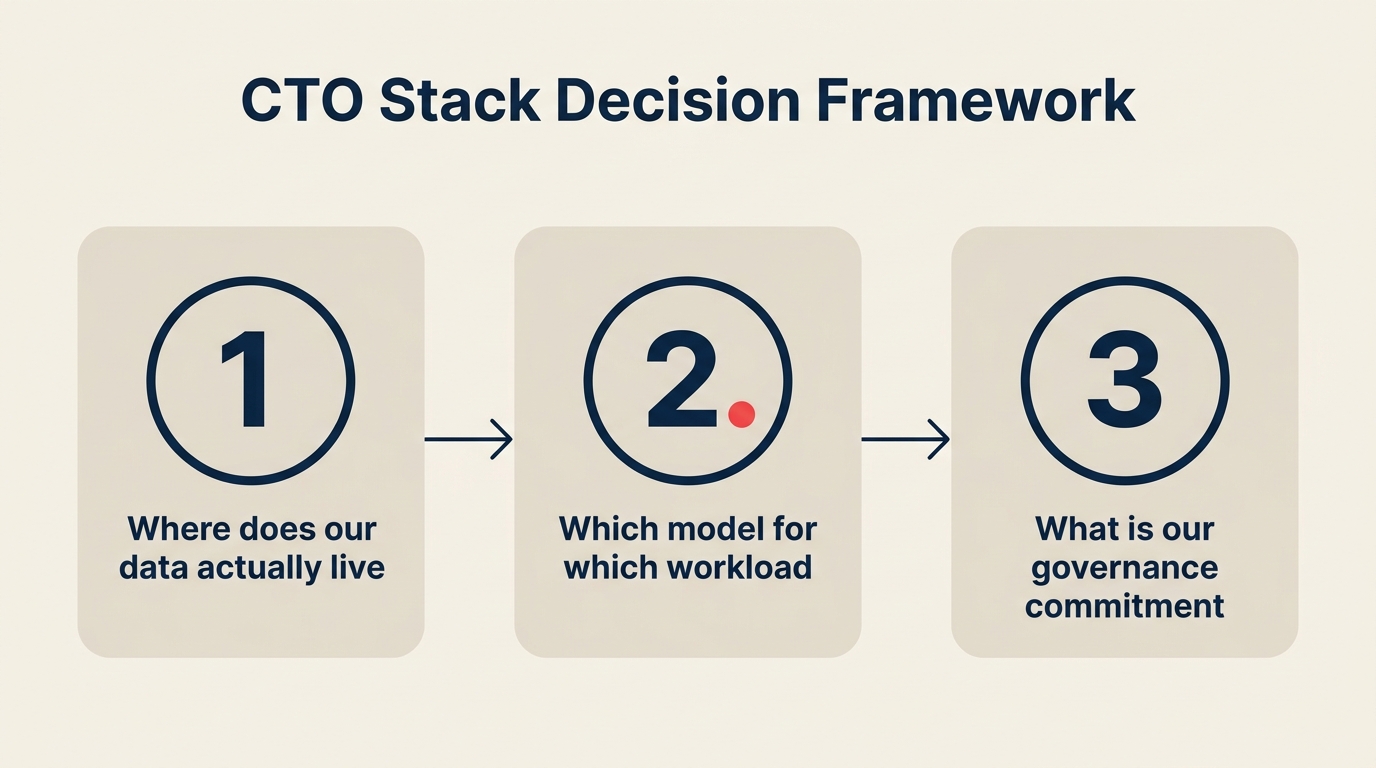
Pregunta 1: ¿Dónde viven realmente sus datos operativos hoy? Sea honesto. No "dónde queremos que estén". ¿Dónde residen? Si el 70% de sus datos de clientes, historial de transacciones y telemetría de producto ya están en Snowflake, la nueva superficie agéntica ganará las cargas de trabajo operativas de AI independientemente de qué modelo sea técnicamente mejor en un benchmark público. Si sus datos están distribuidos entre S3, réplicas de Postgres y una instancia de Salesforce sin una capa de warehouse en el medio, aún no está en una decisión conducida por la gravedad de datos. Primero tiene una decisión de consolidación de datos.
Pregunta 2: ¿Qué modelo necesita realmente para las próximas tres cargas de trabajo en su roadmap de AI? No elija un modelo. Elija los requisitos de la carga de trabajo. Si la Carga de Trabajo A necesita análisis de documentos de contexto largo, ese es territorio de Claude. Si la Carga de Trabajo B necesita generación de código y uso agéntico de herramientas, GPT-5.2 o Claude funcionan ambos. Si la Carga de Trabajo C necesita clasificación de alto volumen y bajo costo, puede usarse un modelo frontier más pequeño o un modelo de peso abierto en su plataforma. Primero haga coincidir la carga de trabajo con el modelo, luego compruebe si su plataforma de datos admite la llamada de forma nativa. Si es así, perfecto. Si no, la pregunta pasa a ser: ¿lleva el modelo a los datos (vía Cortex, Bedrock, Azure AI Foundry) o mueve los datos al modelo (más salida, más trabajo de pipeline, más revisión de gobernanza)?
Pregunta 3: ¿Cuál es su compromiso de gobernanza a un año? La decisión que tome en 2026 sobre qué perímetro de datos aloja sus cargas de trabajo de inferencia es persistente. No va a reconstruir el runtime en 2027 solo porque un proveedor diferente lanzó una funcionalidad mejor. Elija la plataforma con la que pueda vivir durante al menos 18 meses de escalamiento operativo. Eso implica residencia de datos, registros de auditoría, controles de acceso, rollback de modelos y un roadmap creíble para que la próxima generación de modelos aparezca dentro de ese perímetro.
Un CTO en una empresa SaaS de 1.500 personas con la mayoría de sus datos operativos en Snowflake debería estar ejecutando la correspondencia carga de trabajo-modelo esta semana, no el próximo trimestre. El Marketplace agéntico dentro de Cortex ya lanza agentes construidos por partners que compiten con soluciones puntuales que actualmente compra como suscripciones independientes.
Cómo Se Compara Esto con Microsoft Build y Databricks
Snowflake no anuncia en el vacío. Microsoft Build se celebra del 2 al 3 de junio con su propio impulso de plataforma de agentes (Windows Agent Framework, Windows Agent Store, expansión de Azure AI Foundry). Databricks Data + AI Summit llega a mediados de junio con su propia capa de modelos e impulso de agentes.
Las tres posiciones convergen en una arquitectura similar pero parten de centros de gravedad de datos distintos.
La apuesta de Snowflake: el data warehouse como el runtime de agentes. Más fuerte si sus datos operativos y analíticos viven en Snowflake. Lo mejor para organizaciones cuyo trabajo de AI es intensivo en datos estructurados más activos no estructurados gestionados a nivel empresarial.
La apuesta de Microsoft: Windows y Azure como la plataforma de agentes. Más fuerte si sus empleados viven en Microsoft 365 y sus herramientas de desarrollo se ejecutan en Azure. Lo mejor para organizaciones cuyo trabajo de AI es intensivo en trabajo del conocimiento, documentos y flujos de trabajo de desarrollo.
La apuesta de Databricks: lakehouse más model serving como la base de agentes. Más fuerte si su ingeniería de datos es madura y su trabajo de AI es intensivo en despliegue de modelos de ML, no solo en AI generativa.
La mayoría de las empresas no elegirán una sola. Terminarán con perímetros primarios y secundarios. Un punto de partida razonable: elija el perímetro donde ya viven sus datos orientados al cliente como primario, luego acepte que ejecutará algunas cargas de trabajo de agentes en su perímetro de productividad para empleados (probablemente Microsoft) independientemente. Esa postura dual está bien. Lo que no está bien es hacer cuatro apuestas primarias simultáneamente y terminar sin una propiedad clara del runtime.
Para los frameworks de decisión ejecutiva sobre la inversión en fuerza laboral con AI, el test de gravedad de datos se sitúa junto al test de habilidades de la fuerza laboral. Ambas preguntas convergen en la misma respuesta: ¿cómo evita las inversiones varadas?
Qué Informar a Su Directorio Este Trimestre
Las noticias del Summit llegarán a su directorio a través de la cobertura de prensa en las próximas dos semanas. Tome la delantera.
Una presentación de cuatro diapositivas cubre el terreno. Diapositiva uno: dónde viven actualmente nuestros datos operativos (la respuesta honesta). Diapositiva dos: las tres cargas de trabajo de nuestro roadmap de AI a 18 meses y los requisitos de modelo para cada una. Diapositiva tres: el perímetro de datos al que nos comprometemos como primario y por qué, con la postura de gobernanza a un año. Diapositiva cuatro: el perímetro secundario que aceptamos que existirá (probablemente Microsoft para productividad) y el enfoque de integración.
Lo que quiere evitar: que un miembro del directorio lea un resumen del Summit y pregunte "¿por qué no estamos usando Snowflake Intelligence?" cuando la respuesta es "porque nuestros datos operativos no viven ahí". O peor aún, "estamos migrando porque el comunicado de prensa sonaba impresionante". Haga explícita la realidad de la gravedad de datos para que las preguntas del directorio caigan en el eje correcto.
Para más información sobre el cambio operativo hacia los agentes de AI en el pipeline de ventas, la misma lógica de gravedad de datos aplica dentro del stack de ventas. La plataforma que posee el registro del cliente poseerá el runtime del agente de ventas.
La semana del Summit va a producir mucho ruido sobre quién lanzó qué funcionalidad. La señal es estructural. Los modelos frontier son ahora commodities hospedados. Las plataformas de datos son ahora runtimes de agentes. Esa es la pregunta de arquitectura que cada CTO estará respondiendo durante los próximos 18 meses.
Más Información
- La brecha de gobernanza que los líderes se equivocan sobre la AI en el trabajo
- Copilots de AI vs. agentes de AI
- Medir el ROI de AI
- Roadmap de fuerza laboral con AI a 12 meses para una empresa de 200 personas
Preguntas Frecuentes
¿Significa esto que debemos mover nuestros datos a Snowflake?
No necesariamente. La gravedad de los datos supera la gravedad del modelo, pero donde ya residen sus datos es una posición establecida. Si el 70% de sus datos operativos ya están en Snowflake, la superficie agéntica allí ganará las cargas de trabajo por defecto. Si sus datos están en Microsoft Fabric, Databricks o AWS, la respuesta correcta es usar el runtime de agentes nativo de ese perímetro. La migración entre plataformas rara vez se justifica solo por funcionalidades de AI. El costo de mover terabytes de datos de clientes gobernados es casi siempre mayor que la diferencia de calidad de modelos entre plataformas durante los próximos 18 meses.
¿GPT-5.2 dentro de Snowflake es lo mismo que GPT-5.2 de OpenAI directamente?
Funcionalmente, sí para la mayoría de los casos de uso. Operativamente, no. Dentro de Snowflake, la llamada ocurre dentro de su perímetro de gobernanza, de modo que los datos del cliente nunca abandonan su límite. El costo de los tokens se factura a través de créditos de Snowflake en lugar de un contrato de API de OpenAI. Los límites de velocidad y cuota funcionan de manera diferente. Para cargas de trabajo reguladas (salud, servicios financieros, cualquier cosa sujeta a normas de residencia de datos), la versión dentro del perímetro es materialmente más fácil de defender en auditoría. Para experimentación en un nuevo campo, la API directa de OpenAI suele ser más sencilla.
¿Qué pasa con ejecutar nuestros propios modelos en nuestra propia infraestructura?
Sigue siendo viable para cargas de trabajo específicas donde la economía de costos, la latencia o la sensibilidad de los datos le alejan de un modelo frontier hospedado. Sin embargo, el equilibrio ha cambiado. Con tanto OpenAI como Anthropic ahora de forma nativa dentro de las principales plataformas de datos, el argumento operativo para ejecutar modelos propios es más acotado que hace un año. Los nichos que quedan son la clasificación de muy alto volumen (modelos pequeños ajustados), los requisitos estrictos de on-premise y los modelos verticales especializados donde un entrenamiento personalizado realmente supera a un modelo frontier general. Para la mayoría del trabajo de AI orientado al conocimiento y al cliente, los modelos frontier dentro del perímetro serán el estándar este año.

Co-Founder, Rework.com