What are Embeddings? Teaching AI the Meaning Behind Words
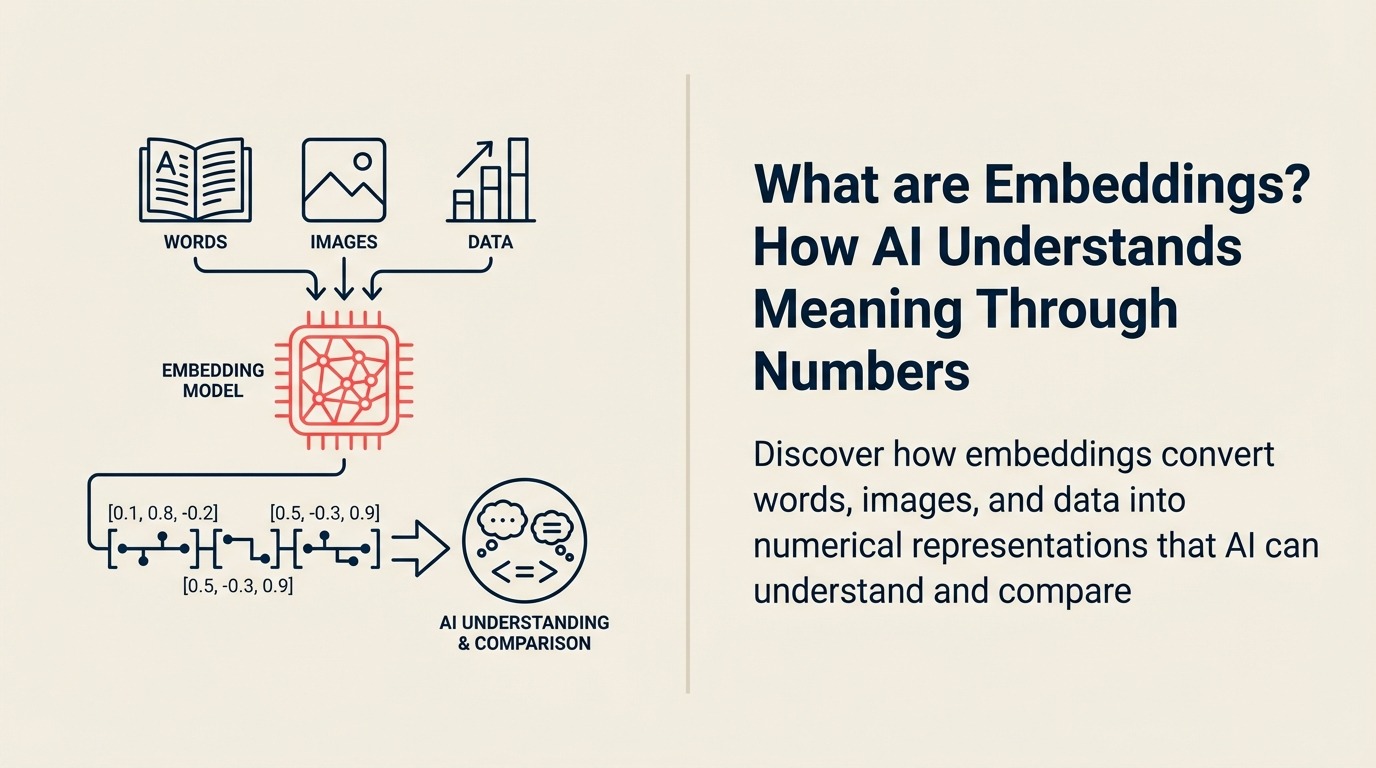
How does AI know that "car" and "automobile" mean the same thing? Or that "king" relates to "queen" like "man" to "woman"? The answer is embeddings – the mathematical magic that transforms words into numbers that capture meaning, enabling AI to understand language like humans do.
Technical Definition
Embeddings are dense numerical representations of discrete objects (like words, sentences, or images) in a continuous vector space, where similar items are mapped to nearby points. These high-dimensional vectors (typically 256-1536 numbers) encode semantic meaning and relationships.
According to Google Research, "Embeddings are one of the most important concepts in modern Natural Language Processing, allowing us to use mathematical tools to operate on words and understand relationships between them." The breakthrough came when researchers discovered that semantic relationships could be captured through vector arithmetic.
The famous example: vector("King") - vector("Man") + vector("Woman") ≈ vector("Queen") demonstrates how embeddings capture conceptual relationships mathematically.
Business Translation
For business leaders, embeddings are like GPS coordinates for meaning – they tell AI how close or far apart concepts are, enabling semantic search, personalized recommendations, and intelligent categorization at scale.
Imagine organizing your product catalog not alphabetically but by actual similarity. Embeddings do this automatically, understanding that "laptop" is closer to "notebook computer" than to "notebook paper" without explicit programming.
In practical terms, embeddings power the AI that finds similar customer support tickets, recommends related products, detects duplicate content, and understands that a search for "affordable attorneys" should also show "cheap lawyers."
How Embeddings Work
The embedding process:
• Input Processing: Text, images, or other data converted to standard format (like tokens for text)
• Neural Network Encoding: Deep learning models transform inputs into dense vectors, learning patterns from massive datasets
• Vector Representation: Each input becomes a list of numbers (e.g., [0.2, -0.5, 0.8...]) representing its position in "meaning space"
• Similarity Computation: Mathematical distance between vectors indicates semantic similarity – closer vectors mean more similar concepts
• Downstream Applications: These vectors feed into search, classification, clustering, and other AI tasks
Types of Embeddings
Different embeddings for different data:
Type 1: Word Embeddings Examples: Word2Vec, GloVe Use case: Understanding individual words Application: Spell check, autocomplete
Type 2: Sentence/Document Embeddings Examples: BERT, Sentence-BERT Use case: Capturing full context Application: Document search, summarization
Type 3: Image Embeddings Examples: ResNet, CLIP Use case: Computer vision understanding Application: Image search, product matching
Type 4: Multimodal Embeddings Examples: CLIP, ALIGN Use case: Cross-media understanding Application: Text-to-image search
Business Applications
Embeddings powering real solutions:
E-commerce Example: Amazon's product embeddings understand that customers searching for "running shoes" might also want "athletic socks" and "fitness trackers," driving 35% of purchases through embedding-based recommendations.
Customer Service Example: Zendesk uses embeddings to automatically route tickets to the right department, understanding that "can't log in" and "password not working" are similar issues, reducing response time by 40%.
Content Management Example: Netflix embeddings understand viewing preferences beyond genres, recognizing that fans of "Stranger Things" might enjoy "Dark" based on thematic similarities, increasing engagement by 25%.
The Power of Semantic Search
Embeddings revolutionize search:
Traditional Search:
- Matches exact keywords
- Misses synonyms and context
- Returns irrelevant results with matching words
Embedding-Based Search:
- Understands meaning and intent
- Finds conceptually similar content
- Works across languages naturally
Example: Searching "budget hotel Paris" also finds "affordable accommodation in French capital" without keyword matching.
Embedding Databases
Storing and searching embeddings at scale:
• Vector Databases: Specialized systems (Pinecone, Weaviate, Qdrant) optimized for similarity search across millions of embeddings
• Indexing Methods: Techniques like HNSW and IVF enable near-instant search through billions of vectors
• Hybrid Search: Combining embeddings with traditional search for best of both worlds
• Real-time Updates: Modern systems update embeddings as new content arrives
Implementation Considerations
Key factors for success:
Quality Factors:
- Choice of embedding model
- Domain-specific fine-tuning
- Embedding dimension tradeoffs
- Update frequency needs
Technical Requirements:
- Storage for high-dimensional vectors
- Computational resources for encoding
- Fast similarity search infrastructure
- Integration with existing systems
Business Metrics:
- Search relevance improvement
- Recommendation click-through rates
- Support ticket routing accuracy
- Customer satisfaction scores
Common Embedding Challenges
Pitfalls and solutions:
• Domain Mismatch: Generic embeddings fail on specialized content → Solution: Fine-tune on your industry data
• Language Barriers: Embeddings trained on English struggle with other languages → Solution: Multilingual models
• Concept Drift: Meanings change over time → Solution: Regular retraining and monitoring
• Scale Issues: Billions of embeddings slow search → Solution: Approximate nearest neighbor algorithms
Leveraging Embeddings
Your path to semantic AI:
- Start with Tokenization to understand inputs
- Explore Vector Databases for storage
- Learn about Semantic Search applications
- Understand how Retrieval-Augmented Generation (RAG) uses embeddings
- See how Large Language Models leverage embeddings
External Resources
- OpenAI Embeddings Guide - Creating and using text embeddings
- Hugging Face Sentence Transformers - Pre-trained embedding models
- Pinecone Vector Database - Production embedding search infrastructure
FAQ Section
Frequently Asked Questions about Embeddings
What are Embeddings?
Embeddings are numerical representations (vectors) of data like words or images that capture semantic meaning, where similar items have similar vectors in mathematical space.
What's the difference between embeddings and traditional encoding?
Traditional encoding uses arbitrary numbers without meaning relationships. Embeddings position similar concepts near each other in vector space, enabling semantic operations like similarity search.
What are the main types of embeddings?
Word Embeddings (individual words), Sentence/Document Embeddings (full context), Image Embeddings (visual understanding), and Multimodal Embeddings (cross-media like text-image).
What is a vector database?
A vector database is a specialized system optimized for storing and searching embeddings, enabling fast similarity searches across millions or billions of high-dimensional vectors.
Part of the AI Terms Collection. Last updated: 2026-01-11
