Stage 2 sang 3: Từ Pilot đến Scaled, thoát khỏi pilot purgatory
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AI pilot của bạn đã thành công. Người dùng thích nó. Các con số ban đầu khả quan. Nhóm SDR tiết kiệm ba giờ mỗi tuần nhờ email personalization. Reply rate tăng 12%. Người phụ trách pilot trình bày kết quả. Leadership gật đầu.
Rồi ai đó hỏi: "Chúng ta mở rộng quy mô cái này như thế nào?"
Và đột nhiên không ai biết câu trả lời.
Đây là pilot purgatory. Khoảng không gian giữa "pilot đã thành công" và "AI đang chạy trong sản xuất." Phần lớn các tổ chức Stage 2 mắc kẹt ở đây, đôi khi một năm, đôi khi lâu hơn. Forrester xác định use case sprawl là một trong những rào cản lớn nhất khi scale AI: các enterprise thường có hàng chục pilot nhưng thiếu framework để ưu tiên và đưa chúng vào sản xuất. Pilot nằm lơ lửng trong khi nhóm tranh luận về hạ tầng, chờ ngân sách, cãi nhau về ownership, hoặc đơn giản là khởi thêm pilot vì điều đó an toàn hơn so với cam kết mà production đòi hỏi.
Hiểu tại sao pilot purgatory xảy ra là bước đầu tiên để thoát. Nếu bạn vẫn ở Stage 1, đọc Stage 1 sang 2: Từ Ad-Hoc đến Pilot trước.
Pilot purgatory trông như thế nào
Thực tế từ Pilot đến Scale
- Forrester xác định use case sprawl là một trong những rào cản lớn nhất khi scale AI; các enterprise thường có hàng chục pilot nhưng thiếu framework để ưu tiên và đưa chúng vào sản xuất (Forrester, 2025)
- Các tổ chức đã scale AI (Stage 3 trở lên) tạo ra tổng lợi nhuận cổ đông 3 năm cao hơn khoảng 4 lần so với nhóm tụt hậu; khoảng cách giữa dẫn đầu và tụt hậu ngày càng rộng theo từng năm đình trệ ở Stage 2 (BCG, 2025)
- McKinsey phát hiện việc chuyển từ AI pilot thành công sang triển khai enterprise rộng đòi hỏi scaling mindset, cách tiếp cận modular để xây dựng AI asset, và rút ngắn vòng đời phát triển analytics, những yêu cầu mà hầu hết nhóm giai đoạn pilot không được cơ cấu để thực hiện (McKinsey, 2025)
Pilot purgatory có các triệu chứng nhất quán.
Pilot chạy 12 tháng vẫn là pilot. Ranh giới thời gian trong charter đến rồi qua. Không ai quyết định rõ ràng scale. Không ai rõ ràng dừng pilot. Nó cứ chạy ở khối lượng thấp, tiêu tốn nỗ lực mà không tạo ra giá trị ở quy mô sản xuất.
Đánh giá nhiều công cụ cùng lúc. Thay vì cam kết một công cụ và scale nó, nhóm mở đánh giá hai ba lựa chọn. "Chúng ta muốn chọn đúng cái." Mười tám tháng sau vẫn chưa chọn được.
Leadership chờ "thêm một điểm dữ liệu nữa." Pilot tạo ra kết quả tốt, nhưng lãnh đạo muốn cỡ mẫu lớn hơn, khung thời gian dài hơn, hoặc use case phức tạp hơn trước khi cam kết. Bar cứ dịch chuyển mãi.
Không có quyết định hạ tầng nào. Pilot chạy trên thiết lập cloud do vendor quản lý, không có cam kết kiến trúc từ phía công ty. Để scale được cần quyết định về data storage, model hosting, API ownership, và monitoring mà chưa ai đưa ra.
Nhóm pilot kiệt sức. Ba người đã chạy pilot đang bị kéo sang chạy thêm hai pilot nữa trong khi cũng phải tìm cách scale cái đầu tiên. Họ bị trải mỏng, thiếu cấu trúc, và bắt đầu mất kết nối. McKinsey phân tích rằng chuyển từ AI pilot thành công sang enterprise AI hiệu quả đòi hỏi scaling mindset, cách tiếp cận modular, và rút ngắn vòng đời phát triển analytics, không có gì trong số đó một nhóm ba người kiệt sức có thể làm được.
Nếu hai hoặc nhiều hơn trong số này đúng, bạn đang trong pilot purgatory. Lối thoát đòi hỏi kỷ luật thực thi, không phải thêm đánh giá.
"Stage 2-sang-3 thất bại phần lớn không phải vì pilot sai mà vì nhóm coi production deployment như phiên bản lớn hơn của pilot. Không phải vậy. Production đòi hỏi cam kết hạ tầng, change management vượt ra ngoài tình nguyện, cost governance, và người chịu trách nhiệm AI Operations có tên cụ thể. Các công ty chạy Stage 3 với hạ tầng Stage 2 sẽ gặp sự cố, chi phí bất ngờ, và adoption sụp đổ." (Rework)
Crossing Test Stage 2-sang-3
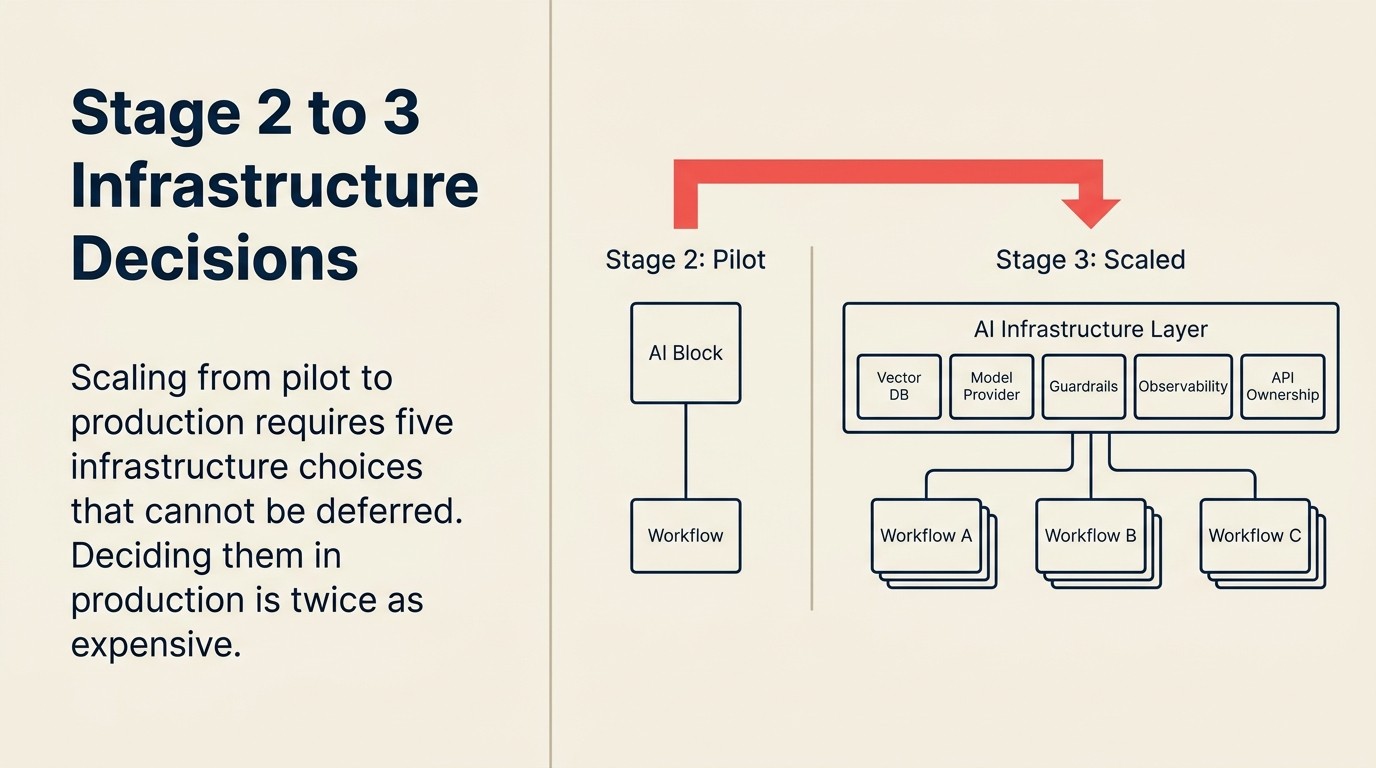
Chẩn đoán bốn yêu cầu xác nhận tổ chức thực sự đã vượt Stage 2, thay vì chỉ gán nhãn lại pilot mở rộng quy mô thành "production." Yêu cầu 1: Một use case triển khai đến toàn bộ người dùng mục tiêu (không phải chỉ cohort tình nguyện), với monitoring đang hoạt động. Yêu cầu 2: Các quyết định hạ tầng chung được ghi lại và cam kết (model provider, vector database, observability stack), không phải ad-hoc từng use case. Yêu cầu 3: Một use case thứ hai đang trong active pilot, dùng hạ tầng ở Yêu cầu 2 làm nền móng. Yêu cầu 4: Người chịu trách nhiệm AI Operations có tên cụ thể, với accountability rõ ràng về uptime hệ thống production, xử lý sự cố, và model versioning. Tổ chức chỉ đáp ứng Yêu cầu 1 đang chạy pilot mở rộng quy mô, không phải triển khai Stage 3.
Tiêu chí thoát Stage 3
Stage 3 không chỉ là "nhiều pilot hơn." Đây là tư thế vận hành khác biệt về chất. Bốn điều phải đồng thời đúng để gọi đây là Stage 3.
| Yêu cầu | Có nghĩa là | Khoảng trống phổ biến |
|---|---|---|
| Một use case trong production | Triển khai đến toàn bộ người dùng mục tiêu, không phải chỉ cohort tình nguyện. Rollout đầy đủ với monitoring tại chỗ. | Vẫn chạy ở quy mô pilot, chỉ cho người dùng "phù hợp" |
| Quyết định hạ tầng chung đã cam kết | Vector database, model provider, guardrail tooling, và observability stack: đã chọn và cam kết | Vẫn dùng hạ tầng ad-hoc của pilot. Mỗi use case chạy trên stack vendor riêng. |
| Một use case thứ hai đang trong active pilot | Bằng chứng learning từ Pilot 1 đã chuyển sang Pilot 2. Không chỉ lên kế hoạch: đang chạy thực. | Toàn bộ năng lực dồn vào scale Pilot 1. Không còn sức cho use case mới. |
| Ownership AI Operations | Cá nhân hoặc nhóm nhỏ có tên cụ thể, chịu trách nhiệm về AI system production: uptime, incident response, model versioning | Người phụ trách pilot vẫn đang quản lý production song song với công việc chính |
Cả bốn phải đúng trước khi gọi tổ chức là Stage 3. Yêu cầu bị bỏ qua phổ biến nhất là hạ tầng chung. Đây cũng là thứ gây ra các vấn đề tốn kém nhất nếu bỏ qua.
Các quyết định hạ tầng Stage 3 đòi hỏi
Đây là phần bất ngờ hầu hết transformation lead đến từ nền tảng mua SaaS. AI ở quy mô sản xuất đòi hỏi các cam kết kiến trúc không áp dụng cho SaaS thông thường. Bạn phải đưa ra các quyết định này trước khi scale, không phải sau.
Lựa chọn vector database. Nếu các ứng dụng AI của bạn liên quan đến retrieval-augmented generation (RAG), tìm kiếm tài liệu nội bộ, hoặc bộ nhớ qua các tương tác, bạn cần vector database. Các lựa chọn lớn năm 2026 là Pinecone, Weaviate, Qdrant, và pgvector (cho nhóm đã dùng PostgreSQL). Lựa chọn nào ít quan trọng hơn việc thực sự đưa ra lựa chọn. Chạy các use case khác nhau trên các vector store khác nhau tạo ra sự phân mảnh tốn kém để tháo gỡ sau này.
Quyết định model provider. Bạn chuẩn hóa trên LLM provider nào? OpenAI, Anthropic, Google, hay kết hợp? Các thỏa thuận enterprise có mức giá, điều khoản xử lý dữ liệu, và đặc điểm hiệu suất khác nhau. Dùng ChatGPT tier miễn phí cho pilot là ổn. Workload production cần thỏa thuận enterprise phù hợp với data processing agreement (DPA) và cam kết SLA.
Guardrail tooling. Làm thế nào ngăn AI tạo output có hại, sai lệch, hoặc lệch thương hiệu ở quy mô? Ở pilot, người xem xét từng output. Ở production, điều đó không thể. Guardrail chạy như các lớp pre- và post-processing quanh model call. Lựa chọn từ prompt engineering tùy chỉnh đến các công cụ chuyên dụng như Guardrails AI hoặc LlamaIndex safety layers.
Observability stack. Làm thế nào bạn biết khi AI gặp sự cố? Ở pilot, người phụ trách nhận ra. Ở production, bạn cần logging, alerting, và dashboard. Các chỉ số cần theo dõi: response latency, error rate, fallback rate, human review trigger. Đây là thành phần hạ tầng mà hầu hết nhóm phát hiện ra cần thiết chỉ sau khi xảy ra sự cố production.
API ownership và rate limit. Ai sở hữu API key cho model provider của bạn? Ở pilot: có thể là người thiết lập pilot. Ở production: service account thuộc IT, với rate limit để tránh spike chi phí và rotation policy cho bảo mật.
Đây không phải quyết định của IT độc lập. Đây là cam kết kiến trúc ảnh hưởng đến mọi AI use case bạn xây dựng sau này. Đưa ra chúng cùng nhau, trước khi scale, tiết kiệm hàng tháng làm lại.
Production deployment checklist

"Chúng ta đưa cái này vào production" có nghĩa khác nhau với các nhóm khác nhau. Với AI system, production có nghĩa cụ thể. Tám điều này phải đúng.
1. Monitoring đang hoạt động. Không phải "chúng ta sẽ kiểm tra thỉnh thoảng." Active monitoring với alert cho spike error rate, suy giảm latency, và pattern output bất thường.
2. Fallback logic tồn tại. Khi AI thất bại (model timeout, guardrail trigger, rate limit), điều gì xảy ra? Người dùng không được nhìn thấy màn hình trắng hay thông báo lỗi thô. Xác định fallback: hiển thị output đã cache, xếp hàng để người xem xét, từ chối một cách nhã nhặn.
3. Cổng human-in-the-loop được xác định. Output nào cần người xem xét trước khi hành động? Với nội dung bên ngoài do AI soạn thảo, xác định rõ người xem trước khi gửi (bắt buộc) hay sau khi gửi (quá muộn). Đặt quy tắc này trước khi ra mắt.
4. Model versioning được theo dõi. Khi model provider cập nhật model, output của bạn có thể thay đổi. Bạn cần hồ sơ về phiên bản model nào đang chạy vào thời điểm nào, để chẩn đoán các thay đổi output không giải thích được.
5. Incident response tồn tại. Nếu AI gửi thông tin sai cho khách hàng, bạn gọi ai? Theo thứ tự nào? SLA giải quyết là bao lâu? Viết runbook trước khi bạn cần nó.
6. Giao tiếp người dùng hoàn tất. Tất cả người dùng mục tiêu đã biết AI đang chạy trong production, hiểu nó làm gì, và đã được hướng dẫn cách xem xét, sửa chữa, và escalate output.
7. Giám sát chi phí đang hoạt động. Workload AI production có thể tạo ra spike chi phí không mong đợi. Lượng token tiêu thụ, khối lượng API call, và lựa chọn model đều ảnh hưởng đến chi phí. Có người sở hữu báo cáo chi phí hàng tháng.
8. Data processing agreement được ký. Nếu AI xử lý dữ liệu cá nhân hoặc dữ liệu bảo mật của công ty, DPA của vendor phải có hiệu lực trước khi production. "Chúng ta sẽ bổ sung DPA sau khi scale" là vi phạm compliance, không phải backlog item.
Checklist này là ranh giới giữa "đã triển khai" và "production." Hầu hết nhóm đạt 5 trong số 8. Ba cái họ bỏ qua là những thứ gây ra sự cố.
Scale change management: từ tình nguyện đến toàn đội
Pilot chạy với tình nguyện viên. Những người trong cohort pilot của bạn đã giơ tay. Họ tò mò về AI, sẵn sàng thử nghiệm, và chấp nhận được sự chưa hoàn chỉnh. Họ không đại diện cho toàn bộ người dùng của bạn.
Production liên quan đến mọi người. Và mọi người bao gồm những người hoài nghi, bị hạn chế thời gian, "cái này có vẻ thêm việc chứ không phải bớt," và những người đang thầm lo rằng nếu AI làm tốt công việc của họ, họ sẽ không còn chỗ nữa.
Đây là nơi Stage 2-sang-3 thường đình trệ nhất. Pilot hoạt động với 20 SDR tình nguyện. Nhóm đầy đủ có 80 người, bao gồm 30 người đã làm công việc này 5 năm và không hứng thú gì với việc thay đổi workflow.
Change management playbook cho Stage 3 có bốn phần.
Đào tạo workflow mới, không phải công cụ. Nhân viên kháng cự công cụ. Họ chấp nhận cải thiện workflow. Đừng tổ chức "AI tool training." Tổ chức "hướng dẫn workflow SDR mới", tình cờ bao gồm AI tool. Cho thấy trước và sau. Làm cho thời gian tiết kiệm được trở nên hữu hình.
Cho người hoài nghi con đường vào an toàn. Đừng bắt buộc AI là con đường duy nhất. Cho phép người hoài nghi dùng tùy chọn lúc đầu. Social proof từ đồng nghiệp nhận kết quả tốt hơn sức thuyết phục hơn lệnh từ executive.
Nói thẳng nỗi sợ thay thế. Nếu bạn không đặt tên rõ ràng mối lo "cái này có thay thế tôi không?", nó sẽ chi phối mọi cuộc trò chuyện không chính thức về việc rollout. Đặt tên nó trong all-hands. Mô tả rõ sự phát triển vai trò: AI xử lý gì, người làm gì AI không thể làm. Cụ thể. Mơ hồ làm nỗi sợ tệ hơn.
Đo adoption, không chỉ kết quả. Bao nhiêu người dùng thực sự đang dùng AI workflow hàng ngày? Hàng tuần? Không dùng gì? Theo dõi adoption nghiêm túc như bạn theo dõi kết quả kinh doanh. Adoption thấp giải thích kết quả kém, và sửa được nếu phát hiện sớm.
Governance ở Stage 3: từ bản nháp đến chức năng thực sự
Ở Stage 2, bạn có minimum viable policy. Ở Stage 3, AI đang chạy trong production trên nhiều use case. Yêu cầu governance mở rộng theo đó.
Chức năng phê duyệt công cụ. Có người xem xét các yêu cầu AI tool mới, áp dụng data classification framework, và cấp phê duyệt. Không phải ủy ban. Một người với quy trình và thời hạn xử lý.
Ownership sự cố. Khi sự cố AI production xảy ra (output sai, phơi lộ dữ liệu, model failure), ai chịu trách nhiệm giải quyết? Ở Stage 3, đây là vai trò có tên: AI Operations Lead hoặc tương đương. Không phải shared email list.
Review policy hàng quý. AI thay đổi nhanh. Danh sách công cụ phê duyệt từ sáu tháng trước có thể đã bao gồm các công cụ đã thay đổi điều khoản xử lý dữ liệu. Lên lịch: review hàng quý, hai giờ, danh sách công cụ phê duyệt cộng incident log.
Baseline audit trail. Với mọi Execute-capable AI workflow (AI thực hiện action trong hệ thống), bạn cần log về AI đã làm gì, khi nào, và kết quả như thế nào. Đây là yêu cầu pháp lý và compliance ở quy mô production tại hầu hết các khu vực pháp lý, và là nền tảng để xử lý sự cố. Xem Audit Trails for AI Execute Actions để biết audit trail cấp production đòi hỏi gì.
Rework Analysis: Dựa trên các pattern triển khai enterprise AI, ba quyết định hạ tầng thường bị trì hoãn đến sau sự cố production là: observability stack (nhóm phát hiện ra cần nó khi không thể chẩn đoán tại sao output suy giảm), data processing agreement với model provider (giải quyết sau khi triển khai khi legal phát hiện khoảng trống compliance), và giám sát chi phí (nổi lên khi hóa đơn bất ngờ đầu tiên đến). Cả ba đều không tốn kém để thiết lập trước production. Cả ba đều rất tốn kém để điều chỉnh sau sự cố. Production deployment checklist trong bài viết này sắp xếp đặc biệt để đảm bảo cả ba được giải quyết trước khi ra mắt.
Tính toán lại ROI ở Stage 3
Pilot chứng minh tính khả thi. Production chứng minh kinh tế học. Đây là hai câu hỏi khác nhau.
Một pilot với 20 người dùng trong 60 ngày, tiết kiệm 3 giờ mỗi người mỗi tuần, quy đổi sang năm như sau: 20 người x 3 giờ x 48 tuần = 2.880 giờ tiết kiệm. Với chi phí fully-loaded trung bình 50 USD/giờ, đó là 144.000 USD giá trị lao động hàng năm.
Nhưng thực sự tốn bao nhiêu để chạy AI trong production? Chi phí model API, thời gian nhóm AI Operations, chi phí hạ tầng, chi phí monitoring. Nếu tổng cost of ownership hàng năm là 40.000 USD, ROI ròng là 104.000 USD. Đó là business case rõ ràng.
Chạy phép tính này trước khi cam kết scale Stage 3. Và dùng con số thực, không phải giá pilot-stage của vendor. Hỏi model provider về production pricing ở volume token bạn kỳ vọng. Hỏi AI Operations hire chi phí thời gian của họ là bao nhiêu. Cộng thêm 20% cho các chi phí bạn chưa lường trước.
Bài Why AI ROI Is Hard to Prove cung cấp framework đo lường ROI đầy đủ với các chiều quan trọng: thời gian tiết kiệm, giảm chi phí, cải thiện chất lượng, và tác động doanh thu.
Ví dụ thực tế Stage 2-sang-3
Một công ty SaaS 200 người chạy AI Support Agent pilot thành công vào Q3 2025. Pilot cho thấy AI có thể giải quyết 35% support ticket đến mà không cần người tham gia, giải phóng 15 giờ mỗi tuần cho mỗi kỹ sư hỗ trợ.
Trước khi scale, họ đưa ra ba quyết định hạ tầng: chuẩn hóa trên OpenAI Enterprise, cam kết Pinecone làm vector database cho knowledge base hỗ trợ, và triển khai LangSmith cho observability.
Họ tuyển AI Operations Lead vào Q4 2025. Người này sở hữu production deployment checklist, tổ chức đào tạo người dùng, viết incident runbook, và thiết lập dashboard giám sát chi phí.
Đến Q1 2026, AI Support Agent đang trong production cho toàn bộ nhóm hỗ trợ. Song song, họ khởi động Pilot 2: AI Sales Operations assistant soạn thảo tóm tắt cuộc gọi và khuyến nghị bước tiếp theo trực tiếp trong CRM. Pilot đó đang chạy với hạ tầng của Pilot 1 làm nền móng.
Họ không chạy năm pilot song song. Họ chạy một cái tốt, cam kết hạ tầng, và dùng nền móng đó cho cái tiếp theo. Đó là Stage 2-sang-3 được thực hiện đúng.
Bước tiếp theo
Production deployment là Stage 3. Bước sang Stage 4 là một bậc độ lớn khác: AI không còn là lớp thêm vào trên workflow mà được dệt vào mô hình vận hành cốt lõi. Phần lớn các công ty mid-market chưa sẵn sàng cho Stage 4 trong hai đến ba năm nữa.
Nhưng hiểu Stage 4 đòi hỏi gì giúp bạn đầu tư đúng ở Stage 3. Bạn không chỉ scale công cụ. Bạn đang xây dựng hạ tầng và governance mà Stage 4 phụ thuộc vào. Khoản đầu tư đó tích lũy về phía trước.
Đọc: Stage 3 sang 4: Từ Scaled đến Integrated để xem các yêu cầu tổ chức và kiến trúc.
Đọc: 5 Stages of AI Maturity để thấy Stage 3 nằm ở đâu trong toàn bộ mô hình maturity.
Đọc: AI Incident Response Playbook trước lần production deployment đầu tiên. Bạn muốn có nó sẵn trước khi cần.
Xem thêm:
- The Honest Cost of AI Transformation: khoản đầu tư hạ tầng cần thiết ở Stage 3 đặt trong mô hình business case
- Sequencing AI Patterns in a Multi-Year Roadmap: cách ưu tiên use case thứ hai và thứ ba sau khi Pilot 1 thành công

Co-Founder, Rework.com
On this page
- Pilot purgatory trông như thế nào
- Crossing Test Stage 2-sang-3
- Tiêu chí thoát Stage 3
- Các quyết định hạ tầng Stage 3 đòi hỏi
- Production deployment checklist
- Scale change management: từ tình nguyện đến toàn đội
- Governance ở Stage 3: từ bản nháp đến chức năng thực sự
- Tính toán lại ROI ở Stage 3
- Ví dụ thực tế Stage 2-sang-3
- Bước tiếp theo