More in
Berita AI di Tempat Kerja
OpenAI Membuka Iklan ChatGPT untuk Bisnis Kecil dengan Anggaran Berapa Pun
Jun 6, 2026
AI Ada di Mana-mana di Tempat Kerja. Hanya 1 dari 10 yang Menyatakan AI Benar-benar Mengubah Pekerjaan Mereka
Jun 6, 2026
Momen $10,5 Miliar Vibe Coding: AI Kini Memulai Sebagian Besar Pembangunan Perangkat Lunak Baru
Jun 6, 2026
AI Agent Kini Memiliki Akses Sistem Lebih Besar dari Karyawan Anda. Sedikit yang Sudah Diamankan
Jun 5, 2026
Bangun atau Beli AI Anda? Perhatikan Apa yang Dibeli Para Raksasa.
Jun 5, 2026
Uber Membatasi Pengeluaran AI Karyawan di $1.500 per Kursi Setelah Anggaran Jebol
Jun 5, 2026
Perintah Eksekutif AI Trump Bersifat Deregulasi. Risiko Kepatuhan Anda Tidak Berubah
Jun 4, 2026
AI Mendorong 220 Unicorn Turun di Bawah $1 Miliar. Perusahaan Pra-ChatGPT Menghadapi Tantangan Besar
Jun 4, 2026
Harga Token Turun 67% Tahun Ini. Tagihan AI Anda Tetap Naik
Jun 3, 2026
Bisnis Kecil yang Menggunakan AI Melaporkan Pendapatan Lebih Tinggi dan Jam Kerja Lebih Singkat
Jun 3, 2026
Bahasa Indonesia
Hari Pertama Snowflake Summit 26 Meruntuhkan Keputusan Stack AI: Gravitasi Data Kini Mengalahkan Gravitasi Model

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Dua pengumuman. Satu platform. Dua keluarga model frontier teratas.
Snowflake Summit 26 dibuka hari ini di San Francisco dengan serangkaian berita produk yang telah disiapkan perusahaan sejak Februari. Menurut siaran pers Snowflake, set produk hari pertama mencakup Cortex AISQL dalam pratinjau publik, Snowflake Intelligence dengan ketersediaan umum (GA), Adaptive Compute, Openflow, produk agen di Snowflake Marketplace, dan SnowConvert AI untuk migrasi sistem lama.
Keynote pembukaan mempertemukan CEO Snowflake Sridhar Ramaswamy dengan Presiden Anthropic Daniela Amodei. Awal tahun ini, Snowflake mengungkapkan kemitraan senilai $200 juta multi-tahun dengan OpenAI yang membawa GPT-5.2 ke dalam perimeter Snowflake, tersedia secara native untuk Cortex AI Functions dan Cortex REST API. Dua keluarga model frontier. Perimeter data yang sama. Control plane tata kelola yang sama.
Kombinasi tersebut mengubah pertanyaan arsitektur CTO. Pertanyaan lama adalah "model mana yang kita lisensi?" Pertanyaan baru adalah "dalam gravitasi data mana kita menjalankan inferensi?"
Apa yang Sebenarnya Diluncurkan di Hari Pertama
Tiga item hari pertama layak mendapat perhatian serius CTO.
Fakta Kunci
- $200 juta: komitmen kemitraan multi-tahun Snowflake dengan OpenAI, membawa GPT-5.2 secara native ke dalam Cortex AI (pengumuman bersama Snowflake-OpenAI, 2 Februari 2026)
- 20.000+: Peserta yang diharapkan di Snowflake Summit 26 selama 1-4 Juni (komunikasi resmi Snowflake Summit 26)
- 2: Keluarga model frontier (OpenAI GPT-5.2 dan Anthropic Claude) yang kini dapat dipanggil secara native dalam perimeter tata kelola Snowflake
Cortex AISQL. AI generatif yang dapat dipanggil langsung dari kueri SQL, termasuk terhadap data tidak terstruktur: teks, gambar, dan audio yang berada di tabel dan stage Anda. Ini bukan kategori produk baru, tetapi permukaan di-dalam-SQL adalah yang penting. Analis data dapat meminta model tanpa meninggalkan alur kerja mereka. Tidak ada platform AI/machine learning (ML) terpisah yang perlu disediakan, tidak ada infrastruktur model-serving yang perlu dikelola, dan tidak ada peristiwa egress data saat menjalankan inferensi. Seluruh panggilan terjadi di dalam batas yang diatur Anda.
Snowflake Intelligence (GA). Lapisan antarmuka agen pada data cloud. Daripada membangun agen di atas platform terpisah yang kemudian berkomunikasi kembali dengan data Anda, runtime agen berada di dalam perimeter yang sama dengan data. Penalaran terjadi di mana catatan berada. Itu menyelesaikan pertanyaan residensi data dan tata kelola yang telah menghambat penerapan agen perusahaan selama 12 bulan terakhir.
Adaptive Compute dan Openflow. Kurang menarik perhatian utama tetapi kritis secara operasional. Adaptive Compute melakukan auto-scale beban kerja secara independen, yang penting karena beban kerja AI tidak berperilaku seperti beban kerja analitik. Beban kerja AI bersifat bursty, haus GPU, dan tidak dapat diprediksi. Openflow adalah lapisan perpindahan data yang membawa data operasional Anda ke dalam perimeter tanpa pipeline khusus. Keduanya mengurangi hambatan menjalankan AI di dalam Snowflake versus memanggilnya dari luar.
Mengapa "Gravitasi Data Mengalahkan Gravitasi Model" Adalah Bacaan yang Tepat
Kemitraan Snowflake-OpenAI adalah yang mengubah perspektif.
Hingga Februari tahun ini, percakapan CTO tentang arsitektur AI terdengar seperti ini: "Kita perlu memilih model utama. OpenAI untuk kecerdasan umum, Anthropic untuk analisis konteks panjang, mungkin Gemini untuk multimodal. Kemudian kita membangun lapisan serving yang memanggilnya. Kemudian kita mengelola perpindahan data antara sistem kita dan mereka." Model adalah pusat gravitasi. Selebihnya adalah pipa integrasi.
Model tersebut mulai runtuh. Microsoft menempatkan OpenAI di dalam Azure. Anthropic kini secara native ada di dalam AWS Bedrock dan Snowflake. Google menempatkan modelnya sendiri di dalam produk data dan analitiknya. Databricks mengirimkan lapisan modelnya sendiri pada platform datanya. Model frontier tidak lagi cukup langka atau terdiferensiasi untuk mendorong arsitektur. Model frontier semakin dapat dipertukarkan di tingkat beban kerja.
Yang TIDAK dapat dipertukarkan adalah data Anda. Catatan pelanggan, tiket dukungan, riwayat transaksi, kontrak Anda. Data tersebut berada di suatu tempat. Memindahkannya itu mahal (secara hukum, operasional, politis). Jadi tempat data sudah berada menjadi tempat pekerjaan AI harus terjadi.
Kami menyebut ini Data Gravity Test. Untuk beban kerja AI apa pun, tanyakan: di mana data sudah berada, dan berapa biaya memindahkannya ke tempat lain untuk menjalankan inferensi? Jika jawabannya adalah "berada di Snowflake dan memindahkannya menelan biaya $X juta dalam pekerjaan pipeline, $Y dalam biaya egress, ditambah tinjauan tata kelola," maka lokasi inferensi yang tepat adalah yang meminimalkan perpindahan. Saat ini, bagi banyak perusahaan, lokasi tersebut adalah Snowflake itu sendiri.
Ini bukan poin khusus Snowflake. Ini adalah poin posisional. Logika yang sama menguntungkan Microsoft Fabric bagi organisasi dengan sebagian besar data di Microsoft, dan Databricks bagi organisasi dengan sebagian besar data di sana. Platform yang memiliki data mendapatkan runtime agen.
Tiga Pertanyaan yang Harus Dijawab Setiap CTO Minggu Ini
Summit Snowflake akan menghasilkan banjir tabel harga, studi kasus mitra, dan perbandingan fitur selama 72 jam ke depan. Tidak ada yang penting sampai Anda menjawab tiga pertanyaan.
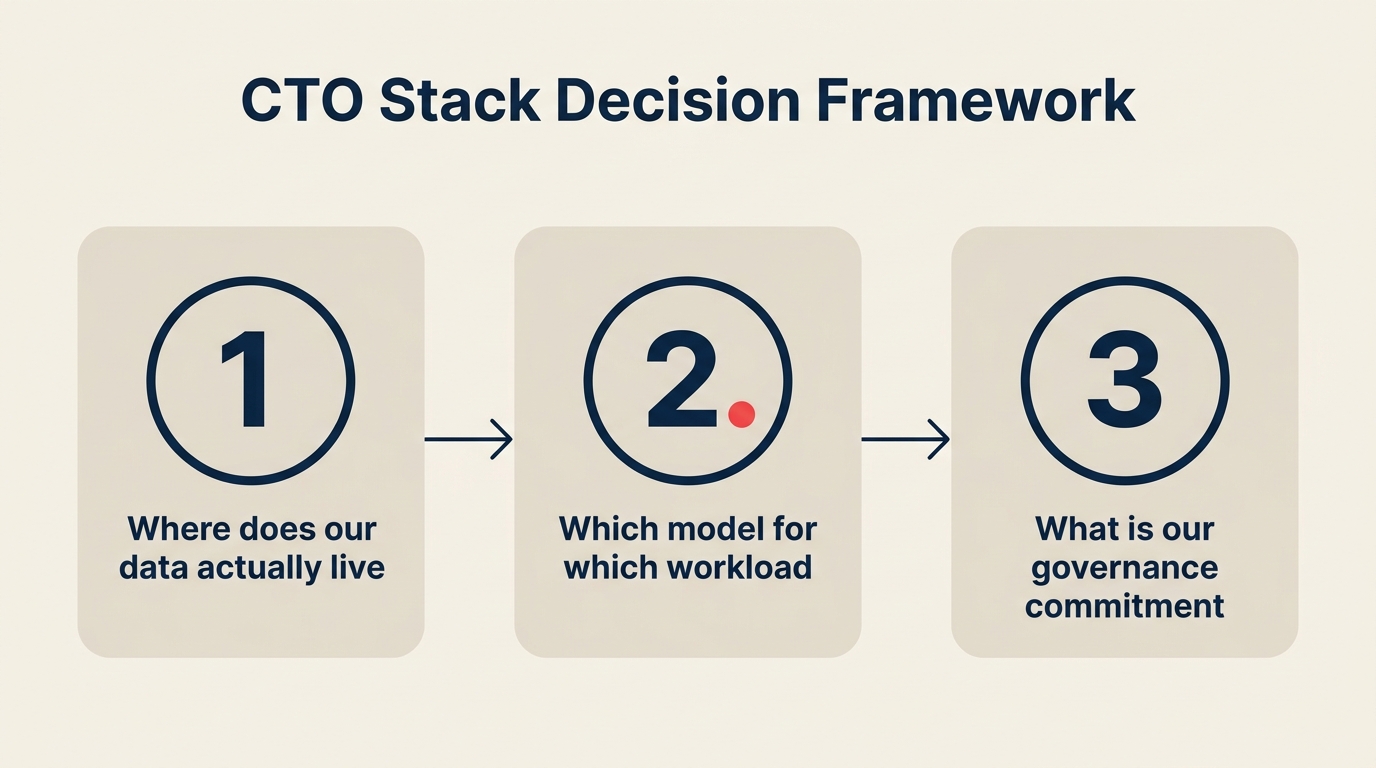
Pertanyaan 1: Di mana data operasional Anda sebenarnya berada hari ini? Jujurlah. Bukan "di mana kita ingin data itu berada." Di mana data tersebut berada? Jika 70% data pelanggan, riwayat transaksi, dan telemetri produk Anda sudah ada di Snowflake, permukaan agen baru akan memenangkan beban kerja AI operasional terlepas dari model mana yang secara teknis terbaik pada tolok ukur publik. Jika data Anda tersebar di S3, replika Postgres, dan instans Salesforce tanpa lapisan warehouse di tengah, Anda belum dalam keputusan berbasis gravitasi data. Anda pertama-tama dalam keputusan konsolidasi data.
Pertanyaan 2: Model mana yang sebenarnya Anda butuhkan untuk tiga beban kerja berikutnya di roadmap AI Anda? Jangan pilih model. Pilih persyaratan beban kerja. Jika Beban Kerja A membutuhkan analisis dokumen konteks panjang, itu adalah wilayah Claude. Jika Beban Kerja B membutuhkan pembuatan kode dan penggunaan alat agen, GPT-5.2 atau Claude keduanya berhasil. Jika Beban Kerja C membutuhkan klasifikasi volume tinggi berbiaya rendah, model frontier yang lebih kecil atau model open-weight pada platform Anda lebih cocok. Cocokkan beban kerja dengan model terlebih dahulu, kemudian periksa apakah platform data Anda mendukung panggilan secara native. Jika mendukung, bagus. Jika tidak, pertanyaannya menjadi: apakah Anda membawa model ke data (melalui Cortex, Bedrock, Azure AI Foundry) atau memindahkan data ke model (lebih banyak egress, lebih banyak pekerjaan pipeline, lebih banyak tinjauan tata kelola).
Pertanyaan 3: Apa komitmen tata kelola satu tahun Anda? Keputusan yang Anda buat pada 2026 tentang perimeter data mana yang menampung beban kerja inferensi Anda bersifat melekat. Anda tidak akan membangun ulang runtime pada 2027 hanya karena vendor berbeda mengirimkan fitur yang lebih baik. Pilih platform yang dapat Anda jalani setidaknya 18 bulan penskalaan operasional. Itu berarti residensi data, jejak audit, kontrol akses, rollback model, dan roadmap yang kredibel untuk generasi model berikutnya yang muncul di dalam perimeter tersebut.
CTO di perusahaan SaaS dengan 1.500 orang dan sebagian besar data operasional di Snowflake harus menjalankan pencocokan beban kerja ke model minggu ini, bukan kuartal depan. Marketplace agen di dalam Cortex sudah mengirimkan agen yang dibangun mitra yang bersaing dengan solusi titik yang saat ini Anda beli sebagai langganan mandiri.
Bagaimana Ini Dipetakan terhadap Microsoft Build dan Databricks
Snowflake tidak mengumumkan dalam kekosongan. Microsoft Build berjalan 2-3 Juni dengan dorongan platform agennya sendiri (Windows Agent Framework, Windows Agent Store, perluasan Azure AI Foundry). Databricks Data + AI Summit mendarat pertengahan Juni dengan lapisan model dan dorongan agen sendiri.
Tiga posisi tersebut berkumpul pada arsitektur serupa tetapi dimulai dari pusat gravitasi data yang berbeda.
Taruhan Snowflake: data warehouse sebagai runtime agen. Paling kuat jika data operasional dan analitik Anda berada di Snowflake. Terbaik untuk organisasi yang pekerjaan AI-nya banyak menggunakan data terstruktur ditambah aset tidak terstruktur yang dikelola perusahaan.
Taruhan Microsoft: Windows dan Azure sebagai platform agen. Paling kuat jika karyawan Anda tinggal di Microsoft 365 dan alat pengembang Anda berjalan di Azure. Terbaik untuk organisasi yang pekerjaan AI-nya banyak menggunakan pekerjaan berbasis pengetahuan, dokumen, dan alur kerja pengembang.
Taruhan Databricks: lakehouse ditambah model serving sebagai fondasi agen. Paling kuat jika rekayasa data Anda sudah matang dan pekerjaan AI Anda banyak menggunakan penerapan model machine learning, bukan hanya AI generatif.
Sebagian besar perusahaan tidak akan memilih satu. Mereka akan berakhir dengan perimeter primer dan sekunder. Default yang masuk akal: pilih perimeter di mana data yang menghadap pelanggan sudah berada sebagai yang primer, kemudian terima bahwa Anda akan menjalankan beberapa beban kerja agen di perimeter produktivitas karyawan (kemungkinan Microsoft) terlepas dari itu. Postur ganda tersebut baik-baik saja. Yang tidak baik adalah membuat empat taruhan primer secara bersamaan dan berakhir tanpa kepemilikan runtime yang jelas.
Untuk kerangka keputusan eksekutif tentang investasi tenaga kerja AI, Data Gravity Test berdampingan dengan uji keterampilan tenaga kerja. Kedua pertanyaan berkumpul pada jawaban yang sama: bagaimana Anda menghindari investasi yang terbengkalai?
Yang Harus Dibriefing kepada Dewan Direksi Kuartal Ini
Berita Summit akan menjangkau dewan Anda melalui liputan pers dalam dua minggu ke depan. Bersiaplah lebih awal.
Briefing empat slide mencakup konten yang diperlukan. Slide satu: di mana data operasional kita saat ini berada (jawaban yang jujur). Slide dua: tiga beban kerja dalam roadmap AI 18 bulan kita dan persyaratan model untuk masing-masing. Slide tiga: perimeter data yang kita komitmen sebagai primer dan alasannya, dengan postur tata kelola satu tahun. Slide empat: perimeter sekunder yang kita terima akan ada (kemungkinan Microsoft untuk produktivitas) dan pendekatan integrasi.
Yang ingin Anda hindari: anggota dewan membaca rekap Summit dan bertanya "mengapa kita tidak menggunakan Snowflake Intelligence?" ketika jawabannya adalah "karena data operasional kita tidak berada di sana." Atau lebih buruk lagi, "kita bermigrasi karena siaran pers terdengar mengesankan." Buat realitas gravitasi data menjadi eksplisit agar pertanyaan dewan mendarat pada poros yang tepat.
Untuk informasi lebih lanjut tentang pergeseran operasional ke agen AI dalam pipeline penjualan, logika gravitasi data yang sama berlaku di dalam stack penjualan. Platform yang memiliki catatan pelanggan akan memiliki runtime agen penjualan.
Pekan Summit akan menghasilkan banyak kebisingan tentang siapa yang meluncurkan fitur apa. Sinyalnya bersifat struktural. Model frontier kini merupakan komoditas yang di-hosting. Platform data kini merupakan runtime agen. Itulah pertanyaan arsitektur yang akan dijawab setiap CTO selama 18 bulan ke depan.
Pelajari Lebih Lanjut
- Kesenjangan tata kelola yang salah dipahami pemimpin tentang AI di tempat kerja
- AI copilots vs agen AI
- Mengukur ROI AI
- Roadmap tenaga kerja AI 12 bulan untuk perusahaan dengan 200 orang
FAQ
Apakah ini berarti kita harus memindahkan data kita ke Snowflake?
Belum tentu. Gravitasi data mengalahkan gravitasi model, tetapi di mana data Anda sudah berada adalah posisi yang sudah tertanam. Jika 70% data operasional Anda sudah ada di Snowflake, permukaan agen di sana akan memenangkan beban kerja secara default. Jika data Anda ada di Microsoft Fabric, Databricks, atau AWS, jawaban yang tepat adalah menggunakan runtime agen yang native untuk perimeter tersebut. Migrasi lintas platform jarang dibenarkan hanya oleh fitur AI. Biaya memindahkan terabyte data pelanggan yang diatur hampir selalu lebih tinggi daripada perbedaan kualitas model antar platform selama 18 bulan ke depan.
Apakah GPT-5.2 di dalam Snowflake sama dengan GPT-5.2 langsung dari OpenAI?
Secara fungsional, ya untuk sebagian besar kasus penggunaan. Secara operasional, tidak. Di dalam Snowflake, panggilan terjadi di dalam perimeter tata kelola Anda, sehingga data pelanggan tidak pernah meninggalkan batas Anda. Biaya token ditagih melalui kredit Snowflake, bukan kontrak API OpenAI. Batas rate dan kuota bekerja secara berbeda. Untuk beban kerja yang diatur (layanan kesehatan, layanan keuangan, apa pun yang berada di bawah aturan residensi data), versi dalam perimeter secara material lebih mudah dipertahankan dalam audit. Untuk eksperimentasi baru, API OpenAI langsung sering kali lebih sederhana.
Bagaimana dengan menjalankan model kita sendiri pada infrastruktur kita sendiri?
Masih layak untuk beban kerja tertentu di mana ekonomi biaya, latensi, atau sensitivitas data mendorong Anda meninggalkan model frontier yang di-hosting. Namun pertimbangannya telah bergeser. Dengan OpenAI dan Anthropic yang kini secara native berada di dalam platform data utama, kasus operasional untuk menjalankan model Anda sendiri lebih sempit dari setahun yang lalu. Titik manis yang tersisa adalah klasifikasi volume sangat tinggi (model kecil yang di-fine-tune), persyaratan on-premise yang ketat, dan model vertikal khusus di mana run pelatihan kustom benar-benar mengalahkan model frontier umum. Untuk sebagian besar AI berbasis pengetahuan dan menghadap pelanggan, model frontier dalam perimeter akan menjadi default tahun ini.

Co-Founder, Rework.com